docs: Restructure navigation, refactor all component documentation, among many other things (#9115)
* reorg pt 1 * nav reorg pt 2 * update sidebar ad * resolve comments and combine app pages * playground and voice mode rewrite * fix link * add separate bundle pages * add new pages to sidebar * working on bundles * moving content to new bundle pages * move some sidebar items * fix build * nav labels * small edits * Working on helpers * core components work * wrapping up some more agent duplication * aligning file management * webhooks and file management * data components * address vector store and some legacy components * finish logic params * some work on processors * remove unneeded pages and tidy some llm info * progress on bundles pt 1 * bundles pt 2 * bundles pt 3 * finish looking at integrations * it is done * fix errors * coderabbit and typos * coderabbit pt 2 * resolving mcs pt 1 * separate agents and mcp * still working on some memory stuff * finish message history alignment * incorporate PR 9138 * missed a link * file management ui * align w ui pr * Apply suggestions from code review * memory edits after discussion
This commit is contained in:
parent
31d37dff75
commit
f8d8ff4599
73 changed files with 5124 additions and 5160 deletions
|
|
@ -41,7 +41,7 @@ For a prebuilt example, use the [**Simple Agent** template](/simple-agent) or tr
|
|||
If you want to use a different provider, edit the **Model Provider**, **Model Name**, and **API Key** fields accordingly.
|
||||
For more information, see [Agent component parameters](#agent-component-parameters).
|
||||
|
||||
4. Add [**Chat input** and **Chat output** components](/components-io) to your flow, and then connect them to the **Agent** component.
|
||||
4. Add [**Chat Input** and **Chat Output** components](/components-io) to your flow, and then connect them to the **Agent** component.
|
||||
|
||||
At this point, you have created a basic LLM-based chat flow that you can test in the <Icon name="Play" aria-hidden="true" /> **Playground**.
|
||||
However, this flow only chats with the LLM.
|
||||
|
|
@ -94,20 +94,23 @@ For a multi-agent example, see [Use an agent as a tool](/agents-tools#use-an-age
|
|||
|
||||
You can configure the **Agent** component to use your preferred provider and model, custom instructions, and tools.
|
||||
|
||||
:::tip
|
||||
Many optional **Agent** component input parameters are hidden by default in the visual editor.
|
||||
You can view and toggle all parameters through the <Icon name="SlidersHorizontal" aria-hidden="true"/> **Controls** in the [component's header menu](/concepts-components#component-menus).
|
||||
:::
|
||||
|
||||
### Provider and model
|
||||
|
||||
Use the **Model Provider** (`agent_llm`) and **Model Name** (`llm_model`) settings to select the model provider and LLM that you want the agent to use.
|
||||
|
||||
The **Agent** component includes many models from several popular model providers.
|
||||
To access other providers and models, set **Model Provider** to **Custom**, and then connect a [**Language Model** component](/components-models).
|
||||
To access other providers and models, set **Model Provider** to **Custom**, and then connect any [**Language Model** component](/components-models).
|
||||
|
||||
:::tip
|
||||
If you need to generate embeddings in your flow, use an [**Embedding Model** component](/components-embedding-models).
|
||||
:::
|
||||
|
||||
### Model provider API key
|
||||
|
||||
In the **API Key** field, enter a valid authentication key for your selected model provider, if you selected one of the built-in providers.
|
||||
In the **API Key** field, enter a valid authentication key for your selected model provider, if you are using a built-in provider.
|
||||
For example, to use the default OpenAI model, you must provide a valid OpenAI API key for an OpenAI account that has credits and permission to call OpenAI LLMs.
|
||||
|
||||
You can enter the key directly, but it is recommended that you follow industry best practices for storing and referencing API keys.
|
||||
|
|
@ -122,25 +125,6 @@ In the **Agent Instructions** (`system_prompt`) field, you can provide custom in
|
|||
|
||||
These instructions are applied in addition to the **Input** (`input_value`), which can be entered directly or provided through another component, such as a **Chat Input** component.
|
||||
|
||||
### Agent memory
|
||||
|
||||
Langflow Agents have built-in memory enabled by default that allows them to remember previous messages in a conversation.
|
||||
This memory acts as a rolling chat history window, ensuring the Agent can reference earlier exchanges and maintain context without requiring a separate [Message History](/components-helpers#message-history) component.
|
||||
|
||||
The Agent’s internal chat history is stored in the Langflow database, just like the [Message History](/components-helpers#message-history) helper component.
|
||||
The default storage option in Langflow is a [SQLite](https://www.sqlite.org/) database stored in your system's cache directory:
|
||||
|
||||
- **macOS Desktop**: `/Users/<username>/.langflow/data/database.db`
|
||||
- **Windows Desktop**: `C:\Users\<name>\AppData\Roaming\com.Langflow\data\langflow.db`
|
||||
- **OSS macOS/Windows/Linux/WSL (uv pip install)**: `<path_to_venv>/lib/python3.12/site-packages/langflow/langflow.db` (Python version may vary)
|
||||
- **OSS macOS/Windows/Linux/WSL (git clone)**: `<path_to_clone>/src/backend/base/langflow/langflow.db`
|
||||
|
||||
If your Langflow deployment has `LANGFLOW_DATABASE_URL` set to PostgreSQL, the Agent memory will use the PostgreSQL database.
|
||||
Each conversation is associated with a session ID, so messages are grouped and retrieved per session.
|
||||
This means your chat history is saved and can be accessed or retrieved later, even if you refresh or revisit the flow.
|
||||
|
||||
The number of stored messages can be configured in the **Number of Chat History Messages** field in the Agent component.
|
||||
|
||||
### Tools
|
||||
|
||||
Agents are most useful when they have the appropriate tools available to complete requests.
|
||||
|
|
@ -154,6 +138,20 @@ For more information, see [Configure tools for agents](/agents-tools).
|
|||
To allow agents to use tools from MCP servers, use the [**MCP Tools** component](/components-agents#mcp-connection).
|
||||
:::
|
||||
|
||||
### Agent memory
|
||||
|
||||
Langflow agents have built-in chat memory that is enabled by default.
|
||||
This memory allows them to retrieve and reference messages from previous conversations, maintaining a rolling context window for each chat session ID.
|
||||
|
||||
Chat memories are grouped by [session ID (`session_id`)](/session-id).
|
||||
It is recommended to use custom session IDs if you need to segregate chat memory for different users or applications that run the same flow.
|
||||
|
||||
By default, the **Agent** component uses your Langflow installation's storage, and it retrieves a limited number of chat messages, which you can configure with the **Number of Chat History Messages** parameter.
|
||||
|
||||
Although the **Message History** component isn't required for default chat memory, it provides more options for sorting, filtering, and limiting memories, and the **Message History** component is required to use external chat memory like Mem0.
|
||||
|
||||
For more information, see [Store chat memory](/memory#store-chat-memory) and [**Message History** component](/components-helpers#message-history).
|
||||
|
||||
### Additional parameters
|
||||
|
||||
Many optional **Agent** component input parameters are hidden by default in the visual editor.
|
||||
|
|
|
|||
50
docs/docs/Components/bundles-aiml.mdx
Normal file
50
docs/docs/Components/bundles-aiml.mdx
Normal file
|
|
@ -0,0 +1,50 @@
|
|||
---
|
||||
title: AI/ML API
|
||||
slug: /bundles-aiml
|
||||
---
|
||||
|
||||
import Icon from "@site/src/components/icon";
|
||||
|
||||
[Bundles](/components-bundle-components) contain custom components that support specific third-party integrations with Langflow.
|
||||
|
||||
This page describes the components that are available in the **AI/ML** bundle.
|
||||
|
||||
## AI/ML API text generation
|
||||
|
||||
This component creates a `ChatOpenAI` model instance using the AI/ML API.
|
||||
The output is exclusively a **Language Model** ([`LanguageModel`](/data-types#languagemodel)) that you can connect to another LLM-driven component, such as a **Smart Function** component.
|
||||
|
||||
For more information, see the [AI/ML API Langflow integration documentation](https://docs.aimlapi.com/integrations/langflow) and [**Language Model** components](/components-models).
|
||||
|
||||
### AI/ML API text generation parameters
|
||||
|
||||
Many component input parameters are hidden by default in the visual editor.
|
||||
You can toggle parameters through the <Icon name="SlidersHorizontal" aria-hidden="true"/> **Controls** in the [component's header menu](/concepts-components#component-menus).
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| max_tokens | Integer | Input parameter. The maximum number of tokens to generate. Set to 0 for unlimited tokens. Range: 0-128000. |
|
||||
| model_kwargs | Dictionary | Input parameter. Additional keyword arguments for the model. |
|
||||
| model_name | String | Input parameter. The name of the AIML model to use. Options are predefined in `AIML_CHAT_MODELS`. |
|
||||
| aiml_api_base | String | Input parameter. The base URL of the AIML API. Defaults to `https://api.aimlapi.com`. |
|
||||
| api_key | SecretString | Input parameter. The AIML API Key to use for the model. |
|
||||
| temperature | Float | Input parameter. Controls randomness in the output. Default: `0.1`. |
|
||||
|
||||
## AI/ML API Embeddings
|
||||
|
||||
The **AI/ML API Embeddings** component generates embeddings using the [AI/ML API](https://docs.aimlapi.com/api-overview/embeddings).
|
||||
|
||||
The output is [`Embeddings`](/data-types#embeddings).
|
||||
Specifically, an instance of `AIMLEmbeddingsImpl`.
|
||||
|
||||
For more information about using embedding model components in flows, see [**Embedding Model** components](/components-embedding-models).
|
||||
|
||||
### AI/ML API Embeddings parameters
|
||||
|
||||
Some **AI/ML API** component input parameters are hidden by default in the visual editor.
|
||||
You can toggle parameters through the <Icon name="SlidersHorizontal" aria-hidden="true"/> **Controls** in the [component's header menu](/concepts-components#component-menus).
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| model_name | String | Input parameter. The name of the AI/ML embedding model to use. |
|
||||
| aiml_api_key | SecretString | Input parameter. The API key required for authenticating with the AI/ML service. |
|
||||
55
docs/docs/Components/bundles-amazon.mdx
Normal file
55
docs/docs/Components/bundles-amazon.mdx
Normal file
|
|
@ -0,0 +1,55 @@
|
|||
---
|
||||
title: Amazon
|
||||
slug: /bundles-amazon
|
||||
---
|
||||
|
||||
import Icon from "@site/src/components/icon";
|
||||
|
||||
[Bundles](/components-bundle-components) contain custom components that support specific third-party integrations with Langflow.
|
||||
|
||||
This page describes the components that are available in the **Amazon** bundle.
|
||||
|
||||
## Amazon Bedrock
|
||||
|
||||
This component generates text using [Amazon Bedrock LLMs](https://docs.aws.amazon.com/bedrock).
|
||||
|
||||
It can output either a **Model Response** ([`Message`](/data-types#message)) or a **Language Model** ([`LanguageModel`](/data-types#languagemodel)).
|
||||
Specifically, the **Language Model** output is an instance of [`ChatBedrock`](https://python.langchain.com/docs/integrations/chat/bedrock/) configured according to the component's parameters.
|
||||
|
||||
Use the **Language Model** output when you want to use an Amazon Bedrock model as the LLM for another LLM-driven component, such as a **Language Model** or **Smart Function** component.
|
||||
|
||||
For more information, see [**Language Model** components](/components-models).
|
||||
|
||||
### Amazon Bedrock parameters
|
||||
|
||||
Many **Amazon Bedrock** component input parameters are hidden by default in the visual editor.
|
||||
You can toggle parameters through the <Icon name="SlidersHorizontal" aria-hidden="true"/> **Controls** in the [component's header menu](/concepts-components#component-menus).
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| model_id | String | Input parameter. The ID of the Amazon Bedrock model to use. Options include various models. |
|
||||
| aws_access_key | SecretString | Input parameter. AWS Access Key for authentication. |
|
||||
| aws_secret_key | SecretString | Input parameter. AWS Secret Key for authentication. |
|
||||
| aws_session_token | SecretString | Input parameter. The session key for your AWS account. |
|
||||
| credentials_profile_name | String | Input parameter. Name of the AWS credentials profile to use. |
|
||||
| region_name | String | Input parameter. AWS region name. Default: `us-east-1`. |
|
||||
| model_kwargs | Dictionary | Input parameter. Additional keyword arguments for the model. |
|
||||
| endpoint_url | String | Input parameter. Custom endpoint URL for the Bedrock service. |
|
||||
|
||||
## Amazon Bedrock Embeddings
|
||||
|
||||
The **Amazon Bedrock Embeddings** component is used to load embedding models from [Amazon Bedrock](https://aws.amazon.com/bedrock/).
|
||||
|
||||
For more information about using embedding model components in flows, see [**Embedding Model** components](/components-embedding-models).
|
||||
|
||||
### Amazon Bedrock Embeddings parameters
|
||||
|
||||
Some **Amazon Bedrock Embeddings** component input parameters are hidden by default in the visual editor.
|
||||
You can toggle parameters through the <Icon name="SlidersHorizontal" aria-hidden="true"/> **Controls** in the [component's header menu](/concepts-components#component-menus).
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| credentials_profile_name | String | Input parameter. The name of the AWS credentials profile in `~/.aws/credentials` or `~/.aws/config`, which has access keys or role information. |
|
||||
| model_id | String | Input parameter. The ID of the model to call, such as `amazon.titan-embed-text-v1`. This is equivalent to the `modelId` property in the `list-foundation-models` API. |
|
||||
| endpoint_url | String | Input parameter. The URL to set a specific service endpoint other than the default AWS endpoint. |
|
||||
| region_name | String | Input parameter. The AWS region to use, such as `us-west-2`. Falls back to the `AWS_DEFAULT_REGION` environment variable or region specified in `~/.aws/config` if not provided. |
|
||||
37
docs/docs/Components/bundles-anthropic.mdx
Normal file
37
docs/docs/Components/bundles-anthropic.mdx
Normal file
|
|
@ -0,0 +1,37 @@
|
|||
---
|
||||
title: Anthropic
|
||||
slug: /bundles-anthropic
|
||||
---
|
||||
|
||||
import Icon from "@site/src/components/icon";
|
||||
|
||||
[Bundles](/components-bundle-components) contain custom components that support specific third-party integrations with Langflow.
|
||||
|
||||
This page describes the components that are available in the **Anthropic** bundle.
|
||||
|
||||
For more information about Anthropic features and functionality used by Anthropic components, see the [Anthropic documentation](https://docs.anthropic.com/en/docs/intro).
|
||||
|
||||
## Anthropic text generation
|
||||
|
||||
The **Anthropic** component generates text using Anthropic Chat and Language models like Claude.
|
||||
|
||||
It can output either a **Model Response** ([`Message`](/data-types#message)) or a **Language Model** ([`LanguageModel`](/data-types#languagemodel)).
|
||||
Specifically, the **Language Model** output is an instance of [`ChatAnthropic`](https://python.langchain.com/docs/integrations/chat/anthropic/) configured according to the component's parameters.
|
||||
|
||||
Use the **Language Model** output when you want to use an Anthropic model as the LLM for another LLM-driven component, such as a **Language Model** or **Smart Function** component.
|
||||
|
||||
For more information, see [**Language Model** components](/components-models).
|
||||
|
||||
### Anthropic text generation parameters
|
||||
|
||||
Many **Anthropic** component input parameters are hidden by default in the visual editor.
|
||||
You can toggle parameters through the <Icon name="SlidersHorizontal" aria-hidden="true"/> **Controls** in the [component's header menu](/concepts-components#component-menus).
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| max_tokens | Integer | Input parameter. The maximum number of tokens to generate. Set to 0 for unlimited tokens. Default: `4096`. |
|
||||
| model | String | Input parameter. The name of the Anthropic model to use. Options include various Claude 3 models. |
|
||||
| anthropic_api_key | SecretString | Input parameter. Your Anthropic API key for authentication. |
|
||||
| temperature | Float | Input parameter. Controls randomness in the output. Default: `0.1`. |
|
||||
| anthropic_api_url | String | Input parameter. Endpoint of the Anthropic API. Defaults to `https://api.anthropic.com` if not specified (advanced). |
|
||||
| prefill | String | Input parameter. Prefill text to guide the model's response (advanced). |
|
||||
28
docs/docs/Components/bundles-arxiv.mdx
Normal file
28
docs/docs/Components/bundles-arxiv.mdx
Normal file
|
|
@ -0,0 +1,28 @@
|
|||
---
|
||||
title: arXiv
|
||||
slug: /bundles-arxiv
|
||||
---
|
||||
|
||||
import Icon from "@site/src/components/icon";
|
||||
|
||||
[Bundles](/components-bundle-components) contain custom components that support specific third-party integrations with Langflow.
|
||||
|
||||
This page describes the components that are available in the **arXiv** bundle.
|
||||
|
||||
## arXiv search
|
||||
|
||||
This component searches and retrieves papers from [arXiv.org](https://arXiv.org).
|
||||
|
||||
It returns a list of search results as a [`DataFrame`](/data-types#dataframe).
|
||||
|
||||
### arXiv search parameters
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| search_query | String | Input parameter. The search query for arXiv papers. For example, `quantum computing`. |
|
||||
| search_type | String | Input parameter. The field to search in. |
|
||||
| max_results | Integer | Input parameter. The maximum number of results to return. |
|
||||
|
||||
## See also
|
||||
|
||||
* [**Web Search** component](/components-data#web-search)
|
||||
57
docs/docs/Components/bundles-azure.mdx
Normal file
57
docs/docs/Components/bundles-azure.mdx
Normal file
|
|
@ -0,0 +1,57 @@
|
|||
---
|
||||
title: Azure
|
||||
slug: /bundles-azure
|
||||
---
|
||||
|
||||
import Icon from "@site/src/components/icon";
|
||||
|
||||
[Bundles](/components-bundle-components) contain custom components that support specific third-party integrations with Langflow.
|
||||
|
||||
This page describes the components that are available in the **Azure** bundle.
|
||||
|
||||
## Azure OpenAI
|
||||
|
||||
This component generates text using [Azure OpenAI LLMs](https://learn.microsoft.com/en-us/azure/ai-services/openai/).
|
||||
|
||||
It can output either a **Model Response** ([`Message`](/data-types#message)) or a **Language Model** ([`LanguageModel`](/data-types#languagemodel)).
|
||||
Specifically, the **Language Model** output is an instance of [`AzureChatOpenAI`](https://python.langchain.com/docs/integrations/chat/azure_chat_openai/) configured according to the component's parameters.
|
||||
|
||||
Use the **Language Model** output when you want to use an Azure OpenAI model as the LLM for another LLM-driven component, such as a **Language Model** or **Smart Function** component.
|
||||
|
||||
For more information, see [**Language Model** components](/components-models).
|
||||
|
||||
### Azure OpenAI parameters
|
||||
|
||||
Many **Azure OpenAI** component input parameters are hidden by default in the visual editor.
|
||||
You can toggle parameters through the <Icon name="SlidersHorizontal" aria-hidden="true"/> **Controls** in the [component's header menu](/concepts-components#component-menus).
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| Model Name | String | Input parameter. Specifies the name of the Azure OpenAI model to be used for text generation. |
|
||||
| Azure Endpoint | String | Input parameter. Your Azure endpoint, including the resource. |
|
||||
| Deployment Name | String | Input parameter. Specifies the name of the deployment. |
|
||||
| API Version | String | Input parameter. Specifies the version of the Azure OpenAI API to be used. |
|
||||
| API Key | SecretString | Input parameter. Your Azure OpenAI API key. |
|
||||
| Temperature | Float | Input parameter. Specifies the sampling temperature. Defaults to `0.7`. |
|
||||
| Max Tokens | Integer | Input parameter. Specifies the maximum number of tokens to generate. Defaults to `1000`. |
|
||||
| Input Value | String | Input parameter. Specifies the input text for text generation. |
|
||||
| Stream | Boolean | Input parameter. Specifies whether to stream the response from the model. Defaults to `False`. |
|
||||
|
||||
## Azure OpenAI Embeddings
|
||||
|
||||
The **Azure OpenAI Embeddings** component generates embeddings using Azure OpenAI models.
|
||||
|
||||
For more information about using embedding model components in flows, see [**Embedding Model** components](/components-embedding-models).
|
||||
|
||||
### Azure OpenAI Embeddings parameters
|
||||
|
||||
Some **Azure OpenAI Embeddings** component input parameters are hidden by default in the visual editor.
|
||||
You can toggle parameters through the <Icon name="SlidersHorizontal" aria-hidden="true"/> **Controls** in the [component's header menu](/concepts-components#component-menus).
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| Model | String | Input parameter. The name of the model to use. Default: `text-embedding-3-small`. |
|
||||
| Azure Endpoint | String | Input parameter. Your Azure endpoint, including the resource, such as `https://example-resource.azure.openai.com/`. |
|
||||
| Deployment Name | String | Input parameter. The name of the deployment. |
|
||||
| API Version | String | Input parameter. The API version to use, with options including various dates. |
|
||||
| API Key | String | Input parameter. The API key required to access the Azure OpenAI service. |
|
||||
20
docs/docs/Components/bundles-baidu.mdx
Normal file
20
docs/docs/Components/bundles-baidu.mdx
Normal file
|
|
@ -0,0 +1,20 @@
|
|||
---
|
||||
title: Baidu
|
||||
slug: /bundles-baidu
|
||||
---
|
||||
|
||||
import Icon from "@site/src/components/icon";
|
||||
|
||||
[Bundles](/components-bundle-components) contain custom components that support specific third-party integrations with Langflow.
|
||||
|
||||
This page describes the components that are available in the **Baidu** bundle.
|
||||
|
||||
## Qianfan
|
||||
|
||||
The **Qianfan** component generates text using Qianfan's language models.
|
||||
|
||||
It can output either a **Model Response** ([`Message`](/data-types#message)) or a **Language Model** ([`LanguageModel`](/data-types#languagemodel)).
|
||||
|
||||
Use the **Language Model** output when you want to use a Qianfan model as the LLM for another LLM-driven component, such as a **Language Model** or **Smart Function** component.
|
||||
|
||||
For more information, see [**Language Model** components](/components-models) and [Qianfan documentation](https://github.com/baidubce/bce-qianfan-sdk).
|
||||
33
docs/docs/Components/bundles-bing.mdx
Normal file
33
docs/docs/Components/bundles-bing.mdx
Normal file
|
|
@ -0,0 +1,33 @@
|
|||
---
|
||||
title: Bing
|
||||
slug: /bundles-bing
|
||||
---
|
||||
|
||||
import Icon from "@site/src/components/icon";
|
||||
|
||||
[Bundles](/components-bundle-components) contain custom components that support specific third-party integrations with Langflow.
|
||||
|
||||
This page describes the components that are available in the **Bing** bundle.
|
||||
|
||||
## Bing Search API
|
||||
|
||||
This component allows you to call the Bing Search API.
|
||||
|
||||
It returns a list of search results as a [`DataFrame`](/data-types#dataframe).
|
||||
|
||||
### Bing Search API parameters
|
||||
|
||||
Some **Bing Search API** component input parameters are hidden by default in the visual editor.
|
||||
You can toggle parameters through the <Icon name="SlidersHorizontal" aria-hidden="true"/> **Controls** in the [component's header menu](/concepts-components#component-menus).
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| bing_subscription_key | SecretString | Input parameter. A Bing API subscription key. |
|
||||
| input_value | String | Input parameter. The search query input. |
|
||||
| bing_search_url | String | Input parameter. A custom Bing Search URL. |
|
||||
| k | Integer | Input parameter. The number of search results to return. |
|
||||
|
||||
## See also
|
||||
|
||||
* [**Web Search** component](/components-data#web-search)
|
||||
* [**SearchApi** bundle](/bundles-searchapi)
|
||||
31
docs/docs/Components/bundles-cloudflare.mdx
Normal file
31
docs/docs/Components/bundles-cloudflare.mdx
Normal file
|
|
@ -0,0 +1,31 @@
|
|||
---
|
||||
title: Cloudflare
|
||||
slug: /bundles-cloudflare
|
||||
---
|
||||
|
||||
import Icon from "@site/src/components/icon";
|
||||
|
||||
[Bundles](/components-bundle-components) contain custom components that support specific third-party integrations with Langflow.
|
||||
|
||||
This page describes the components that are available in the **Cloudflare** bundle.
|
||||
|
||||
## Cloudflare Workers AI Embeddings
|
||||
|
||||
The **Cloudflare Workers AI Embeddings** component generates embeddings using [Cloudflare Workers AI models](https://developers.cloudflare.com/workers-ai/).
|
||||
|
||||
For more information about using embedding model components in flows, see [**Embedding Model** components](/components-embedding-models).
|
||||
|
||||
### Cloudflare Workers AI Embeddings parameters
|
||||
|
||||
Some **Cloudflare Workers AI Embeddings** component input parameters are hidden by default in the visual editor.
|
||||
You can toggle parameters through the <Icon name="SlidersHorizontal" aria-hidden="true"/> **Controls** in the [component's header menu](/concepts-components#component-menus).
|
||||
|
||||
| Name | Display Name | Info |
|
||||
|------|--------------|------|
|
||||
| account_id | Cloudflare account ID | Input parameter. Your [Cloudflare account ID](https://developers.cloudflare.com/fundamentals/setup/find-account-and-zone-ids/#find-account-id-workers-and-pages). |
|
||||
| api_token | Cloudflare API token | Input parameter. Your [Cloudflare API token](https://developers.cloudflare.com/fundamentals/api/get-started/create-token/). |
|
||||
| model_name | Model Name | Input parameter. A [supported model](https://developers.cloudflare.com/workers-ai/models/#text-embeddings) for embedding generation. |
|
||||
| strip_new_lines | Strip New Lines | Input parameter. Whether to strip new lines from the input text. |
|
||||
| batch_size | Batch Size | Input parameter. The number of texts to embed in each batch. |
|
||||
| api_base_url | Cloudflare API base URL | Input parameter. The base URL for the Cloudflare API. |
|
||||
| headers | Headers | Input parameter. Additional headers for the embedding generation API request. |
|
||||
48
docs/docs/Components/bundles-cohere.mdx
Normal file
48
docs/docs/Components/bundles-cohere.mdx
Normal file
|
|
@ -0,0 +1,48 @@
|
|||
---
|
||||
title: Cohere
|
||||
slug: /bundles-cohere
|
||||
---
|
||||
|
||||
import Icon from "@site/src/components/icon";
|
||||
|
||||
[Bundles](/components-bundle-components) contain custom components that support specific third-party integrations with Langflow.
|
||||
|
||||
This page describes the components that are available in the **Cohere** bundle.
|
||||
|
||||
For more information about Cohere features and functionality used by Cohere components, see the [Cohere documentation](https://cohere.ai/).
|
||||
|
||||
### Cohere text generation
|
||||
|
||||
This component generates text using Cohere's language models.
|
||||
|
||||
It can output either a **Model Response** ([`Message`](/data-types#message)) or a **Language Model** ([`LanguageModel`](/data-types#languagemodel)).
|
||||
|
||||
Use the **Language Model** output when you want to use a Cohere model as the LLM for another LLM-driven component, such as a **Language Model** or **Smart Function** component.
|
||||
|
||||
For more information, see [**Language Model** components](/components-models).
|
||||
|
||||
### Cohere text generation parameters
|
||||
|
||||
Many **Cohere** component input parameters are hidden by default in the visual editor.
|
||||
You can toggle parameters through the <Icon name="SlidersHorizontal" aria-hidden="true"/> **Controls** in the [component's header menu](/concepts-components#component-menus).
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| Cohere API Key | SecretString | Input parameter. Your Cohere API key. |
|
||||
| Max Tokens | Integer | Input parameter. Specifies the maximum number of tokens to generate. Defaults to `256`. |
|
||||
| Temperature | Float | Input parameter. Specifies the sampling temperature. Defaults to `0.75`. |
|
||||
| Input Value | String | Input parameter. Specifies the input text for text generation. |
|
||||
|
||||
### Cohere Embeddings
|
||||
|
||||
The **Cohere Embeddings** component is used to load embedding models from Cohere.
|
||||
|
||||
For more information about using embedding model components in flows, see [**Embedding Model** components](/components-embedding-models).
|
||||
|
||||
### Cohere Embeddings parameters
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| cohere_api_key | String | Input parameter. The API key required to authenticate with the Cohere service. |
|
||||
| model | String | Input parameter. The language model used for embedding text documents and performing queries. Default: `embed-english-v2.0`. |
|
||||
| truncate | Boolean | Input parameter. Whether to truncate the input text to fit within the model's constraints. Default: `False`. |
|
||||
203
docs/docs/Components/bundles-datastax.mdx
Normal file
203
docs/docs/Components/bundles-datastax.mdx
Normal file
|
|
@ -0,0 +1,203 @@
|
|||
---
|
||||
title: DataStax
|
||||
slug: /bundles-datastax
|
||||
---
|
||||
|
||||
import Icon from "@site/src/components/icon";
|
||||
|
||||
[Bundles](/components-bundle-components) contain custom components that support specific third-party integrations with Langflow.
|
||||
|
||||
This page describes the components that are available in the **DataStax** bundle.
|
||||
|
||||
## Astra DB Chat Memory
|
||||
|
||||
The **Astra DB Chat Memory** component retrieves and stores chat messages using an Astra DB database.
|
||||
|
||||
Chat memories are passed between memory storage components as the [`Memory`](/data-types#memory) data type.
|
||||
Specifically, the component creates an instance of `AstraDBChatMessageHistory`, which is a LangChain chat message history class that uses Astra DB for storage.
|
||||
|
||||
:::important
|
||||
The **Astra DB Chat Memory** component isn't recommended for most memory storage because memories tend to be long JSON objects or strings, often exceeding the maximum size of a document or object supported by Astra DB.
|
||||
|
||||
However, Langflow's **Agent** and **Language Model** components include built-in chat memory that is enabled by default.
|
||||
Your flows don't need an external database to store chat memory.
|
||||
:::
|
||||
|
||||
For more information about using external chat memory in flows, see the [**Message History** component](/components-helpers#message-history).
|
||||
|
||||
### Astra DB Chat Memory parameters
|
||||
|
||||
Some component input parameters are hidden by default in the visual editor.
|
||||
You can toggle parameters through the <Icon name="SlidersHorizontal" aria-hidden="true"/> **Controls** in the [component's header menu](/concepts-components#component-menus).
|
||||
|
||||
| Name | Type | Description |
|
||||
|------------------|---------------|-----------------------------------------------------------------------|
|
||||
| collection_name | String | Input parameter. The name of the Astra DB collection for storing messages. Required. |
|
||||
| token | SecretString | Input parameter. The authentication token for Astra DB access. Required. |
|
||||
| api_endpoint | SecretString | Input parameter. The API endpoint URL for the Astra DB service. Required. |
|
||||
| namespace | String | Input parameter. The optional namespace within Astra DB for the collection. |
|
||||
| session_id | MessageText | Input parameter. The unique identifier for the chat session. Uses the current session ID if not provided. |
|
||||
|
||||
## Astra DB CQL
|
||||
|
||||
The **Astra DB CQL** component allows agents to query data from CQL tables in Astra DB.
|
||||
|
||||
The output is a list of [`Data`](/data-types#data) objects containing the query results from the Astra DB CQL table. Each Data object contains the document fields specified by the projection fields. Limited by the `number_of_results` parameter.
|
||||
|
||||
### Astra DB CQL parameters
|
||||
|
||||
Some component input parameters are hidden by default in the visual editor.
|
||||
You can toggle parameters through the <Icon name="SlidersHorizontal" aria-hidden="true"/> **Controls** in the [component's header menu](/concepts-components#component-menus).
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| Tool Name | String | Input parameter. The name used to reference the tool in the agent's prompt. |
|
||||
| Tool Description | String | Input parameter. A brief description of the tool to guide the model in using it. |
|
||||
| Keyspace | String | Input parameter. The name of the keyspace. |
|
||||
| Table Name | String | Input parameter. The name of the Astra DB CQL table to query. |
|
||||
| Token | SecretString | Input parameter. The authentication token for Astra DB. |
|
||||
| API Endpoint | String | Input parameter. The Astra DB API endpoint. |
|
||||
| Projection Fields | String | Input parameter. The attributes to return, separated by commas. Default: "*". |
|
||||
| Partition Keys | Dict | Input parameter. Required parameters that the model must fill to query the tool. |
|
||||
| Clustering Keys | Dict | Input parameter. Optional parameters the model can fill to refine the query. Required parameters should be marked with an exclamation mark, for example, `!customer_id`. |
|
||||
| Static Filters | Dict | Input parameter. Attribute-value pairs used to filter query results. |
|
||||
| Limit | String | Input parameter. The number of records to return. |
|
||||
|
||||
## Astra DB Tool
|
||||
|
||||
The **Astra DB Tool** component enables searching data in Astra DB collections, including hybrid search, vector search, and regular filter-based search.
|
||||
Specialized searches require that the collection is pre-configured with the required parameters.
|
||||
|
||||
Outputs a list of [`Data`](/data-types#data) objects containing the query results from Astra DB. Each `Data` object contains the document fields specified by the projection attributes. Limited by the `number_of_results` parameter and the upper limit of the Astra DB Data API, depending on the type of search.
|
||||
|
||||
You can use the component to execute queries directly as isolated steps in a flow, or you can connect it as a [tool for an agent](/agents-tools) to allow the agent to query data from Astra DB collections as needed to respond to user queries.
|
||||
For more information, see [Use Langflow agents](/agents).
|
||||
|
||||

|
||||
|
||||
### Astra DB Tool parameters
|
||||
|
||||
The following parameters are for the **Astra DB Tool** component overall.
|
||||
|
||||
The values for **Collection Name**, **Astra DB Application Token**, and **Astra DB API Endpoint** are found in your Astra DB deployment. For more information, see the [Astra DB Serverless documentation](https://docs.datastax.com/en/astra-db-serverless/databases/create-database.html).
|
||||
|
||||
| Name | Type | Description |
|
||||
|-------------------|--------|--------|
|
||||
| Tool Name | String | Input parameter. The name used to reference the tool in the agent's prompt. |
|
||||
| Tool Description | String | Input parameter. A brief description of the tool. This helps the model decide when to use it. |
|
||||
| Keyspace Name | String | Input parameter. The name of the keyspace in Astra DB. Default: `default_keyspace` |
|
||||
| Collection Name | String | Input parameter. The name of the Astra DB collection to query. |
|
||||
| Token | SecretString | Input parameter. The authentication token for accessing Astra DB. |
|
||||
| API Endpoint | String | Input parameter. The Astra DB API endpoint. |
|
||||
| Projection Fields | String | Input parameter. Comma-separated list of attributes to return from matching documents. The default is the default projection, `*`, which returns all attributes except reserved fields like `$vector`. |
|
||||
| Tool Parameters | Dict | Input parameter. [Astra DB Data API `find` filters](https://docs.datastax.com/en/astra-db-serverless/api-reference/document-methods/find-many.html#parameters) that become tools for an agent. These Filters _may_ be used in a search, if the agent selects them. See [Define tool-specific parameters](#define-tool-specific-parameters). |
|
||||
| Static Filters | Dict | Input parameter. Attribute-value pairs used to filter query results. Equivalent to [Astra DB Data API `find` filters](https://docs.datastax.com/en/astra-db-serverless/api-reference/document-methods/find-many.html#parameters). **Static Filters** are included with _every_ query. Use **Static Filters** without semantic search to perform a regular filter search. |
|
||||
| Number of Results | Int | Input parameter. The maximum number of documents to return. |
|
||||
| Semantic Search | Boolean | Input parameter. Whether to run a similarity search by generating a vector embedding from the chat input and following the **Semantic Search Instruction**. Default: `False`. If `True`, you must attach an [**Embedding Model** component](/components-embedding-models) or have vectorize pre-enabled on your collection. |
|
||||
| Use Astra DB Vectorize | Boolean | Input parameter. Whether to use the Astra DB vectorize feature for embedding generation when running a semantic search. Default: `False`. If `True`, you must have vectorize pre-enabled on your collection. |
|
||||
| Embedding Model | Embedding | Input parameter. A port to attach an **Embedding Model** component to generate a vector from input text for semantic search. This can be used when **Semantic Search** is `True` with or without vectorize. Be sure to use a model that aligns with the dimensions of the embeddings already present in the collection. |
|
||||
| Semantic Search Instruction | String | Input parameter. The query to use for similarity search. Default: `"Find documents similar to the query."`. This instruction is used to guide the model in performing semantic search. |
|
||||
|
||||
### Define tool-specific parameters
|
||||
|
||||
:::tip
|
||||
**Tool Parameters** are small functions that you create within the **Astra DB Tool** component.
|
||||
They give the LLM pre-defined ways to interact with the data in your collection.
|
||||
|
||||
Without these filters, the LLM has no concept of the data in your collection or which attributes are important.
|
||||
|
||||
At runtime, the LLM can decide which filters are relevant to the current query.
|
||||
|
||||
Filters in **Tool Parameters** aren't always applied.
|
||||
If you want to enforce filters for _every_ query, use the **Static Filters** parameter.
|
||||
You can use both **Tool Parameters** and **Static Filters** to set some required filters and some optional filters.
|
||||
:::
|
||||
|
||||
In the **Astra DB Tool** component's **Tool Parameters** field, you can create filters to query documents in your collection.
|
||||
|
||||
When used in **Tool Mode** with an agent, these filters tell the agent which document attributes are most important, which are required in searches, and which operators to use on certain attributes.
|
||||
The filters become available as parameters that the LLM can use when calling the tool, with a better understanding of each parameter provided by the **Description** field.
|
||||
|
||||
In the **Tool Parameters** pane, click <Icon name="Plus" aria-hidden="true"/> **Add a new row**, and then edit each cell in the row.
|
||||
For example, the following filter allows an LLM to filter by unique `customer_id` values:
|
||||
|
||||
* Name: `customer_id`
|
||||
* Attribute Name: Leave empty if the attribute matches the field name in the database.
|
||||
* Description: `"The unique identifier of the customer to filter by"`.
|
||||
* Is Metadata: `False` unless the value stored in the metadata field.
|
||||
* Is Mandatory: `True` to require this filter.
|
||||
* Is Timestamp: For this example, select `False` because the value is an ID, not a timestamp.
|
||||
* Operator: `$eq` to look for an exact match.
|
||||
|
||||
The following fields are available for each row in the **Tool Parameters** pane:
|
||||
|
||||
| Parameter | Description |
|
||||
|-----------|-------------|
|
||||
| Name | The name of the parameter that is exposed to the LLM. It can be the same as the underlying field name or a more descriptive label. The LLM uses this name, along with the description, to infer what value to provide during execution. |
|
||||
| Attribute Name | When the parameter name shown to the LLM differs from the actual field or property in the database, use this setting to map the user-facing name to the correct attribute. For example, to apply a range filter to the timestamp field, define two separate parameters, such as `start_date` and `end_date`, that both reference the same timestamp attribute. |
|
||||
| Description | Provides instructions to the LLM on how the parameter should be used. Clear and specific guidance helps the LLM provide valid input. For example, if a field such as `specialty` is stored in lowercase, the description should indicate that the input must be lowercase. |
|
||||
| Is Metadata | When loading data using LangChain or Langflow, additional attributes may be stored under a metadata object. If the target attribute is stored this way, enable this option. It adjusts the query by generating a filter in the format: `{"metadata.<attribute_name>": "<value>"}` |
|
||||
| Is Timestamp | For date or time-based filters, enable this option to automatically convert values to the timestamp format that the Astrapy client expects. This ensures compatibility with the underlying API without requiring manual formatting. |
|
||||
| Operator | Defines the filtering logic applied to the attribute. You can use any valid [Data API filter operator](https://docs.datastax.com/en/astra-db-serverless/api-reference/filter-operator-collections.html). For example, to filter a time range on the timestamp attribute, use two parameters: one with the `$gt` operator for "greater than", and another with the `$lt` operator for "less than". |
|
||||
|
||||
## Cassandra Chat Memory
|
||||
|
||||
The **Cassandra Chat Memory** component retrieves and stores chat messages using an Apache Cassandra-based database, including Astra DB and Hyper-Converged Database (HCD).
|
||||
|
||||
Chat memories are passed between memory storage components as the [`Memory`](/data-types#memory) data type.
|
||||
Specifically, the component creates an instance of `CassandraChatMessageHistory`, which is a LangChain chat message history class that uses a Cassandra database for storage.
|
||||
|
||||
For more information about using external chat memory in flows, see the [**Message History** component](/components-helpers#message-history).
|
||||
|
||||
### Cassandra Chat Memory parameters
|
||||
|
||||
Some component input parameters are hidden by default in the visual editor.
|
||||
You can toggle parameters through the <Icon name="SlidersHorizontal" aria-hidden="true"/> **Controls** in the [component's header menu](/concepts-components#component-menus).
|
||||
|
||||
| Name | Type | Description |
|
||||
|----------------|---------------|-----------------------------|
|
||||
| database_ref | MessageText | Input parameter. The contact points for the Cassandra database or Astra DB database ID. Required. |
|
||||
| username | MessageText | Input parameter. The username for Cassandra. Leave empty for Astra DB. |
|
||||
| token | SecretString | Input parameter. The password for Cassandra or the token for Astra DB. Required. |
|
||||
| keyspace | MessageText | Input parameter. The keyspace in Cassandra or namespace in Astra DB. Required. |
|
||||
| table_name | MessageText | Input parameter. The name of the table or collection for storing messages. Required. |
|
||||
| session_id | MessageText | Input parameter. The unique identifier for the chat session. Optional. |
|
||||
| cluster_kwargs | Dictionary | Input parameter. Additional keyword arguments for the Cassandra cluster configuration. Optional. |
|
||||
|
||||
## DataStax assistant components
|
||||
|
||||
The following DataStax components are used to create and manage Assistants API functions in a flow:
|
||||
|
||||
* **Astra Assistant Agent**
|
||||
* **Create Assistant**
|
||||
* **Create Assistant Thread**
|
||||
* **Get Assistant Name**
|
||||
* **List Assistants**
|
||||
* **Run Assistant**
|
||||
|
||||
## DataStax environment variable components
|
||||
|
||||
The following DataStax components are used to load and retrieve environment variables in a flow:
|
||||
|
||||
* **Dotenv**
|
||||
* **Get Environment Variable**
|
||||
|
||||
## Legacy DataStax components
|
||||
|
||||
The following components are considered legacy or deprecated.
|
||||
These components are no longer being developed and can be removed in future releases.
|
||||
|
||||
Replace them with the suggested alternatives as soon as possible.
|
||||
|
||||
<details>
|
||||
<summary>Astra DB Vectorize</summary>
|
||||
|
||||
This component was deprecated in Langflow version 1.1.2.
|
||||
Replace it with the [**Astra DB** vector store component](/components-vector-stores#astra-db) as soon as possible.
|
||||
|
||||
The **Astra DB Vectorize** component was used to generate embeddings with Astra DB's vectorize feature in conjunction with an **Astra DB** vector store component.
|
||||
|
||||
The vectorize functionality is now built into the **Astra DB** vector store component.
|
||||
You no longer need a separate component for vectorize embedding generation.
|
||||
|
||||
</details>
|
||||
38
docs/docs/Components/bundles-deepseek.mdx
Normal file
38
docs/docs/Components/bundles-deepseek.mdx
Normal file
|
|
@ -0,0 +1,38 @@
|
|||
---
|
||||
title: DeepSeek
|
||||
slug: /bundles-deepseek
|
||||
---
|
||||
|
||||
import Icon from "@site/src/components/icon";
|
||||
|
||||
[Bundles](/components-bundle-components) contain custom components that support specific third-party integrations with Langflow.
|
||||
|
||||
This page describes the components that are available in the **DeepSeek** bundle.
|
||||
|
||||
For more information about DeepSeek features and functionality used by DeepSeek components, see the [DeepSeek documentation](https://api-docs.deepseek.com/).
|
||||
|
||||
## DeepSeek text generation
|
||||
|
||||
The **DeepSeek** component generates text using DeepSeek's language models.
|
||||
|
||||
It can output either a **Model Response** ([`Message`](/data-types#message)) or a **Language Model** ([`LanguageModel`](/data-types#languagemodel)).
|
||||
|
||||
Use the **Language Model** output when you want to use a DeepSeek model as the LLM for another LLM-driven component, such as a **Language Model** or **Smart Function** component.
|
||||
|
||||
For more information, see [**Language Model** components](/components-models).
|
||||
|
||||
### DeepSeek text generation parameters
|
||||
|
||||
Many **DeepSeek** component input parameters are hidden by default in the visual editor.
|
||||
You can toggle parameters through the <Icon name="SlidersHorizontal" aria-hidden="true"/> **Controls** in the [component's header menu](/concepts-components#component-menus).
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| max_tokens | Integer | Input parameter. Maximum number of tokens to generate. Set to `0` for unlimited. Range: `0-128000`. |
|
||||
| model_kwargs | Dictionary | Input parameter. Additional keyword arguments for the model. |
|
||||
| json_mode | Boolean | Input parameter. If `True`, outputs JSON regardless of passing a schema. |
|
||||
| model_name | String | Input parameter. The DeepSeek model to use. Default: `deepseek-chat`. |
|
||||
| api_base | String | Input parameter. Base URL for API requests. Default: `https://api.deepseek.com`. |
|
||||
| api_key | SecretString | Input parameter. Your DeepSeek API key for authentication. |
|
||||
| temperature | Float | Input parameter. Controls randomness in responses. Range: `[0.0, 2.0]`. Default: `1.0`. |
|
||||
| seed | Integer | Input parameter. Number initialized for random number generation. Use the same seed integer for more reproducible results, and use a different seed number for more random results. |
|
||||
32
docs/docs/Components/bundles-duckduckgo.mdx
Normal file
32
docs/docs/Components/bundles-duckduckgo.mdx
Normal file
|
|
@ -0,0 +1,32 @@
|
|||
---
|
||||
title: DuckDuckGo
|
||||
slug: /bundles-duckduckgo
|
||||
---
|
||||
|
||||
import Icon from "@site/src/components/icon";
|
||||
|
||||
[Bundles](/components-bundle-components) contain custom components that support specific third-party integrations with Langflow.
|
||||
|
||||
This page describes the components that are available in the **DuckDuckGo** bundle.
|
||||
|
||||
## DuckDuckGo Search
|
||||
|
||||
This component performs web searches using the [DuckDuckGo](https://www.duckduckgo.com) search engine with result-limiting capabilities.
|
||||
|
||||
It outputs a list of search results as a [`DataFrame`](/data-types#dataframe) with a `text` key containing the search results as a single string.
|
||||
|
||||
### DuckDuckGo Search parameters
|
||||
|
||||
Some **DuckDuckGo Search** component input parameters are hidden by default in the visual editor.
|
||||
You can toggle parameters through the <Icon name="SlidersHorizontal" aria-hidden="true"/> **Controls** in the [component's header menu](/concepts-components#component-menus).
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| input_value | String | Input parameter. The search query to execute with DuckDuckGo. |
|
||||
| max_results | Integer | Input parameter. The maximum number of search results to return. Default: 5. |
|
||||
| max_snippet_length | Integer | Input parameter. The maximum length of each result snippet. Default: 100. |
|
||||
|
||||
## See also
|
||||
|
||||
* [**Web Search** component](/components-data#web-search)
|
||||
* [**SearchApi** bundle](/bundles-searchapi)
|
||||
25
docs/docs/Components/bundles-exa.mdx
Normal file
25
docs/docs/Components/bundles-exa.mdx
Normal file
|
|
@ -0,0 +1,25 @@
|
|||
---
|
||||
title: Exa
|
||||
slug: /bundles-exa
|
||||
---
|
||||
|
||||
import Icon from "@site/src/components/icon";
|
||||
|
||||
[Bundles](/components-bundle-components) contain custom components that support specific third-party integrations with Langflow.
|
||||
|
||||
This page describes the components that are available in the **Exa** bundle.
|
||||
|
||||
## Exa Search
|
||||
|
||||
This component provides an [Exa Search](https://exa.ai/) toolkit for search and content retrieval by a [Langflow agent](/agents) or [MCP client](/mcp-client).
|
||||
|
||||
The output is exclusively [`Tools`](/data-types#tool).
|
||||
|
||||
### Exa Search parameters
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| Exa Search API Key (`metaphor_api_key`) | SecretString | Input parameter. An API key for Exa Search. |
|
||||
| Use Autoprompt (`use_autoprompt`) | Boolean | Input parameter. Whether to use the autoprompt feature. Default: true. |
|
||||
| Search Number of Results (`search_num_results`) | Integer | Input parameter. The number of results to return for search. Default: 5. |
|
||||
| Similar Number of Results (`similar_num_results`) | Integer | Input parameter. The number of similar results to return. Default: 5. |
|
||||
33
docs/docs/Components/bundles-glean.mdx
Normal file
33
docs/docs/Components/bundles-glean.mdx
Normal file
|
|
@ -0,0 +1,33 @@
|
|||
---
|
||||
title: Glean
|
||||
slug: /bundles-glean
|
||||
---
|
||||
|
||||
import Icon from "@site/src/components/icon";
|
||||
|
||||
[Bundles](/components-bundle-components) contain custom components that support specific third-party integrations with Langflow.
|
||||
|
||||
This page describes the components that are available in the **Glean** bundle.
|
||||
|
||||
## Glean Search API
|
||||
|
||||
This component allows you to call the Glean Search API.
|
||||
|
||||
It returns a list of search results as a [`DataFrame`](/data-types#dataframe).
|
||||
|
||||
### Glean Search API parameters
|
||||
|
||||
Some **Glean Search API** component input parameters are hidden by default in the visual editor.
|
||||
You can toggle parameters through the <Icon name="SlidersHorizontal" aria-hidden="true"/> **Controls** in the [component's header menu](/concepts-components#component-menus).
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| glean_api_url | String | Input parameter. The URL of the Glean API. |
|
||||
| glean_access_token | SecretString | Input parameter. An access token for Glean API authentication. |
|
||||
| query | String | Input parameter. The search query input. |
|
||||
| page_size | Integer | Input parameter. The number of results per page. Default: 10. |
|
||||
| request_options | Dict | Input parameter. Additional options for the API request. |
|
||||
|
||||
## See also
|
||||
|
||||
* [**Web Search** component](/components-data#web-search)
|
||||
145
docs/docs/Components/bundles-google.mdx
Normal file
145
docs/docs/Components/bundles-google.mdx
Normal file
|
|
@ -0,0 +1,145 @@
|
|||
---
|
||||
title: Google components
|
||||
slug: /bundles-google
|
||||
---
|
||||
|
||||
import Icon from "@site/src/components/icon";
|
||||
|
||||
[Bundles](/components-bundle-components) contain custom components that support specific third-party integrations with Langflow.
|
||||
|
||||
This page describes the components that are available in the **Google** bundle.
|
||||
|
||||
## BigQuery
|
||||
|
||||
See [**BigQuery** component](/integrations-google-big-query).
|
||||
|
||||
## Google Generative AI
|
||||
|
||||
This component generates text using [Google Generative AI models](https://cloud.google.com/vertex-ai/docs/).
|
||||
|
||||
### Google Generative AI parameters
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| Google API Key | SecretString | Input parameter. Your Google API key to use for the Google Generative AI. |
|
||||
| Model | String | Input parameter. The name of the model to use, such as `"gemini-pro"`. |
|
||||
| Max Output Tokens | Integer | Input parameter. The maximum number of tokens to generate. |
|
||||
| Temperature | Float | Input parameter. Run inference with this temperature. |
|
||||
| Top K | Integer | Input parameter. Consider the set of top K most probable tokens. |
|
||||
| Top P | Float | Input parameter. The maximum cumulative probability of tokens to consider when sampling. |
|
||||
| N | Integer | Input parameter. Number of chat completions to generate for each prompt. |
|
||||
| model | LanguageModel | Output parameter. An instance of ChatGoogleGenerativeAI configured with the specified parameters. |
|
||||
|
||||
## Google Generative AI Embeddings
|
||||
|
||||
The **Google Generative AI Embeddings** component connects to Google's generative AI embedding service using the GoogleGenerativeAIEmbeddings class from the `langchain-google-genai` package.
|
||||
|
||||
For more information about using embedding model components in flows, see [**Embedding Model** components](/components-embedding-models).
|
||||
|
||||
### Google Generative AI Embeddings parameters
|
||||
|
||||
| Name | Display Name | Info |
|
||||
|------|--------------|------|
|
||||
| api_key | API Key | Input parameter. The secret API key for accessing Google's generative AI service. Required. |
|
||||
| model_name | Model Name | Input parameter. The name of the embedding model to use. Default: "models/text-embedding-004". |
|
||||
| embeddings | Embeddings | Output parameter. The built GoogleGenerativeAIEmbeddings object. |
|
||||
|
||||
## Google Search API
|
||||
|
||||
This component allows you to call the Google Search API.
|
||||
|
||||
### Google Search API parameters
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| google_api_key | SecretString | Input parameter. A Google API key for authentication. |
|
||||
| google_cse_id | SecretString | Input parameter. A Google Custom Search Engine ID. |
|
||||
| input_value | String | Input parameter. The search query input. |
|
||||
| k | Integer | Input parameter. The number of search results to return. |
|
||||
| results | List[Data] | Output parameter. A list of search results. |
|
||||
| tool | Tool | Output parameter. A Google Search tool for use in LangChain. |
|
||||
|
||||
## Serper Google Search API
|
||||
|
||||
This component allows you to call the Serper.dev Google Search API.
|
||||
|
||||
### Google Serper API parameters
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| serper_api_key | SecretString | Input parameter. An API key for Serper.dev authentication. |
|
||||
| input_value | String | Input parameter. The search query input. |
|
||||
| k | Integer | Input parameter. The number of search results to return. |
|
||||
| results | List[Data] | Output parameter. A list of search results. |
|
||||
| tool | Tool | Output parameter. A Serper Google Search tool for use in LangChain. |
|
||||
|
||||
## Google Vertex AI
|
||||
|
||||
For information about Vertex AI components, see the [**Vertex AI** bundle](/bundles-vertexai).
|
||||
|
||||
## Legacy Google components
|
||||
|
||||
The following Google components are considered legacy components.
|
||||
You can still use them in your flows, but they are no longer supported and can be removed in future releases.
|
||||
|
||||
As an alternative to these components, you can use [Composio components](/integrations-composio) to connect your flows to Google services.
|
||||
|
||||
<details>
|
||||
<summary>Google OAuth Token</summary>
|
||||
|
||||
The **Google OAuth Token** component was deprecated in Langflow 1.4.0.
|
||||
|
||||
To connect your flows to Google OAuth services, use [Composio components](/integrations-composio).
|
||||
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>Gmail Loader</summary>
|
||||
|
||||
This component loads emails from Gmail using provided credentials and filters.
|
||||
|
||||
| Input | Type | Description |
|
||||
| ----------- | ---------------- | ------------------------------------------------------------------------------------ |
|
||||
| json_string | SecretStrInput | Input parameter. A JSON string containing OAuth 2.0 access token information for service account access. For information about creating a service account JSON, see [Service Account JSON](https://developers.google.com/identity/protocols/oauth2/service-account). |
|
||||
| label_ids | MessageTextInput | Input parameter. A comma-separated list of label IDs to filter emails. |
|
||||
| max_results | MessageTextInput | Input parameter. The maximum number of emails to load. |
|
||||
| data | Data | Output parameter.The loaded email data. |
|
||||
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>Google Calendar Loader</summary>
|
||||
|
||||
This component accepts the following parameters:
|
||||
|
||||
| Input | Type | Description |
|
||||
| ----------- | ---------------- | ------------------------------------------------------------------------------------ |
|
||||
| json_string | SecretStrInput | Input parameter. A JSON string containing OAuth 2.0 access token information for service account access. For information about creating a service account JSON, see [Service Account JSON](https://developers.google.com/identity/protocols/oauth2/service-account). |
|
||||
| document_id | MessageTextInput | Input parameter. A single Google Drive document ID. |
|
||||
| docs | Data | Output parameter. The loaded document data. |
|
||||
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>Google Drive Search</summary>
|
||||
|
||||
This component searches Google Drive files using provided credentials and query parameters.
|
||||
|
||||
| Input | Type | Description |
|
||||
| -------------- | ---------------- | ------------------------------------------------------------------------------------ |
|
||||
| token_string | SecretStrInput | Input parameter. A JSON string containing OAuth 2.0 access token information for service account access. For information about creating a service account JSON, see [Service Account JSON](https://developers.google.com/identity/protocols/oauth2/service-account). |
|
||||
| query_item | DropdownInput | Input parameter. The field to query. |
|
||||
| valid_operator | DropdownInput | Input parameter. The operator to use in the query. |
|
||||
| search_term | MessageTextInput | Input parameter. The value to search for in the specified query item. |
|
||||
| query_string | MessageTextInput | Input parameter. The query string used for searching. |
|
||||
| doc_urls | List[str] | Output parameter. The URLs of the found documents. |
|
||||
| doc_ids | List[str] | Output parameter. The IDs of the found documents. |
|
||||
| doc_titles | List[str] | Output parameter. The titles of the found documents. |
|
||||
| Data | Data | Output parameter. The document titles and URLs in a structured format. |
|
||||
|
||||
</details>
|
||||
|
||||
## See also
|
||||
|
||||
- [Composio bundle](/integrations-composio)
|
||||
- [Vertex AI bundle](/bundles-vertexai)
|
||||
37
docs/docs/Components/bundles-groq.mdx
Normal file
37
docs/docs/Components/bundles-groq.mdx
Normal file
|
|
@ -0,0 +1,37 @@
|
|||
---
|
||||
title: Groq
|
||||
slug: /bundles-groq
|
||||
---
|
||||
|
||||
import Icon from "@site/src/components/icon";
|
||||
|
||||
[Bundles](/components-bundle-components) contain custom components that support specific third-party integrations with Langflow.
|
||||
|
||||
This page describes the components that are available in the **Groq** bundle.
|
||||
|
||||
For more information, see the [Groq documentation](https://groq.com/).
|
||||
|
||||
## Groq text generation
|
||||
|
||||
This component generates text using Groq's language models.
|
||||
|
||||
It can output either a **Model Response** ([`Message`](/data-types#message)) or a **Language Model** ([`LanguageModel`](/data-types#languagemodel)).
|
||||
Specifically, the **Language Model** output is an instance of [`ChatGroq`](https://python.langchain.com/docs/integrations/chat/groq/) configured according to the component's parameters.
|
||||
|
||||
Use the **Language Model** output when you want to use a Groq model as the LLM for another LLM-driven component, such as a **Language Model** or **Smart Function** component.
|
||||
|
||||
For more information, see [**Language Model** components](/components-models).
|
||||
|
||||

|
||||
|
||||
### Groq text generation parameters
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| groq_api_key | SecretString | Your Groq API key. |
|
||||
| groq_api_base | String | Base URL path for API requests. Default: `https://api.groq.com`. |
|
||||
| max_tokens | Integer | The maximum number of tokens to generate. |
|
||||
| temperature | Float | Controls randomness in the output. Range: `[0.0, 1.0]`. Default: `0.1`. |
|
||||
| n | Integer | Number of chat completions to generate for each prompt. |
|
||||
| model_name | String | The name of the Groq model to use. Options are dynamically fetched from the Groq API after entering your API key and URL. To refresh your list of models, click <Icon name="RefreshCw" aria-hidden="true"/> **Refresh**. |
|
||||
| tool_mode_enabled | Boolean | If enabled, the component only displays models that work with tools. |
|
||||
78
docs/docs/Components/bundles-huggingface.mdx
Normal file
78
docs/docs/Components/bundles-huggingface.mdx
Normal file
|
|
@ -0,0 +1,78 @@
|
|||
---
|
||||
title: Hugging Face
|
||||
slug: /bundles-huggingface
|
||||
---
|
||||
|
||||
import Icon from "@site/src/components/icon";
|
||||
|
||||
[Bundles](/components-bundle-components) contain custom components that support specific third-party integrations with Langflow.
|
||||
|
||||
The components in the **Hugging Face** bundle require access to Hugging Face APIs.
|
||||
|
||||
For more information about Hugging Face features and functionality used by Hugging Face components, see the [Hugging Face documentation](https://huggingface.co/docs).
|
||||
|
||||
## Hugging Face text generation
|
||||
|
||||
The **Hugging Face** component generates text using a specified model by sending requests to the Hugging Face API, which is a hosted inference API for models hosted on Hugging Face.
|
||||
Authentication is required.
|
||||
|
||||
This component can output either a **Model Response** ([`Message`](/data-types#message)) or a **Language Model** ([`LanguageModel`](/data-types#languagemodel)).
|
||||
Specifically, the **Language Model** output is an instance of [`HuggingFaceHub`](https://python.langchain.com/docs/integrations/providers/huggingface/) configured according to the component's parameters.
|
||||
|
||||
Use the **Language Model** output when you want to use a Hugging Face model as the LLM for another LLM-driven component, such as a **Language Model** or **Smart Function** component.
|
||||
|
||||
For more information, see [**Language Model** components](/components-models).
|
||||
|
||||
### Hugging Face text generation parameters
|
||||
|
||||
Many **Hugging Face** component input parameters are hidden by default in the visual editor.
|
||||
You can toggle parameters through the <Icon name="SlidersHorizontal" aria-hidden="true"/> **Controls** in the [component's header menu](/concepts-components#component-menus).
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| model_id | String | Input parameter. The model ID from Hugging Face Hub. For example, "gpt2", "facebook/bart-large". |
|
||||
| huggingfacehub_api_token | SecretString | Input parameter. Your [Hugging Face API token](https://huggingface.co/docs/hub/security-tokens) for authentication. |
|
||||
| temperature | Float | Input parameter. Controls randomness in the output. Range: [0.0, 1.0]. Default: 0.7. |
|
||||
| max_new_tokens | Integer | Input parameter. Maximum number of tokens to generate. Default: 512. |
|
||||
| top_p | Float | Input parameter. Nucleus sampling parameter. Range: [0.0, 1.0]. Default: 0.95. |
|
||||
| top_k | Integer | Input parameter. Top-k sampling parameter. Default: 50. |
|
||||
| model_kwargs | Dictionary | Input parameter. Additional keyword arguments to pass to the model. |
|
||||
|
||||
## Hugging Face Embeddings Inference
|
||||
|
||||
Use the **Hugging Face Embeddings Inference** component to create embeddings with Hugging Face's hosted models or with your own locally hosted models.
|
||||
|
||||
The component generates embeddings using [Hugging Face Inference API models](https://huggingface.co/models).
|
||||
Authentication is required when not using a local model.
|
||||
|
||||
For more information about using embedding model components in flows, see [**Embedding Model** components](/components-embedding-models) and [Use a local Hugging Face embeddings model](#local-hugging-face-model).
|
||||
|
||||
### Hugging Face Embeddings Inference parameters
|
||||
|
||||
| Name | Display Name | Info |
|
||||
|------|--------------|------|
|
||||
| API Key | API Key | Input parameter. Your [Hugging Face API token](https://huggingface.co/docs/hub/security-tokens) for accessing the Hugging Face Inference API, if required. Local inference models do not require an API key. |
|
||||
| API URL | API URL | Input parameter. The URL of the Hugging Face Inference API. |
|
||||
| Model Name | Model Name | Input parameter. The name of the model to use for embeddings. |
|
||||
|
||||
### Use a local Hugging Face embeddings model {#local-hugging-face-model}
|
||||
|
||||
To connect the local Hugging Face model to the **Hugging Face Embeddings Inference** component and use it in a flow, follow these steps:
|
||||
|
||||
1. Run a [local Hugging Face embeddings inference](https://huggingface.co/docs/text-embeddings-inference/local_cpu).
|
||||
|
||||
2. For this example, create a flow from the [**Vector Store RAG** template](/vector-store-rag).
|
||||
|
||||
3. Replace the two **OpenAI Embeddings** components with **Hugging Face Embeddings Inference** components.
|
||||
|
||||
Make sure to reconnect the **Embedding Model** ports from each embedding model component to its corresponding **Astra DB** vector store component.
|
||||
|
||||
4. Configure the **Astra DB** vector store components to connect to your Astra organization, or replace both **Astra DB** vector store components with other [vector store components](/components-vector-stores).
|
||||
|
||||
5. Connect each **Hugging Face Embeddings Inference** component to your local inference model:
|
||||
|
||||
* **Inference Endpoint**: Enter the URL of your local inference model.
|
||||
* **API Key**: Can be empty for local inference.
|
||||
* **Model Name**: Enter the name of your local inference model if it isn't automatically detected.
|
||||
|
||||
6. To test the flow, click **Playground**, and then enter some text to generate an embedding.
|
||||
89
docs/docs/Components/bundles-ibm.mdx
Normal file
89
docs/docs/Components/bundles-ibm.mdx
Normal file
|
|
@ -0,0 +1,89 @@
|
|||
---
|
||||
title: IBM
|
||||
slug: /bundles-ibm
|
||||
---
|
||||
|
||||
import Icon from "@site/src/components/icon";
|
||||
|
||||
[Bundles](/components-bundle-components) contain custom components that support specific third-party integrations with Langflow.
|
||||
|
||||
**IBM** bundle provides access to IBM watsonx.ai models for text and embedding generation.
|
||||
These components require an IBM watsonx.ai deployment and watsonx API credentials.
|
||||
|
||||
## IBM watsonx.ai
|
||||
|
||||
The **IBM watsonx.ai** component generates text using [supported foundation models](https://dataplatform.cloud.ibm.com/docs/content/wsj/analyze-data/fm-models.html?context=wx) in [IBM watsonx.ai](https://www.ibm.com/products/watsonx-ai).
|
||||
|
||||
You can use this component anywhere you need a language model in a flow.
|
||||
|
||||

|
||||
|
||||
### IBM watsonx.ai parameters {#ibm-watsonxai-parameters}
|
||||
|
||||
Many **IBM watsonx.ai** component input parameters are hidden by default in the visual editor.
|
||||
You can toggle parameters through the <Icon name="SlidersHorizontal" aria-hidden="true"/> **Controls** in the [component's header menu](/concepts-components#component-menus).
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| url | String | Input parameter. The [watsonx API base URL](https://cloud.ibm.com/apidocs/watsonx-ai#endpoint-url) for your deployment and region. |
|
||||
| project_id | String | Input parameter. Your [watsonx Project ID](https://www.ibm.com/docs/en/watsonx/saas?topic=projects). |
|
||||
| api_key | SecretString | Input parameter. A [watsonx API key](https://www.ibm.com/docs/en/watsonx/saas?topic=administration-managing-user-api-key) to authenticate watsonx API access to the specified watsonx.ai deployment and model. |
|
||||
| model_name | String | Input parameter. The name of the watsonx model to use. Options are dynamically fetched from the API. |
|
||||
| max_tokens | Integer | Input parameter. The maximum number of tokens to generate. Default: `1000`. |
|
||||
| stop_sequence | String | Input parameter. The sequence where generation should stop. |
|
||||
| temperature | Float | Input parameter. Controls randomness in the output. Default: `0.1`. |
|
||||
| top_p | Float | Input parameter. Controls nucleus sampling, which limits the model to tokens whose probability is below the `top_p` value. Range: Default: `0.9`. |
|
||||
| frequency_penalty | Float | Input parameter. Controls frequency penalty. A positive value decreases the probability of repeating tokens, and a negative value increases the probability. Range: Default: `0.5`. |
|
||||
| presence_penalty | Float | Input parameter. Controls presence penalty. A positive value increases the likelihood of new topics being introduced. Default: `0.3`. |
|
||||
| seed | Integer | Input parameter. A random seed for the model. Default: `8`. |
|
||||
| logprobs | Boolean | Input parameter. Whether to return log probabilities of output tokens or not. Default: `True`. |
|
||||
| top_logprobs | Integer | Input parameter. The number of most likely tokens to return at each position. Default: `3`. |
|
||||
| logit_bias | String | Input parameter. A JSON string of token IDs to bias or suppress. |
|
||||
|
||||
### IBM watsonx.ai output
|
||||
|
||||
The **IBM watsonx.ai** component can output either a **Model Response** ([`Message`](/data-types#message)) or a **Language Model** ([`LanguageModel`](/data-types#languagemodel)).
|
||||
|
||||
Use the **Language Model** output when you want to use an IBM watsonx.ai model as the LLM for another LLM-driven component, such as a **Language Model** or **Smart Function** component.
|
||||
For more information, see [**Language Model** components](/components-models).
|
||||
|
||||
The `LanguageModel` output from the **IBM watsonx.ai** component is an instance of [ChatWatsonx](https://python.langchain.com/docs/integrations/chat/ibm_watsonx/) configured according to the [component's parameters](#ibm-watsonxai-parameters).
|
||||
|
||||
## IBM watsonx.ai Embeddings
|
||||
|
||||
The **IBM watsonx.ai Embeddings** component uses the [supported foundation models](https://dataplatform.cloud.ibm.com/docs/content/wsj/analyze-data/fm-models.html?context=wx) in [IBM watsonx.ai](https://www.ibm.com/products/watsonx-ai) for embedding generation.
|
||||
|
||||
The output is [`Embeddings`](/data-types#embeddings) generated with [`WatsonxEmbeddings`](https://python.langchain.com/docs/integrations/text_embedding/ibm_watsonx/).
|
||||
|
||||
For more information about using embedding model components in flows, see [**Embedding Model** components](/components-embedding-models).
|
||||
|
||||

|
||||
|
||||
### IBM watsonx.ai Embeddings parameters
|
||||
|
||||
Some **IBM watsonx.ai Embeddings** component input parameters are hidden by default in the visual editor.
|
||||
You can toggle parameters through the <Icon name="SlidersHorizontal" aria-hidden="true"/> **Controls** in the [component's header menu](/concepts-components#component-menus).
|
||||
|
||||
| Name | Display Name | Info |
|
||||
|------|--------------|------|
|
||||
| url | watsonx API Endpoint | Input parameter. The [watsonx API base URL](https://cloud.ibm.com/apidocs/watsonx-ai#endpoint-url) for your deployment and region. |
|
||||
| project_id | watsonx project id | Input parameter. Your [watsonx Project ID](https://www.ibm.com/docs/en/watsonx/saas?topic=projects). |
|
||||
| api_key | API Key | Input parameter. A [watsonx API key](https://www.ibm.com/docs/en/watsonx/saas?topic=administration-managing-user-api-key) to authenticate watsonx API access to the specified watsonx.ai deployment and model. |
|
||||
| model_name | Model Name | Input parameter. The name of the embedding model to use. Supports [default embedding models](#default-embedding-models) and automatically updates after connecting to your watsonx.ai deployment. |
|
||||
| truncate_input_tokens | Truncate Input Tokens | Input parameter. The maximum number of tokens to process. Default: `200`. |
|
||||
| input_text | Include the original text in the output | Input parameter. Determines if the original text is included in the output. Default: `True`. |
|
||||
|
||||
### Default embedding models
|
||||
|
||||
By default, the **IBM watsonx.ai Embeddings** component supports the following default models:
|
||||
|
||||
- `sentence-transformers/all-minilm-l12-v2`: 384-dimensional embeddings
|
||||
- `ibm/slate-125m-english-rtrvr-v2`: 768-dimensional embeddings
|
||||
- `ibm/slate-30m-english-rtrvr-v2`: 768-dimensional embeddings
|
||||
- `intfloat/multilingual-e5-large`: 1024-dimensional embeddings
|
||||
|
||||
After entering your API endpoint and credentials, the component automatically fetches the list of available models from your watsonx.ai deployment.
|
||||
|
||||
## See also
|
||||
|
||||
* [IBM documentation](https://cloud.ibm.com/docs)
|
||||
38
docs/docs/Components/bundles-icosacomputing.mdx
Normal file
38
docs/docs/Components/bundles-icosacomputing.mdx
Normal file
|
|
@ -0,0 +1,38 @@
|
|||
---
|
||||
title: Icosa Computing
|
||||
slug: /bundles-icosacomputing
|
||||
---
|
||||
|
||||
import Icon from "@site/src/components/icon";
|
||||
|
||||
[Bundles](/components-bundle-components) contain custom components that support specific third-party integrations with Langflow.
|
||||
|
||||
The **Icosa Computing** components require access to Icosa Computing services.
|
||||
For more information and to request access, see the [Icosa Computing site](https://www.icosacomputing.com/).
|
||||
|
||||
## Combinatorial Reasoner
|
||||
|
||||
The **Combinatorial Reasoner** component runs Icosa's Combinatorial Reasoning (CR) pipeline on an input to create an optimized prompt with embedded reasons.
|
||||
|
||||
### Combinatorial Reasoner parameters
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| prompt | String | Input parameter. The input to run CR on. |
|
||||
| openai_api_key | SecretString | Input parameter. An OpenAI API key for authentication to OpenAI, which is used for reason generation. |
|
||||
| model_name | String | Input parameter. The OpenAI LLM to use for reason generation. |
|
||||
| username | String | Input parameter. A username for authentication to the Icosa API. |
|
||||
| password | SecretString | Input parameter. A password for authentication to the Icosa API. |
|
||||
|
||||
### Combinatorial Reasoner outputs
|
||||
|
||||
The **Combinatorial Reasoner** component outputs one of the following:
|
||||
|
||||
* **Optimized Prompt (`optimized_prompt`)**: A [`Message`](/data-types#message) object containing the optimized prompt with embedded reasons.
|
||||
* **Selected Reasons (`reasons`)**: A [`Data`](/data-types#data) object containing a list of strings where each string is a reason that was selected and embedded in the optimized prompt.
|
||||
|
||||
You can toggle the output type near the component's output port.
|
||||
|
||||
## See also
|
||||
|
||||
* [**Prompt Template** component](/components-prompts)
|
||||
223
docs/docs/Components/bundles-langchain.mdx
Normal file
223
docs/docs/Components/bundles-langchain.mdx
Normal file
|
|
@ -0,0 +1,223 @@
|
|||
---
|
||||
title: LangChain
|
||||
slug: /bundles-langchain
|
||||
---
|
||||
|
||||
import Icon from "@site/src/components/icon";
|
||||
|
||||
[Bundles](/components-bundle-components) contain custom components that support specific third-party integrations with Langflow.
|
||||
|
||||
This page describes the components that are available in the **LangChain** bundle.
|
||||
|
||||
## CSV Agent
|
||||
|
||||
This component is based on the [**Agent** core component](/agents).
|
||||
|
||||
This component creates a CSV agent from a CSV file and LLM.
|
||||
For more information, see the [LangChain CSV agent documentation](https://python.langchain.com/api_reference/experimental/agents/langchain_experimental.agents.agent_toolkits.csv.base.create_csv_agent.html).
|
||||
|
||||
### CSV Agent parameters
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| llm | LanguageModel | Input parameter. The language model to use for the agent. |
|
||||
| path | File | Input parameter. The path to the CSV file. |
|
||||
| agent_type | String | Input parameter. The type of agent to create. |
|
||||
| agent | AgentExecutor | Output parameter. The CSV agent instance. |
|
||||
|
||||
## OpenAI Tools Agent
|
||||
|
||||
This component is based on the [**Agent** core component](/agents).
|
||||
|
||||
This component creates an OpenAI Tools Agent.
|
||||
For more information, see the [LangChain OpenAI agent documentation](https://api.python.langchain.com/en/latest/agents/langchain.agents.openai_functions_agent.base.create_openai_functions_agent.html).
|
||||
|
||||
### OpenAI Tools Agent parameters
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| llm | LanguageModel | Input parameter. The language model to use. |
|
||||
| tools | List of Tools | Input parameter. The tools to give the agent access to. |
|
||||
| system_prompt | String | Input parameter. The system prompt to provide context to the agent. |
|
||||
| input_value | String | Input parameter. The user's input to the agent. |
|
||||
| memory | Memory | Input parameter. The memory for the agent to use for context persistence. |
|
||||
| max_iterations | Integer | Input parameter. The maximum number of iterations to allow the agent to execute. |
|
||||
| verbose | Boolean | Input parameter. This determines whether to print out the agent's intermediate steps. |
|
||||
| handle_parsing_errors | Boolean | Input parameter. This determines whether to handle parsing errors in the agent. |
|
||||
| agent | AgentExecutor | Output parameter. The OpenAI Tools agent instance. |
|
||||
| output | String | Output parameter. The output from executing the agent on the input. |
|
||||
|
||||
## OpenAPI Agent
|
||||
|
||||
This component is based on the [**Agent** core component](/agents).
|
||||
|
||||
This component creates an agent for interacting with OpenAPI services.
|
||||
For more information, see the [LangChain OpenAPI toolkit documentation](https://python.langchain.com/docs/integrations/tools/openapi/).
|
||||
|
||||
### OpenAPI Agent parameters
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| llm | LanguageModel | Input parameter. The language model to use. |
|
||||
| openapi_spec | String | Input parameter. The OpenAPI specification for the service. |
|
||||
| base_url | String | Input parameter. The base URL for the API. |
|
||||
| headers | Dict | Input parameter. The optional headers for API requests. |
|
||||
| agent_executor_kwargs | Dict | Input parameter. The optional parameters for the agent executor. |
|
||||
| agent | AgentExecutor | Output parameter.The OpenAPI agent instance. |
|
||||
|
||||
## Prompt Hub
|
||||
|
||||
This component fetches prompts from the [LangChain Hub](https://docs.smith.langchain.com/old/category/prompt-hub).
|
||||
|
||||
Like the [**Prompt Template** core component](/components-prompts), additional fields are added to the component for each variable in the prompt.
|
||||
For example, the default prompt `efriis/my-first-prompt` adds fields for `profession` and `question`.
|
||||
|
||||
### Prompt Hub parameters
|
||||
|
||||
| Name | Display Name | Description |
|
||||
|---------------------|---------------------------|------------------------------------------|
|
||||
| langchain_api_key | Your LangChain API Key | Input parameter. The LangChain API Key to use. |
|
||||
| langchain_hub_prompt| LangChain Hub Prompt | Input parameter. The LangChain Hub prompt to use. |
|
||||
| prompt | Build Prompt | Output parameter. The built prompt message returned by the `build_prompt` method. |
|
||||
|
||||
## SQL Agent
|
||||
|
||||
This component is based on the [**Agent** core component](/agents).
|
||||
|
||||
This component creates an agent for interacting with SQL databases.
|
||||
For more information, see the [LangChain SQL agent documentation](https://python.langchain.com/docs/tutorials/sql_qa/).
|
||||
|
||||
### SQL Agent parameters
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| llm | LanguageModel | Input parameter. The language model to use. |
|
||||
| database | Database | Input parameter. The SQL database connection. |
|
||||
| top_k | Integer | Input parameter. The number of results to return from a SELECT query. |
|
||||
| use_tools | Boolean | Input parameter. This determines whether to use tools for query execution. |
|
||||
| return_intermediate_steps | Boolean | Input parameter. This determines whether to return the agent's intermediate steps. |
|
||||
| max_iterations | Integer | Input parameter. The maximum number of iterations to run the agent. |
|
||||
| max_execution_time | Integer | Input parameter. The maximum execution time in seconds. |
|
||||
| early_stopping_method | String | Input parameter. The method to use for early stopping. |
|
||||
| verbose | Boolean | Input parameter. This determines whether to print the agent's thoughts. |
|
||||
| agent | AgentExecutor | Output parameter. The SQL agent instance. |
|
||||
|
||||
## SQL Database
|
||||
|
||||
The LangChain **SQL Database** component establishes a connection to an SQL database.
|
||||
|
||||
This component is different from the [**SQL Database** core component](/components-data#sql-database), which executes SQL queries on SQLAlchemy-compatible databases.
|
||||
|
||||
## Text Splitters
|
||||
|
||||
The LangChain bundle includes the following text splitter components:
|
||||
|
||||
- **Character Text Splitter**
|
||||
- **Language Recursive Text Splitter**
|
||||
- **Natural Language Text Splitter**
|
||||
- **Recursive Character Text Splitter**
|
||||
- **Semantic Text Splitter**
|
||||
|
||||
## Tool Calling Agent
|
||||
|
||||
This component is based on the [**Agent** core component](/agents).
|
||||
|
||||
This component creates an agent for structured tool calling with various language models.
|
||||
For more information, see the [LangChain tool calling documentation](https://python.langchain.com/docs/concepts/tool_calling/).
|
||||
|
||||
### Tool Calling Agent parameters
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| llm | LanguageModel | Input parameter. The language model to use. |
|
||||
| tools | List[Tool] | Input parameter. The list of tools available to the agent. |
|
||||
| system_message | String | Input parameter. The system message to use for the agent. |
|
||||
| return_intermediate_steps | Boolean | Input parameter. This determines whether to return the agent's intermediate steps. |
|
||||
| max_iterations | Integer | Input parameter. The maximum number of iterations to run the agent. |
|
||||
| max_execution_time | Integer | Input parameter. The maximum execution time in seconds. |
|
||||
| early_stopping_method | String | Input parameter. The method to use for early stopping. |
|
||||
| verbose | Boolean | Input parameter. This determines whether to print the agent's thoughts. |
|
||||
| agent | AgentExecutor | Output parameter. The tool calling agent instance. |
|
||||
|
||||
## XML Agent
|
||||
|
||||
This component is based on the [**Agent** core component](/agents).
|
||||
|
||||
This component creates an XML Agent using LangChain.
|
||||
The agent uses XML formatting for tool instructions to the LLM.
|
||||
For more information, see the [LangChain XML Agent documentation](https://python.langchain.com/api_reference/langchain/agents/langchain.agents.xml.base.XMLAgent.html).
|
||||
|
||||
### XML Agent parameters
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| llm | LanguageModel | Input parameter. The language model to use for the agent. |
|
||||
| user_prompt | String | Input parameter. The custom prompt template for the agent with XML formatting instructions. |
|
||||
| tools | List[Tool] | Input parameter. The list of tools available to the agent. |
|
||||
| agent | AgentExecutor | Output parameter. The XML Agent instance. |
|
||||
|
||||
## Other LangChain components
|
||||
|
||||
Other components in the LangChain bundle include the following:
|
||||
|
||||
- **Fake Embeddings**
|
||||
- **HTML Link Extractor**
|
||||
- **Runnable Executor**
|
||||
- **Spider Web Crawler & Scraper**
|
||||
|
||||
## Legacy LangChain components
|
||||
|
||||
The following LangChain components are considered legacy.
|
||||
You can still use these components in your flows, but they are no longer maintained and they can be removed in future releases.
|
||||
|
||||
* **Conversation Chain**
|
||||
* **LLM Checker Chain**
|
||||
* **LLM Math Chain**
|
||||
* **Natural Language to SQL**
|
||||
* **Retrieval QA**
|
||||
* **Self Query Retriever**
|
||||
|
||||
<details>
|
||||
<summary>JSON Agent</summary>
|
||||
|
||||
This component creates a JSON agent from a JSON or YAML file and an LLM.
|
||||
|
||||
It accepts the following parameters:
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| llm | LanguageModel | Input parameter. The language model to use for the agent. |
|
||||
| path | File | Input parameter. The path to the JSON or YAML file. |
|
||||
| agent | AgentExecutor | Output parameter. The JSON agent instance. |
|
||||
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>Vector Store Info/Agent</summary>
|
||||
|
||||
This component creates a Vector Store Agent using LangChain.
|
||||
|
||||
It accepts the following parameters:
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| llm | LanguageModel | Input parameter. The language model to use for the agent. |
|
||||
| vectorstore | VectorStoreInfo | Input parameter. The vector store information for the agent to use. |
|
||||
| agent | AgentExecutor | Output parameter. The Vector Store Agent instance. |
|
||||
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>VectorStoreRouterAgent</summary>
|
||||
|
||||
This component creates a Vector Store Router Agent using LangChain.
|
||||
|
||||
It accepts the following parameters:
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| llm | LanguageModel | Input parameter. The language model to use for the agent. |
|
||||
| vectorstores | List[VectorStoreInfo] | Input parameter. The list of vector store information for the agent to route between. |
|
||||
| agent | AgentExecutor | Output parameter. The Vector Store Router Agent instance. |
|
||||
|
||||
</details>
|
||||
56
docs/docs/Components/bundles-lmstudio.mdx
Normal file
56
docs/docs/Components/bundles-lmstudio.mdx
Normal file
|
|
@ -0,0 +1,56 @@
|
|||
---
|
||||
title: LM Studio
|
||||
slug: /bundles-lmstudio
|
||||
---
|
||||
|
||||
import Icon from "@site/src/components/icon";
|
||||
|
||||
[Bundles](/components-bundle-components) contain custom components that support specific third-party integrations with Langflow.
|
||||
|
||||
The components in the **LM Studio** bundle let you use models from a local or hosted instance of LM Studio.
|
||||
Components can require authentication with an LM Studio API key. For information about LM Studio models, connections, and credentials, see the [LM Studio documentation](https://lmstudio.ai/docs).
|
||||
|
||||
## LM Studio text generation
|
||||
|
||||
The **LM Studio** component generates text using LM Studio's local language models.
|
||||
|
||||
It can output either a **Model Response** ([`Message`](/data-types#message)) or a **Language Model** ([`LanguageModel`](/data-types#languagemodel)).
|
||||
|
||||
Use the **Language Model** output when you want to use an LM Studio model as the LLM for another LLM-driven component, such as a **Language Model** or **Smart Function** component.
|
||||
|
||||
For more information, see [**Language Model** components](/components-models).
|
||||
|
||||
### LM Studio text generation parameters
|
||||
|
||||
Many **LM Studio** component input parameters are hidden by default in the visual editor.
|
||||
You can toggle parameters through the <Icon name="SlidersHorizontal" aria-hidden="true"/> **Controls** in the [component's header menu](/concepts-components#component-menus).
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| base_url | String | Input parameter. The URL where LM Studio is running. Default: `"http://localhost:1234"`. |
|
||||
| api_key | LM Studio API Key | Input parameter. The API key for authentication with LM Studio, if required. |
|
||||
| max_tokens | Integer | Input parameter. Maximum number of tokens to generate in the response. Default: `512`. |
|
||||
| temperature | Float | Input parameter. Controls randomness in the output. Range: `[0.0, 2.0]`. Default: `0.7`. |
|
||||
| top_p | Float | Input parameter. Controls diversity via nucleus sampling. Range: `[0.0, 1.0]`. Default: `1.0`. |
|
||||
| stop | List[String] | Input parameter. List of strings that stop generation when encountered. |
|
||||
| stream | Boolean | Input parameter. Whether to stream the response. Default: `False`. |
|
||||
| presence_penalty | Float | Input parameter. Penalizes repeated tokens. Range: `[-2.0, 2.0]`. Default: `0.0`. |
|
||||
| frequency_penalty | Float | Input parameter. Penalizes frequent tokens. Range: `[-2.0, 2.0]`. Default: `0.0`. |
|
||||
|
||||
## LM Studio Embeddings
|
||||
|
||||
The **LM Studio Embeddings** component generates embeddings using LM Studio models.
|
||||
|
||||
For more information about using embedding model components in flows, see [**Embedding Model** components](/components-embedding-models).
|
||||
|
||||
### LM Studio Embeddings parameters
|
||||
|
||||
Many **LM Studio Embeddings** component input parameters are hidden by default in the visual editor.
|
||||
You can toggle parameters through the <Icon name="SlidersHorizontal" aria-hidden="true"/> **Controls** in the [component's header menu](/concepts-components#component-menus).
|
||||
|
||||
| Name | Display Name | Info |
|
||||
|------|--------------|------|
|
||||
| model | Model | Input parameter. The LM Studio model to use for generating embeddings. |
|
||||
| base_url | LM Studio Base URL | Input parameter. The base URL for the LM Studio API. |
|
||||
| api_key | LM Studio API Key | Input parameter. The API key for authentication with LM Studio. |
|
||||
| temperature | Model Temperature | Input parameter. The temperature setting for the model. |
|
||||
35
docs/docs/Components/bundles-maritalk.mdx
Normal file
35
docs/docs/Components/bundles-maritalk.mdx
Normal file
|
|
@ -0,0 +1,35 @@
|
|||
---
|
||||
title: MariTalk
|
||||
slug: /bundles-maritalk
|
||||
---
|
||||
|
||||
import Icon from "@site/src/components/icon";
|
||||
|
||||
[Bundles](/components-bundle-components) contain custom components that support specific third-party integrations with Langflow.
|
||||
|
||||
This page describes the components that are available in the **MariTalk** bundle.
|
||||
|
||||
For more information, see the [MariTalk documentation](https://www.maritalk.com/).
|
||||
|
||||
## MariTalk text generation
|
||||
|
||||
The **MariTalk** component generates text using MariTalk LLMs.
|
||||
|
||||
It can output either a **Model Response** ([`Message`](/data-types#message)) or a **Language Model** ([`LanguageModel`](/data-types#languagemodel)).
|
||||
|
||||
Use the **Language Model** output when you want to use a MariTalk model as the LLM for another LLM-driven component, such as a **Language Model** or **Smart Function** component.
|
||||
|
||||
For more information, see [**Language Model** components](/components-models).
|
||||
|
||||
### MariTalk text generation parameters
|
||||
|
||||
Many **MariTalk** component input parameters are hidden by default in the visual editor.
|
||||
You can toggle parameters through the <Icon name="SlidersHorizontal" aria-hidden="true"/> **Controls** in the [component's header menu](/concepts-components#component-menus).
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| max_tokens | Integer | Input parameter. The maximum number of tokens to generate. Set to `0` for unlimited tokens. Default: `512`. |
|
||||
| model_name | String | Input parameter. The name of the MariTalk model to use. Options: `sabia-2-small`, `sabia-2-medium`. Default: `sabia-2-small`. |
|
||||
| api_key | SecretString | Input parameter. The MariTalk API Key to use for authentication. |
|
||||
| temperature | Float | Input parameter. Controls randomness in the output. Range: `[0.0, 1.0]`. Default: `0.5`. |
|
||||
| endpoint_url | String | Input parameter. The MariTalk API endpoint. Default: `https://api.maritalk.com`. |
|
||||
39
docs/docs/Components/bundles-mem0.mdx
Normal file
39
docs/docs/Components/bundles-mem0.mdx
Normal file
|
|
@ -0,0 +1,39 @@
|
|||
---
|
||||
title: Mem0
|
||||
slug: /bundles-mem0
|
||||
---
|
||||
|
||||
import Icon from "@site/src/components/icon";
|
||||
|
||||
[Bundles](/components-bundle-components) contain custom components that support specific third-party integrations with Langflow.
|
||||
|
||||
This page describes the components that are available in the **Mem0** bundle.
|
||||
|
||||
## Mem0 Chat Memory
|
||||
|
||||
The **Mem0 Chat Memory** component retrieves and stores chat messages using Mem0 memory storage.
|
||||
|
||||
### Mem0 Chat Memory parameters
|
||||
|
||||
Many **Mem0 Chat Memory** component input parameters are hidden by default in the visual editor.
|
||||
You can toggle parameters through the <Icon name="SlidersHorizontal" aria-hidden="true"/> **Controls** in the [component's header menu](/concepts-components#component-menus).
|
||||
|
||||
| Name | Display Name | Info |
|
||||
|------|--------------|------|
|
||||
| mem0_config | Mem0 Configuration | Input parameter. The configuration dictionary for initializing the Mem0 memory instance. |
|
||||
| ingest_message | Message to Ingest | Input parameter. The message content to be ingested into Mem0 memory. |
|
||||
| existing_memory | Existing Memory Instance | Input parameter. An optional existing Mem0 memory instance. |
|
||||
| user_id | User ID | Input parameter. The identifier for the user associated with the messages. |
|
||||
| search_query | Search Query | Input parameter. The input text for searching related memories in Mem0. |
|
||||
| mem0_api_key | Mem0 API Key | Input parameter. The API key for the Mem0 platform. Leave empty to use the local version. |
|
||||
| metadata | Metadata | Input parameter. The additional metadata to associate with the ingested message. |
|
||||
| openai_api_key | OpenAI API Key | Input parameter. The API key for OpenAI. Required when using OpenAI embeddings without a provided configuration. |
|
||||
|
||||
### Mem0 Chat Memory output
|
||||
|
||||
The **Mem0 Chat Memory** component can output either **Mem0 Memory** ([`Memory`](/data-types#memory)) or **Search Results** ([`Data`](/data-types#data)).
|
||||
You can select the output type near the component's output port.
|
||||
|
||||
Use **Mem0 Chat Memory** for memory storage and retrieval operations with the [**Message History** component](/components-helpers#message-history).
|
||||
|
||||
Use the **Search Results** output to retrieve specific memories based on a search query.
|
||||
61
docs/docs/Components/bundles-mistralai.mdx
Normal file
61
docs/docs/Components/bundles-mistralai.mdx
Normal file
|
|
@ -0,0 +1,61 @@
|
|||
---
|
||||
title: MistralAI
|
||||
slug: /bundles-mistralai
|
||||
---
|
||||
|
||||
import Icon from "@site/src/components/icon";
|
||||
|
||||
[Bundles](/components-bundle-components) contain custom components that support specific third-party integrations with Langflow.
|
||||
|
||||
This page describes the components that are available in the **MistralAI** bundle.
|
||||
|
||||
For more information about MistralAI features and functionality used by MistralAI components, see the [MistralAI documentation](https://docs.mistral.ai).
|
||||
|
||||
## MistralAI text generation
|
||||
|
||||
The **MistralAI** component generates text using MistralAI LLMs.
|
||||
|
||||
It can output either a **Model Response** ([`Message`](/data-types#message)) or a **Language Model** ([`LanguageModel`](/data-types#languagemodel)).
|
||||
|
||||
Use the **Language Model** output when you want to use a MistalAI model as the LLM for another LLM-driven component, such as a **Language Model** or **Smart Function** component.
|
||||
|
||||
For more information, see [**Language Model** components](/components-models).
|
||||
|
||||
### MistralAI text generation parameters
|
||||
|
||||
Many **MistralAI** component input parameters are hidden by default in the visual editor.
|
||||
You can toggle parameters through the <Icon name="SlidersHorizontal" aria-hidden="true"/> **Controls** in the [component's header menu](/concepts-components#component-menus).
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| max_tokens | Integer | Input parameter. The maximum number of tokens to generate. Set to 0 for unlimited tokens (advanced). |
|
||||
| model_name | String | Input parameter. The name of the Mistral AI model to use. Options include `open-mixtral-8x7b`, `open-mixtral-8x22b`, `mistral-small-latest`, `mistral-medium-latest`, `mistral-large-latest`, and `codestral-latest`. Default: `codestral-latest`. |
|
||||
| mistral_api_base | String | Input parameter. The base URL of the Mistral API. Defaults to `https://api.mistral.ai/v1` (advanced). |
|
||||
| api_key | SecretString | Input parameter. The Mistral API Key to use for authentication. |
|
||||
| temperature | Float | Input parameter. Controls randomness in the output. Default: 0.5. |
|
||||
| max_retries | Integer | Input parameter. Maximum number of retries for API calls. Default: 5 (advanced). |
|
||||
| timeout | Integer | Input parameter. Timeout for API calls in seconds. Default: 60 (advanced). |
|
||||
| max_concurrent_requests | Integer | Input parameter. Maximum number of concurrent API requests. Default: 3 (advanced). |
|
||||
| top_p | Float | Input parameter. Nucleus sampling parameter. Default: 1 (advanced). |
|
||||
| random_seed | Integer | Input parameter. Seed for random number generation. Default: 1 (advanced). |
|
||||
| safe_mode | Boolean | Input parameter. Enables safe mode for content generation (advanced). |
|
||||
|
||||
## MistralAI Embeddings
|
||||
|
||||
The **MistralAI Embeddings** component generates embeddings using MistralAI models.
|
||||
|
||||
For more information about using embedding model components in flows, see [**Embedding Model** components](/components-embedding-models).
|
||||
|
||||
### MistralAI Embeddings parameters
|
||||
|
||||
Many **MistralAI Embeddings** component input parameters are hidden by default in the visual editor.
|
||||
You can toggle parameters through the <Icon name="SlidersHorizontal" aria-hidden="true"/> **Controls** in the [component's header menu](/concepts-components#component-menus).
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| model | String | Input parameter. The MistralAI model to use. Default: "mistral-embed". |
|
||||
| mistral_api_key | SecretString | Input parameter. The API key for authenticating with MistralAI. |
|
||||
| max_concurrent_requests | Integer | Input parameter. The maximum number of concurrent API requests. Default: 64. |
|
||||
| max_retries | Integer | Input parameter. The maximum number of retry attempts for failed requests. Default: 5. |
|
||||
| timeout | Integer | Input parameter. The request timeout in seconds. Default: 120. |
|
||||
| endpoint | String | Input parameter. The custom API endpoint URL. Default: `https://api.mistral.ai/v1/`. |
|
||||
35
docs/docs/Components/bundles-novita.mdx
Normal file
35
docs/docs/Components/bundles-novita.mdx
Normal file
|
|
@ -0,0 +1,35 @@
|
|||
---
|
||||
title: Novita
|
||||
slug: /bundles-novita
|
||||
---
|
||||
|
||||
import Icon from "@site/src/components/icon";
|
||||
|
||||
[Bundles](/components-bundle-components) contain custom components that support specific third-party integrations with Langflow.
|
||||
|
||||
This page describes the components that are available in the **Novita** bundle.
|
||||
|
||||
## Novita AI
|
||||
|
||||
This component generates text using [Novita's language models](https://novita.ai/docs/guides/llm-api).
|
||||
|
||||
It can output either a **Model Response** ([`Message`](/data-types#message)) or a **Language Model** ([`LanguageModel`](/data-types#languagemodel)).
|
||||
|
||||
Use the **Language Model** output when you want to use a Novita model as the LLM for another LLM-driven component, such as a **Language Model** or **Smart Function** component.
|
||||
|
||||
For more information, see [**Language Model** components](/components-models).
|
||||
|
||||
### Novita AI parameters
|
||||
|
||||
Many **Novita AI** component input parameters are hidden by default in the visual editor.
|
||||
You can toggle parameters through the <Icon name="SlidersHorizontal" aria-hidden="true"/> **Controls** in the [component's header menu](/concepts-components#component-menus).
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| api_key | SecretString | Input parameter. Your Novita AI API Key. |
|
||||
| model | String | Input parameter. The id of the Novita AI model to use. |
|
||||
| max_tokens | Integer | Input parameter. The maximum number of tokens to generate. Set to 0 for unlimited tokens. |
|
||||
| temperature | Float | Input parameter. Controls randomness in the output. Range: [0.0, 1.0]. Default: 0.7. |
|
||||
| top_p | Float | Input parameter. Controls the nucleus sampling. Range: [0.0, 1.0]. Default: 1.0. |
|
||||
| frequency_penalty | Float | Input parameter. Controls the frequency penalty. Range: [0.0, 2.0]. Default: 0.0. |
|
||||
| presence_penalty | Float | Input parameter. Controls the presence penalty. Range: [0.0, 2.0]. Default: 0.0. |
|
||||
59
docs/docs/Components/bundles-nvidia.mdx
Normal file
59
docs/docs/Components/bundles-nvidia.mdx
Normal file
|
|
@ -0,0 +1,59 @@
|
|||
---
|
||||
title: NVIDIA components
|
||||
slug: /bundles-nvidia
|
||||
---
|
||||
|
||||
import Icon from "@site/src/components/icon";
|
||||
|
||||
[Bundles](/components-bundle-components) contain custom components that support specific third-party integrations with Langflow.
|
||||
|
||||
This page describes the components that are available in the **NVIDIA** bundle.
|
||||
|
||||
## NVIDIA
|
||||
|
||||
This component generates text using NVIDIA LLMs.
|
||||
For more information about NVIDIA LLMs, see the [NVIDIA AI documentation](https://developer.nvidia.com/generative-ai).
|
||||
|
||||
For an example of this component in a flow, see [Integrate NVIDIA NIMs with Langflow](/integrations-nvidia-ingest-wsl2).
|
||||
|
||||
### NVIDIA parameters
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| max_tokens | Integer | Input parameter. The maximum number of tokens to generate. Set to `0` for unlimited tokens (advanced). |
|
||||
| model_name | String | Input parameter. The name of the NVIDIA model to use. Default: `mistralai/mixtral-8x7b-instruct-v0.1`. |
|
||||
| base_url | String | Input parameter. The base URL of the NVIDIA API. Default: `https://integrate.api.nvidia.com/v1`. |
|
||||
| nvidia_api_key | SecretString | Input parameter. The NVIDIA API Key for authentication. |
|
||||
| temperature | Float | Input parameter. Controls randomness in the output. Default: `0.1`. |
|
||||
| seed | Integer | Input parameter. The seed controls the reproducibility of the job (advanced). Default: `1`. |
|
||||
| model | LanguageModel | Output parameter. An instance of ChatNVIDIA configured with the specified parameters. |
|
||||
|
||||
## NVIDIA Embeddings
|
||||
|
||||
The **NVIDIA Embeddings** component generates embeddings using [NVIDIA models](https://docs.nvidia.com).
|
||||
|
||||
For more information about using embedding model components in flows, see [**Embedding Model** components](/components-embedding-models).
|
||||
|
||||
### NVIDIA Embeddings parameters
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| model | String | Input parameter. The NVIDIA model to use for embeddings, such as `nvidia/nv-embed-v1`. |
|
||||
| base_url | String | Input parameter. The base URL for the NVIDIA API. Default: `https://integrate.api.nvidia.com/v1`. |
|
||||
| nvidia_api_key | SecretString | Input parameter. The API key for authenticating with NVIDIA's service. |
|
||||
| temperature | Float | Input parameter. The model temperature for embedding generation. Default: `0.1`. |
|
||||
| embeddings | Embeddings | Output parameter. An NVIDIAEmbeddings instance for generating embeddings. |
|
||||
|
||||
## NVIDIA Rerank
|
||||
|
||||
This component finds and reranks documents using the NVIDIA API.
|
||||
|
||||
## NVIDIA Retriever Extraction
|
||||
|
||||
This component uses the NVIDIA `nv-ingest` microservice for data ingestion, processing, and extraction of text files.
|
||||
For more information, see [Integrate NVIDIA Retriever Extraction with Langflow](/integrations-nvidia-ingest).
|
||||
|
||||
## NVIDIA System-Assist
|
||||
|
||||
This component requires a specific system environment.
|
||||
For information about this component, see [Integrate NVIDIA G-Assist with Langflow](/integrations-nvidia-g-assist).
|
||||
66
docs/docs/Components/bundles-ollama.mdx
Normal file
66
docs/docs/Components/bundles-ollama.mdx
Normal file
|
|
@ -0,0 +1,66 @@
|
|||
---
|
||||
title: Ollama
|
||||
slug: /bundles-ollama
|
||||
---
|
||||
|
||||
import Icon from "@site/src/components/icon";
|
||||
|
||||
[Bundles](/components-bundle-components) contain custom components that support specific third-party integrations with Langflow.
|
||||
|
||||
This page describes the components that are available in the **Ollama** bundle.
|
||||
|
||||
For more information about Ollama features and functionality used by Ollama components, see the [Ollama documentation](https://ollama.com/).
|
||||
|
||||
## Ollama text generation
|
||||
|
||||
This component generates text using [Ollama's language models](https://ollama.com/library).
|
||||
|
||||
To use the **Ollama** component in a flow, connect Langflow to your locally running Ollama server and select a model:
|
||||
|
||||
1. Add the **Ollama** component to your flow.
|
||||
|
||||
2. In the **Base URL** field, enter the address for your locally running Ollama server.
|
||||
|
||||
This value is set as the `OLLAMA_HOST` environment variable in Ollama.
|
||||
The default base URL is `http://127.0.0.1:11434`.
|
||||
|
||||
3. Once the connection is established, select a model in the **Model Name** field, such as `llama3.2:latest`.
|
||||
|
||||
To refresh the server's list of models, click <Icon name="RefreshCw" aria-hidden="true"/> **Refresh**.
|
||||
|
||||
4. Optional: To configure additional parameters, such as temperature or max tokens, click <Icon name="SlidersHorizontal" aria-hidden="true"/> **Controls** in the [component's header menu](/concepts-components#component-menus).
|
||||
|
||||
5. Connect the **Ollama** component to other components in the flow, depending on how you want to use the model.
|
||||
|
||||
Language model components can output either a **Model Response** ([`Message`](/data-types#message)) or a **Language Model** ([`LanguageModel`](/data-types#languagemodel)). Use the **Language Model** output when you want to use an Ollama model as the LLM for another LLM-driven component, such as a **Language Model** or **Smart Function** component. For more information, see [**Language Model** components](/components-models).
|
||||
|
||||
In the following example, the flow uses `LanguageModel` output to use an Ollama model as the LLM for an [**Agent** component](/components-agents).
|
||||
|
||||

|
||||
|
||||
## Ollama Embeddings
|
||||
|
||||
The **Ollama Embeddings** component generates embeddings using [Ollama embedding models](https://ollama.com/search?c=embedding).
|
||||
|
||||
To use this component in a flow, connect Langflow to your locally running Ollama server and select an embeddings model:
|
||||
|
||||
1. Add the **Ollama Embeddings** component to your flow.
|
||||
|
||||
2. In the **Ollama Base URL** field, enter the address for your locally running Ollama server.
|
||||
|
||||
This value is set as the `OLLAMA_HOST` environment variable in Ollama.
|
||||
The default base URL is `http://127.0.0.1:11434`.
|
||||
|
||||
3. Once the connection is established, select a model in the **Ollama Model** field, such as `all-minilm:latest`.
|
||||
|
||||
To refresh the server's list of models, click <Icon name="RefreshCw" aria-hidden="true"/> **Refresh**.
|
||||
|
||||
4. Optional: To configure additional parameters, such as temperature or max tokens, click <Icon name="SlidersHorizontal" aria-hidden="true"/> **Controls** in the [component's header menu](/concepts-components#component-menus).
|
||||
Available parameters depend on the selected model.
|
||||
|
||||
5. Connect the **Ollama Embeddings** component to other components in the flow.
|
||||
For more information about using embedding model components in flows, see [**Embedding Model** components](/components-embedding-models).
|
||||
|
||||
This example connects the **Ollama Embeddings** component to generate embeddings for text chunks extracted from a PDF file, and then stores the embeddings and chunks in a Chroma DB vector store.
|
||||
|
||||

|
||||
82
docs/docs/Components/bundles-openai.mdx
Normal file
82
docs/docs/Components/bundles-openai.mdx
Normal file
|
|
@ -0,0 +1,82 @@
|
|||
---
|
||||
title: OpenAI
|
||||
slug: /bundles-openai
|
||||
---
|
||||
|
||||
import Icon from "@site/src/components/icon";
|
||||
|
||||
[Bundles](/components-bundle-components) contain custom components that support specific third-party integrations with Langflow.
|
||||
|
||||
This page describes the components that are available in the **OpenAI** bundle.
|
||||
|
||||
For more information about OpenAI features and functionality used by OpenAI components, see the [OpenAI documentation](https://platform.openai.com/docs/overview).
|
||||
|
||||
## OpenAI text generation
|
||||
|
||||
The **OpenAI** component generates text using [OpenAI's language models](https://platform.openai.com/docs/models).
|
||||
|
||||
It provides access to the same OpenAI models that are available in the core **Language Model** component, but the **OpenAI** component provides additional parameters for customizing the request to the OpenAI API.
|
||||
|
||||
It can output either a **Model Response** ([`Message`](/data-types#message)) or a **Language Model** ([`LanguageModel`](/data-types#languagemodel)).
|
||||
|
||||
Use the **Language Model** output when you want to use a specific OpenAI model configuration as the LLM for another LLM-driven component, such as a **Language Model** or **Smart Function** component.
|
||||
|
||||
For more information, see [**Language Model** components](/components-models).
|
||||
|
||||
### OpenAI text generation parameters
|
||||
|
||||
Many **OpenAI** component input parameters are hidden by default in the visual editor.
|
||||
You can toggle parameters through the <Icon name="SlidersHorizontal" aria-hidden="true"/> **Controls** in the [component's header menu](/concepts-components#component-menus).
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| api_key | SecretString | Input parameter. Your OpenAI API Key. |
|
||||
| model | String | Input parameter. The name of the OpenAI model to use. Options include "gpt-3.5-turbo" and "gpt-4". |
|
||||
| max_tokens | Integer | Input parameter. The maximum number of tokens to generate. Set to 0 for unlimited tokens. |
|
||||
| temperature | Float | Input parameter. Controls randomness in the output. Range: [0.0, 1.0]. Default: 0.7. |
|
||||
| top_p | Float | Input parameter. Controls the nucleus sampling. Range: [0.0, 1.0]. Default: 1.0. |
|
||||
| frequency_penalty | Float | Input parameter. Controls the frequency penalty. Range: [0.0, 2.0]. Default: 0.0. |
|
||||
| presence_penalty | Float | Input parameter. Controls the presence penalty. Range: [0.0, 2.0]. Default: 0.0. |
|
||||
|
||||
## OpenAI Embeddings
|
||||
|
||||
The **OpenAI Embeddings** component uses [OpenAI embedding models](https://platform.openai.com/docs/guides/embeddings) for embedding generation.
|
||||
|
||||
It provides access to the same OpenAI models that are available in the core **Embedding Model** component, but the **OpenAI Embeddings** component provides additional parameters for customizing the request to the OpenAI embedding API.
|
||||
|
||||
For more information about using embedding model components in flows, see [**Embedding Model** components](/components-embedding-models).
|
||||
|
||||
### OpenAI Embeddings parameters
|
||||
|
||||
Many **OpenAI Embeddings** component input parameters are hidden by default in the visual editor.
|
||||
You can toggle parameters through the <Icon name="SlidersHorizontal" aria-hidden="true"/> **Controls** in the [component's header menu](/concepts-components#component-menus).
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| OpenAI API Key | String | Input parameter. The API key to use for accessing the OpenAI API. |
|
||||
| Default Headers | Dict | Input parameter. The default headers for the HTTP requests. |
|
||||
| Default Query | NestedDict | Input parameter. The default query parameters for the HTTP requests. |
|
||||
| Allowed Special | List | Input parameter. The special tokens allowed for processing. Default: `[]`. |
|
||||
| Disallowed Special | List | Input parameter. The special tokens disallowed for processing. Default: `["all"]`. |
|
||||
| Chunk Size | Integer | Input parameter. The chunk size for processing. Default: `1000`. |
|
||||
| Client | Any | Input parameter. The HTTP client for making requests. |
|
||||
| Deployment | String | Input parameter. The deployment name for the model. Default: `text-embedding-3-small`. |
|
||||
| Embedding Context Length | Integer | Input parameter. The length of embedding context. Default: `8191`. |
|
||||
| Max Retries | Integer | Input parameter. The maximum number of retries for failed requests. Default: `6`. |
|
||||
| Model | String | Input parameter. The name of the model to use. Default: `text-embedding-3-small`. |
|
||||
| Model Kwargs | NestedDict | Input parameter. Additional keyword arguments for the model. |
|
||||
| OpenAI API Base | String | Input parameter. The base URL of the OpenAI API. |
|
||||
| OpenAI API Type | String | Input parameter. The type of the OpenAI API. |
|
||||
| OpenAI API Version | String | Input parameter. The version of the OpenAI API. |
|
||||
| OpenAI Organization | String | Input parameter. The organization associated with the API key. |
|
||||
| OpenAI Proxy | String | Input parameter. The proxy server for the requests. |
|
||||
| Request Timeout | Float | Input parameter. The timeout for the HTTP requests. |
|
||||
| Show Progress Bar | Boolean | Input parameter. Whether to show a progress bar for processing. Default: `False`. |
|
||||
| Skip Empty | Boolean | Input parameter. Whether to skip empty inputs. Default: `False`. |
|
||||
| TikToken Enable | Boolean | Input parameter. Whether to enable TikToken. Default: `True`. |
|
||||
| TikToken Model Name | String | Input parameter. The name of the TikToken model. |
|
||||
|
||||
## See also
|
||||
|
||||
* [**Agent** component](/components-agents)
|
||||
* [LangChain **OpenAI Tools Agent** component](/bundles-langchain#openai-tools-agent)
|
||||
37
docs/docs/Components/bundles-openrouter.mdx
Normal file
37
docs/docs/Components/bundles-openrouter.mdx
Normal file
|
|
@ -0,0 +1,37 @@
|
|||
---
|
||||
title: OpenRouter
|
||||
slug: /bundles-openrouter
|
||||
---
|
||||
|
||||
import Icon from "@site/src/components/icon";
|
||||
|
||||
[Bundles](/components-bundle-components) contain custom components that support specific third-party integrations with Langflow.
|
||||
|
||||
This page describes the components that are available in the **OpenRouter** bundle.
|
||||
|
||||
For more information about OpenRouter features and functionality used by OpenRouter components, see the [OpenRouter documentation](https://openrouter.ai/docs).
|
||||
|
||||
## OpenRouter text generation
|
||||
|
||||
This component generates text using OpenRouter's unified API for multiple AI models from different providers.
|
||||
|
||||
It can output either a **Model Response** ([`Message`](/data-types#message)) or a **Language Model** ([`LanguageModel`](/data-types#languagemodel)).
|
||||
|
||||
Use the **Language Model** output when you want to use an OpenRouter model as the LLM for another LLM-driven component, such as a **Language Model** or **Smart Function** component.
|
||||
|
||||
For more information, see [**Language Model** components](/components-models).
|
||||
|
||||
### OpenRouter text generation parameters
|
||||
|
||||
Many **OpenRouter** component input parameters are hidden by default in the visual editor.
|
||||
You can toggle parameters through the <Icon name="SlidersHorizontal" aria-hidden="true"/> **Controls** in the [component's header menu](/concepts-components#component-menus).
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| api_key | SecretString | Input parameter. Your OpenRouter API key for authentication. |
|
||||
| site_url | String | Input parameter. Your site URL for OpenRouter rankings (advanced). |
|
||||
| app_name | String | Input parameter. Your app name for OpenRouter rankings (advanced). |
|
||||
| provider | String | Input parameter. The AI model provider to use. |
|
||||
| model_name | String | Input parameter. The specific model to use for chat completion. |
|
||||
| temperature | Float | Input parameter. Controls randomness in the output. Range: [0.0, 2.0]. Default: 0.7. |
|
||||
| max_tokens | Integer | Input parameter. The maximum number of tokens to generate (advanced). |
|
||||
37
docs/docs/Components/bundles-perplexity.mdx
Normal file
37
docs/docs/Components/bundles-perplexity.mdx
Normal file
|
|
@ -0,0 +1,37 @@
|
|||
---
|
||||
title: Perplexity
|
||||
slug: /bundles-perplexity
|
||||
---
|
||||
|
||||
import Icon from "@site/src/components/icon";
|
||||
|
||||
[Bundles](/components-bundle-components) contain custom components that support specific third-party integrations with Langflow.
|
||||
|
||||
This page describes the components that are available in the **Perplexity** bundle.
|
||||
|
||||
For more information about Perplexity features and functionality used by Perplexity components, see the [Perplexity documentation](https://perplexity.ai/).
|
||||
|
||||
## Perplexity text generation
|
||||
|
||||
This component generates text using Perplexity's language models.
|
||||
|
||||
It can output either a **Model Response** ([`Message`](/data-types#message)) or a **Language Model** ([`LanguageModel`](/data-types#languagemodel)).
|
||||
|
||||
Use the **Language Model** output when you want to use a Perplexity model as the LLM for another LLM-driven component, such as a **Language Model** or **Smart Function** component.
|
||||
|
||||
For more information, see [**Language Model** components](/components-models).
|
||||
|
||||
### Perplexity text generation parameters
|
||||
|
||||
Many **Perplexity** component input parameters are hidden by default in the visual editor.
|
||||
You can toggle parameters through the <Icon name="SlidersHorizontal" aria-hidden="true"/> **Controls** in the [component's header menu](/concepts-components#component-menus).
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| model_name | String | Input parameter. The name of the Perplexity model to use. Options include various Llama 3.1 models. |
|
||||
| max_output_tokens | Integer | Input parameter. The maximum number of tokens to generate. |
|
||||
| api_key | SecretString | Input parameter. The Perplexity API Key for authentication. |
|
||||
| temperature | Float | Input parameter. Controls randomness in the output. Default: 0.75. |
|
||||
| top_p | Float | Input parameter. The maximum cumulative probability of tokens to consider when sampling (advanced). |
|
||||
| n | Integer | Input parameter. Number of chat completions to generate for each prompt (advanced). |
|
||||
| top_k | Integer | Input parameter. Number of top tokens to consider for top-k sampling. Must be positive (advanced). |
|
||||
37
docs/docs/Components/bundles-redis.mdx
Normal file
37
docs/docs/Components/bundles-redis.mdx
Normal file
|
|
@ -0,0 +1,37 @@
|
|||
---
|
||||
title: Redis
|
||||
slug: /bundles-redis
|
||||
---
|
||||
|
||||
import Icon from "@site/src/components/icon";
|
||||
|
||||
[Bundles](/components-bundle-components) contain custom components that support specific third-party integrations with Langflow.
|
||||
|
||||
This page describes the components that are available in the **Redis** bundle.
|
||||
|
||||
## Redis Chat Memory
|
||||
|
||||
The **Redis Chat Memory** component retrieves and stores chat messages using Redis memory storage.
|
||||
|
||||
Chat memories are passed between memory storage components as the [`Memory`](/data-types#memory) data type.
|
||||
|
||||
For more information about using external chat memory in flows, see the [**Message History** component](/components-helpers#message-history).
|
||||
|
||||
### Redis Chat Memory parameters
|
||||
|
||||
Many **Redis Chat Memory** component input parameters are hidden by default in the visual editor.
|
||||
You can toggle parameters through the <Icon name="SlidersHorizontal" aria-hidden="true"/> **Controls** in the [component's header menu](/concepts-components#component-menus).
|
||||
|
||||
| Name | Display Name | Info |
|
||||
|------|--------------|------|
|
||||
| host | hostname | Input parameter. The IP address or hostname. |
|
||||
| port | port | Input parameter. The Redis Port Number. |
|
||||
| database | database | Input parameter. The Redis database. |
|
||||
| username | Username | Input parameter. The Redis username. |
|
||||
| password | Password | Input parameter. The password for the username. |
|
||||
| key_prefix | Key prefix | Input parameter. The key prefix. |
|
||||
| session_id | Session ID | Input parameter. The unique session identifier for the message. |
|
||||
|
||||
## Redis vector store
|
||||
|
||||
See [**Redis** vector store component](/components-vector-stores#redis).
|
||||
35
docs/docs/Components/bundles-sambanova.mdx
Normal file
35
docs/docs/Components/bundles-sambanova.mdx
Normal file
|
|
@ -0,0 +1,35 @@
|
|||
---
|
||||
title: SambaNova
|
||||
slug: /bundles-sambanova
|
||||
---
|
||||
|
||||
import Icon from "@site/src/components/icon";
|
||||
|
||||
[Bundles](/components-bundle-components) contain custom components that support specific third-party integrations with Langflow.
|
||||
|
||||
This page describes the components that are available in the **SambaNova** bundle.
|
||||
|
||||
For more information about SambaNova features and functionality used by SambaNova components, see the [SambaNova Cloud documentation](https://cloud.sambanova.ai/).
|
||||
|
||||
## SambaNova text generation
|
||||
|
||||
This component generates text using SambaNova LLMs.
|
||||
|
||||
It can output either a **Model Response** ([`Message`](/data-types#message)) or a **Language Model** ([`LanguageModel`](/data-types#languagemodel)).
|
||||
|
||||
Use the **Language Model** output when you want to use a SambaNova model as the LLM for another LLM-driven component, such as a **Language Model** or **Smart Function** component.
|
||||
|
||||
For more information, see [**Language Model** components](/components-models).
|
||||
|
||||
### SambaNova text generation parameters
|
||||
|
||||
Many **SambaNova** component input parameters are hidden by default in the visual editor.
|
||||
You can toggle parameters through the <Icon name="SlidersHorizontal" aria-hidden="true"/> **Controls** in the [component's header menu](/concepts-components#component-menus).
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| sambanova_url | String | Input parameter. Base URL path for API requests. Default: `https://api.sambanova.ai/v1/chat/completions`. |
|
||||
| sambanova_api_key | SecretString | Input parameter. Your SambaNova API Key. |
|
||||
| model_name | String | Input parameter. The name of the SambaNova model to use. Options include various Llama models. |
|
||||
| max_tokens | Integer | Input parameter. The maximum number of tokens to generate. Set to 0 for unlimited tokens. |
|
||||
| temperature | Float | Input parameter. Controls randomness in the output. Range: [0.0, 1.0]. Default: 0.07. |
|
||||
39
docs/docs/Components/bundles-searchapi.mdx
Normal file
39
docs/docs/Components/bundles-searchapi.mdx
Normal file
|
|
@ -0,0 +1,39 @@
|
|||
---
|
||||
title: SearchApi
|
||||
slug: /bundles-searchapi
|
||||
---
|
||||
|
||||
import Icon from "@site/src/components/icon";
|
||||
|
||||
[Bundles](/components-bundle-components) contain custom components that support specific third-party integrations with Langflow.
|
||||
|
||||
This page describes the components that are available in the **SearchApi** bundle.
|
||||
|
||||
For more information, see the [SearchApi documentation](https://www.searchapi.io/docs/google).
|
||||
|
||||
## SearchApi web search
|
||||
|
||||
This component calls the SearchApi API to run Google, Bing, and DuckDuckGo web searches.
|
||||
|
||||
It returns a list of search results as a [`DataFrame`](/data-types#dataframe).
|
||||
|
||||
### SearchApi web search parameters
|
||||
|
||||
Some **SearchApi** component input parameters are hidden by default in the visual editor.
|
||||
You can toggle parameters through the <Icon name="SlidersHorizontal" aria-hidden="true"/> **Controls** in the [component's header menu](/concepts-components#component-menus).
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| engine | String | Input parameter. The search engine to use. Default: `google`. |
|
||||
| api_key | SecretString | Input parameter. The API key for authenticating with SearchApi. |
|
||||
| input_value | String | Input parameter. The search query or input for the API call. |
|
||||
| max_results | Integer | Input parameter. The maximum number of search results to return. Default: `5`. |
|
||||
| max_snippet_length | Integer | Input parameter. The maximum length of the snippet to return. Default: `100`. |
|
||||
| search_params | Dict | Input parameter. Additional key-value pairs to customize the request. |
|
||||
|
||||
## See also
|
||||
|
||||
* [**Web Search** component](/components-data#web-search)
|
||||
* [**Google** bundle](/bundles-google)
|
||||
* [**Bing** bundle](/bundles-bing)
|
||||
* [**DuckDuckGo** bundle](/bundles-duckduckgo)
|
||||
111
docs/docs/Components/bundles-vertexai.mdx
Normal file
111
docs/docs/Components/bundles-vertexai.mdx
Normal file
|
|
@ -0,0 +1,111 @@
|
|||
---
|
||||
title: Vertex AI
|
||||
slug: /bundles-vertexai
|
||||
---
|
||||
|
||||
import Icon from "@site/src/components/icon";
|
||||
|
||||
[Bundles](/components-bundle-components) contain custom components that support specific third-party integrations with Langflow.
|
||||
|
||||
This page describes the components that are available in the **Vertex AI** bundle.
|
||||
|
||||
For more information about Vertex AI features and functionality used by Vertex AI components, see the [Vertex AI documentation](https://cloud.google.com/vertex-ai).
|
||||
|
||||
For other Google components, see the [**Google** bundle](/bundles-google).
|
||||
|
||||
## Vertex AI text generation
|
||||
|
||||
The **Vertex AI** component generates text using Google Vertex AI models.
|
||||
|
||||
It can output either a **Model Response** ([`Message`](/data-types#message)) or a **Language Model** ([`LanguageModel`](/data-types#languagemodel)).
|
||||
|
||||
Use the **Language Model** output when you want to use a Vertex AI model as the LLM for another LLM-driven component, such as a **Language Model** or **Smart Function** component.
|
||||
|
||||
For more information, see [**Language Model** components](/components-models).
|
||||
|
||||
### Vertex AI text generation parameters
|
||||
|
||||
Many **Vertex AI** component input parameters are hidden by default in the visual editor.
|
||||
You can toggle parameters through the <Icon name="SlidersHorizontal" aria-hidden="true"/> **Controls** in the [component's header menu](/concepts-components#component-menus).
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| credentials | File | Input parameter. JSON credentials file. Leave empty to fall back to environment variables. File type: JSON. For more information, see [Create a service account for Vertex AI authentication](#vertexai-credentials). |
|
||||
| model_name | String | Input parameter. The name of the Vertex AI model to use. Default: "gemini-1.5-pro". |
|
||||
| project | String | Input parameter. The project ID (advanced). |
|
||||
| location | String | Input parameter. The location for the Vertex AI API. Default: "us-central1" (advanced). |
|
||||
| max_output_tokens | Integer | Input parameter. The maximum number of tokens to generate (advanced). |
|
||||
| max_retries | Integer | Input parameter. Maximum number of retries for API calls. Default: 1 (advanced). |
|
||||
| temperature | Float | Input parameter. Controls randomness in the output. Default: 0.0. |
|
||||
| top_k | Integer | Input parameter. The number of highest-probability vocabulary tokens to keep for top-k-filtering (advanced). |
|
||||
| top_p | Float | Input parameter. The cumulative probability of all highest-probability vocabulary tokens that are kept for nucleus sampling. Default: 0.95 (advanced). |
|
||||
| verbose | Boolean | Input parameter. Whether to print verbose output. Default: False (advanced). |
|
||||
|
||||
For more information about Vertex AI text generation parameters, see the [Vertex AI content generation parameters documentation](https://cloud.google.com/vertex-ai/generative-ai/docs/multimodal/content-generation-parameters#token-sampling-parameters).
|
||||
|
||||
## Vertex AI Embeddings
|
||||
|
||||
The **Vertex AI Embeddings** component is a wrapper around the [Google Vertex AI Embeddings API](https://cloud.google.com/vertex-ai/docs/generative-ai/embeddings/get-text-embeddings) for embedding generation.
|
||||
|
||||
For more information about using embedding model components in flows, see [**Embedding Model** components](/components-embedding-models).
|
||||
|
||||
### Vertex AI Embeddings parameters
|
||||
|
||||
Many **Vertex AI Embeddings** component input parameters are hidden by default in the visual editor.
|
||||
You can toggle parameters through the <Icon name="SlidersHorizontal" aria-hidden="true"/> **Controls** in the [component's header menu](/concepts-components#component-menus).
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| credentials | Credentials | Input parameter. JSON credentials file. Leave empty to fall back to environment variables. File type: JSON. For more information, see [Create a service account for Vertex AI authentication](#vertexai-credentials). |
|
||||
| location | String | Input parameter. The default location to use when making API calls. Default: `us-central1`. |
|
||||
| max_output_tokens | Integer | Input parameter. The token limit determines the maximum amount of text output from one prompt. Default: `128`. |
|
||||
| model_name | String | Input parameter. The name of the Vertex AI large language model. Default: `text-bison`. |
|
||||
| project | String | Input parameter. The default GCP project to use when making Vertex API calls. |
|
||||
| request_parallelism | Integer | Input parameter. The amount of parallelism allowed for requests issued to Vertex AI models. Default: `5`. |
|
||||
| temperature | Float | Input parameter. Tunes the degree of randomness in text generations. Should be a non-negative value. Default: `0`. |
|
||||
| top_k | Integer | Input parameter. How the model selects tokens for output. The next token is selected from the top `k` tokens. Default: `40`. |
|
||||
| top_p | Float | Input parameter. Tokens are selected from the most probable to least until the sum of their probabilities exceeds the top `p` value. Default: `0.95`. |
|
||||
| tuned_model_name | String | Input parameter. The name of a tuned model. If provided, `model_name` is ignored. |
|
||||
| verbose | Boolean | Input parameter. This parameter controls the level of detail in the output. When set to `True`, it prints internal states of the chain to help debug. Default: `False`. |
|
||||
| embeddings | Embeddings | Output parameter. An instance for generating embeddings using Vertex AI. |
|
||||
|
||||
## Create a service account for Vertex AI authentication {#vertexai-credentials}
|
||||
|
||||
The **Vertex AI Embeddings** and **Vertex AI** components authenticate with the [Google Vertex AI API](https://console.cloud.google.com/marketplace/product/google/aiplatform.googleapis.com) using a service account JSON file.
|
||||
|
||||
These components require that you provide a service account JSON file in the **Credentials** parameter (`credentials`).
|
||||
You can either provide the file directly in your component's settings or you can use a [`GOOGLE_APPLICATION_CREDENTIALS` environment variable](https://cloud.google.com/docs/authentication/application-default-credentials) to reference the path to your JSON file.
|
||||
|
||||
The following steps explain how to create a service account for Langflow, create a service account JSON key file, and then use the JSON key file in Langflow:
|
||||
|
||||
1. If you haven't done so already, [enable the Vertex AI APIs in your Google Cloud project](https://cloud.google.com/vertex-ai/docs/start/cloud-environment).
|
||||
|
||||
2. Create a [service account](https://cloud.google.com/iam/docs/service-account-overview) in your Google Cloud project.
|
||||
|
||||
It is recommended that you [create a custom service account for Vertex AI](https://cloud.google.com/vertex-ai/docs/general/custom-service-account) because Langflow uses this account to access the Vertex AI APIs.
|
||||
|
||||
3. Assign the **Vertex AI Service Agent** role to the service account.
|
||||
|
||||
This role allows Langflow to access Vertex AI resources.
|
||||
For more information, see [Vertex AI access control with IAM](https://cloud.google.com/vertex-ai/docs/general/access-control).
|
||||
|
||||
4. [Create a service account key](https://cloud.google.com/iam/docs/keys-create-delete#console) in JSON format for your Langflow Vertex AI service account.
|
||||
|
||||
When you click **Create**, the JSON key file is downloaded.
|
||||
|
||||
5. In Langflow, create or open a flow with the **Vertex AI** or **Vertex AI Embeddings** component.
|
||||
|
||||
6. In the component's **Credentials** field, do one of the following:
|
||||
|
||||
* Select your service account JSON file directly.
|
||||
|
||||
* Leave the **Credentials** field empty if you want to pull the key file from an environment variable.
|
||||
Then, you must provide the path to your JSON file in a `GOOGLE_APPLICATION_CREDENTIALS` environment variable that is set somewhere relative to your Langflow instance.
|
||||
For example, you can set the environment variable in your terminal, your Langflow `.env` file, or otherwise in the environment where your Langflow server or application runs.
|
||||
|
||||

|
||||
|
||||
7. Run your flow to verify that Langflow can use the service account credentials successfully.
|
||||
|
||||
For example, in a flow with **Chat Input**, **Chat Output**, and **Vertex AI** components, you can open the **Playground** and try chatting with the LLM.
|
||||
If the LLM responds, then the credentials are configured correctly.
|
||||
43
docs/docs/Components/bundles-wikipedia.mdx
Normal file
43
docs/docs/Components/bundles-wikipedia.mdx
Normal file
|
|
@ -0,0 +1,43 @@
|
|||
---
|
||||
title: Wikipedia
|
||||
slug: /bundles-wikipedia
|
||||
---
|
||||
|
||||
import Icon from "@site/src/components/icon";
|
||||
|
||||
[Bundles](/components-bundle-components) contain custom components that support specific third-party integrations with Langflow.
|
||||
|
||||
This page describes the components that are available in the **Wikipedia** bundle.
|
||||
|
||||
:::tip
|
||||
Wikipedia components are useful [tools for agents](/agents-tools) that need reliable sources for information retrieval, such as tutoring chatbots or generic research assistants.
|
||||
|
||||
Rather than broad internet searches or recall from internal model data, these components provide specific data returned from Wikipedia API requests.
|
||||
:::
|
||||
|
||||
## Wikidata API
|
||||
|
||||
This component performs a similarity search using the [Wikidata API](https://www.wikidata.org/wiki/Wikidata:REST_API).
|
||||
|
||||
It accepts a string text query, and it outputs a [`DataFrame`](/data-types#dataframe) containing the search results.
|
||||
|
||||
## Wikipedia API
|
||||
|
||||
This component searches and retrieves information from Wikipedia with the [WikiMedia API](https://www.mediawiki.org/wiki/API:Main_page) search endpoints, and then outputs the response as a [`DataFrame`](/data-types#dataframe).
|
||||
|
||||
### Wikipedia API parameters
|
||||
|
||||
Some **Wikipedia API** component input parameters are hidden by default in the visual editor.
|
||||
You can toggle parameters through the <Icon name="SlidersHorizontal" aria-hidden="true"/> **Controls** in the [component's header menu](/concepts-components#component-menus).
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| input_value | String | Input parameter. The search query input. |
|
||||
| lang | String | Input parameter. The language code for Wikipedia. Default: `en`. |
|
||||
| k | Integer | Input parameter. The number of results to return. |
|
||||
| load_all_available_meta | Boolean | Input parameter. Whether to load all available metadata. |
|
||||
| doc_content_chars_max | Integer | Input parameter. The maximum number of characters for document content. |
|
||||
|
||||
## See also
|
||||
|
||||
* [**API Request** component](/components-data#api-request)
|
||||
38
docs/docs/Components/bundles-xai.mdx
Normal file
38
docs/docs/Components/bundles-xai.mdx
Normal file
|
|
@ -0,0 +1,38 @@
|
|||
---
|
||||
title: xAI
|
||||
slug: /bundles-xai
|
||||
---
|
||||
|
||||
import Icon from "@site/src/components/icon";
|
||||
|
||||
[Bundles](/components-bundle-components) contain custom components that support specific third-party integrations with Langflow.
|
||||
|
||||
This page describes the components that are available in the **xAI** bundle.
|
||||
|
||||
For more information about xAI features and functionality used by xAI components, see the [xAI documentation](https://x.ai/).
|
||||
|
||||
## xAI text generation
|
||||
|
||||
The **xAI** component generates text using xAI models like [Grok](https://x.ai/grok).
|
||||
|
||||
It can output either a **Model Response** ([`Message`](/data-types#message)) or a **Language Model** ([`LanguageModel`](/data-types#languagemodel)).
|
||||
|
||||
Use the **Language Model** output when you want to use an xAI model as the LLM for another LLM-driven component, such as a **Language Model** or **Smart Function** component.
|
||||
|
||||
For more information, see [**Language Model** components](/components-models).
|
||||
|
||||
### xAI text generation parameters
|
||||
|
||||
Many **xAI** component input parameters are hidden by default in the visual editor.
|
||||
You can toggle parameters through the <Icon name="SlidersHorizontal" aria-hidden="true"/> **Controls** in the [component's header menu](/concepts-components#component-menus).
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| max_tokens | Integer | Input parameter. Maximum number of tokens to generate. Set to `0` for unlimited. Range: `0-128000`. |
|
||||
| model_kwargs | Dictionary | Input parameter. Additional keyword arguments for the model. |
|
||||
| json_mode | Boolean | Input parameter. If `True`, outputs JSON regardless of passing a schema. |
|
||||
| model_name | String | Input parameter. The xAI model to use. Default: `grok-2-latest`. |
|
||||
| base_url | String | Input parameter. Base URL for API requests. Default: `https://api.x.ai/v1`. |
|
||||
| api_key | SecretString | Input parameter. Your xAI API key for authentication. |
|
||||
| temperature | Float | Input parameter. Controls randomness in the output. Range: `[0.0, 2.0]`. Default: `0.1`. |
|
||||
| seed | Integer | Input parameter. Controls reproducibility of the job. |
|
||||
|
|
@ -3,137 +3,178 @@ title: Agents
|
|||
slug: /components-agents
|
||||
---
|
||||
|
||||
# Agent components in Langflow
|
||||
Langflow's **Agent** and **MCP Tools** components are critical for building agentic flows.
|
||||
These components define the behavior and capabilities of AI agents in your flows.
|
||||
|
||||
Agent components define the behavior and capabilities of AI agents in your flow.
|
||||
<details>
|
||||
<summary>How agents work</summary>
|
||||
|
||||
Agents use LLMs as a reasoning engine to decide which of the connected tool components to use to solve a problem.
|
||||
Agents extend Large Language Models (LLMs) by integrating _tools_, which are functions that provide additional context and enable autonomous task execution.
|
||||
These integrations make agents more specialized and powerful than standalone LLMs.
|
||||
|
||||
Tools in agentic functions are essentially functions that the agent can call to perform tasks or access external resources.
|
||||
A function is wrapped as a `Tool` object with a common interface the agent understands.
|
||||
Agents become aware of tools through tool registration where the agent is provided a list of available tools typically at agent initialization. The `Tool` object's description tells the agent what the tool can do.
|
||||
Whereas an LLM might generate acceptable, inert responses to general queries and tasks, an agent can leverage the integrated context and tools to provide more relevant responses and even take action.
|
||||
For example, you might create an agent that can access your company's knowledge base, repositories, and other resources to help your team with tasks that require knowledge of your specific products, customers, and code.
|
||||
|
||||
The agent then uses a connected LLM to reason through the problem to decide which tool is best for the job.
|
||||
Agents use LLMs as a reasoning engine to process input, determine which actions to take to address the query, and then generate a response.
|
||||
The response could be a typical text-based LLM response, or it could involve an action, like editing a file, running a script, or calling an external API.
|
||||
|
||||
## Use an agent in a flow
|
||||
In an agentic context, tools are functions that the agent can run to perform tasks or access external resources.
|
||||
A function is wrapped as a `Tool` object with a common interface that the agent understands.
|
||||
Agents become aware of tools through tool registration, which is when the agent is provided a list of available tools typically at agent initialization.
|
||||
The `Tool` object's description tells the agent what the tool can do so that it can decide whether the tool is appropriate for a given request.
|
||||
|
||||
The [simple agent starter project](/simple-agent) uses an [agent component](#agent-component) connected to URL and Calculator tools to answer a user's questions. The OpenAI LLM acts as a brain for the agent to decide which tool to use. Tools are connected to agent components at the **Tools** port.
|
||||
</details>
|
||||
|
||||

|
||||
## Examples of agentic flows
|
||||
|
||||
For a multi-agent example see [Create a flow with an agent](/agents).
|
||||
For examples of agentic flows using the **Agent** and **MCP Tools** components, see the following:
|
||||
|
||||
* [**Simple Agent** template](/simple-agent): Create a basic agentic flow in Langflow with an **Agent** component that can use two other Langflow components as tools.
|
||||
The LLM specified in the **Agent** component's settings can use its own built-in functionality as well as the functionality provided by the connected tools when generating responses.
|
||||
|
||||
* [Langflow quickstart](/get-started-quickstart): Modify the **Simple Agent** template to use different tools, and then learn how to use an agentic flow in an application.
|
||||
|
||||
* [Use an agent as a tool](/agents-tools#use-an-agent-as-a-tool): Create a multi-agent flow.
|
||||
|
||||
* [Use Langflow as an MCP client](/mcp-client) and [Use Langflow as an MCP server](/mcp-server): Use the **Agent** and **MCP Tools** components to implement the Model Context Protocol (MCP) in your flows.
|
||||
|
||||
## Agent component {#agent-component}
|
||||
|
||||
This component creates an agent that can use tools to answer questions and perform tasks based on given instructions.
|
||||
The **Agent** component is the primary agent actor in your agentic flows.
|
||||
This component uses an LLM integration to respond to input, such as a chat message or file upload.
|
||||
|
||||
The component includes an LLM model integration, a system message prompt, and a **Tools** port to connect tools to extend its capabilities.
|
||||
The agent can use the tools already available in the base LLM model as well as additional tools that you connect to the **Agent** component's **Tools** port.
|
||||
You can connect any Langflow component as a tool, including other **Agent** components and MCP servers through the [**MCP Tools** component](#mcp-connection).
|
||||
|
||||
For more information on this component, see the [Agent documentation](/agents).
|
||||
For more information about using this component, see [Use Langflow agents](/agents).
|
||||
|
||||
## MCP Tools component {#mcp-connection}
|
||||
|
||||
The **MCP Tools** component connects to a [Model Context Protocol (MCP)](https://modelcontextprotocol.io/introduction) server and exposes the MCP server's functions as tools for Langflow agents to use to respond to input.
|
||||
|
||||
In addition to publicly available MCP servers and your own custom-built MCP servers, you can connect Langflow MCP servers, which allow your agent to use your Langflow flows as tools.
|
||||
To do this, use the **MCP Tools** component's [SSE mode](/mcp-client#mcp-sse-mode) to connect to your Langflow MCP server at the `/api/v1/mcp/sse` endpoint.
|
||||
|
||||
For more information about using this component and serving flows as MCP tools, see [Use Langflow as an MCP client](/mcp-client) and [Use Langflow as an MCP server](/mcp-server).
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
<summary>Earlier versions of the MCP Tools component</summary>
|
||||
|
||||
**Inputs**
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| agent_llm | Dropdown | The provider of the language model that the agent uses to generate responses. Options include OpenAI and other providers or Custom. |
|
||||
| system_prompt | String | The system prompt provides initial instructions and context to guide the agent's behavior. |
|
||||
| tools | List | The list of tools available for the agent to use. This field is optional and can be empty. |
|
||||
| input_value | String | The input task or question for the agent to process. |
|
||||
| add_current_date_tool | Boolean | When true this adds a tool to the agent that returns the current date. |
|
||||
| memory | Memory | An optional memory configuration for maintaining conversation history. |
|
||||
| max_iterations | Integer | The maximum number of iterations the agent can perform. |
|
||||
| handle_parsing_errors | Boolean | This determines whether to handle parsing errors during agent execution. |
|
||||
| verbose | Boolean | This enables verbose output for detailed logging. |
|
||||
|
||||
**Outputs**
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| response | Message | The agent's response to the given input task. |
|
||||
* In Langflow version 1.5, the **MCP Connection** component was renamed to the **MCP Tools** component.
|
||||
* In Langflow version 1.3, the **MCP Tools (stdio)** and **MCP Tools (SSE)** components were deprecated and replaced by the unified **MCP Connection** component, which was later renamed to **MCP Tools**.
|
||||
|
||||
</details>
|
||||
|
||||
## MCP tools {#mcp-connection}
|
||||
## Legacy agent components
|
||||
|
||||
:::important
|
||||
Prior to Langflow 1.5, this component was named **MCP connection**.
|
||||
:::
|
||||
The following components are legacy components.
|
||||
You can still use these components in your flows, but they are no longer maintained and they can be removed in future releases.
|
||||
|
||||
The **MCP tools** component connects to a [Model Context Protocol (MCP)](https://modelcontextprotocol.io/introduction) server and exposes the MCP server's tools as tools for Langflow agents.
|
||||
Replace these components with the **Agent** component or other Langflow components, depending on your use case.
|
||||
|
||||
In addition to being an MCP client that can leverage MCP servers, the **MCP tools** component's [SSE mode](/mcp-client#mcp-sse-mode) allows you to connect your flow to the Langflow MCP server at the `/api/v1/mcp/sse` API endpoint, exposing all flows within your [project](/concepts-flows#projects) as tools within a flow.
|
||||
|
||||
For more information, see [MCP client](/mcp-client).
|
||||
|
||||
## Legacy components
|
||||
|
||||
**Legacy** components are available for use but are no longer supported.
|
||||
|
||||
### JSON Agent
|
||||
|
||||
This component creates a JSON agent from a JSON or YAML file and an LLM.
|
||||
* **CrewAI Hierarchical Task**
|
||||
* **CrewAI Sequential Task**
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
<summary>CrewAI Agent</summary>
|
||||
|
||||
**Inputs**
|
||||
This component represents CrewAI agents, allowing for the creation of specialized AI agents with defined roles goals and capabilities within a crew.
|
||||
For more information, see the [CrewAI agents documentation](https://docs.crewai.com/core-concepts/Agents/).
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| llm | LanguageModel | The language model to use for the agent. |
|
||||
| path | File | The path to the JSON or YAML file. |
|
||||
This component accepts the following parameters:
|
||||
|
||||
**Outputs**
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| agent | AgentExecutor | The JSON agent instance. |
|
||||
| Name | Display Name | Info |
|
||||
|------|--------------|------|
|
||||
| role | Role | Input parameter. The role of the agent. |
|
||||
| goal | Goal | Input parameter. The objective of the agent. |
|
||||
| backstory | Backstory | Input parameter. The backstory of the agent. |
|
||||
| tools | Tools | Input parameter. The tools at the agent's disposal. |
|
||||
| llm | Language Model | Input parameter. The language model that runs the agent. |
|
||||
| memory | Memory | Input parameter. This determines whether the agent should have memory or not. |
|
||||
| verbose | Verbose | Input parameter. This enables verbose output. |
|
||||
| allow_delegation | Allow Delegation | Input parameter. This determines whether the agent is allowed to delegate tasks to other agents. |
|
||||
| allow_code_execution | Allow Code Execution | Input parameter. This determines whether the agent is allowed to execute code. |
|
||||
| kwargs | kwargs | Input parameter. Additional keyword arguments for the agent. |
|
||||
| output | Agent | Output parameter. The constructed CrewAI Agent object. |
|
||||
|
||||
</details>
|
||||
|
||||
### Vector Store Agent
|
||||
|
||||
This component creates a Vector Store Agent using LangChain.
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
<summary>CrewAI Hierarchical Crew</summary>
|
||||
|
||||
**Inputs**
|
||||
This component represents a group of agents managing how they should collaborate and the tasks they should perform in a hierarchical structure. This component allows for the creation of a crew with a manager overseeing the task execution.
|
||||
For more information, see the [CrewAI hierarchical crew documentation](https://docs.crewai.com/how-to/Hierarchical/).
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| llm | LanguageModel | The language model to use for the agent. |
|
||||
| vectorstore | VectorStoreInfo | The vector store information for the agent to use. |
|
||||
It accepts the following parameters:
|
||||
|
||||
**Outputs**
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| agent | AgentExecutor | The Vector Store Agent instance. |
|
||||
| Name | Display Name | Info |
|
||||
|------|--------------|------|
|
||||
| agents | Agents | Input parameter. The list of Agent objects representing the crew members. |
|
||||
| tasks | Tasks | Input parameter. The list of HierarchicalTask objects representing the tasks to be executed. |
|
||||
| manager_llm | Manager LLM | Input parameter. The language model for the manager agent. |
|
||||
| manager_agent | Manager Agent | Input parameter. The specific agent to act as the manager. |
|
||||
| verbose | Verbose | Input parameter. This enables verbose output for detailed logging. |
|
||||
| memory | Memory | Input parameter. The memory configuration for the crew. |
|
||||
| use_cache | Use Cache | Input parameter. This enables caching of results. |
|
||||
| max_rpm | Max RPM | Input parameter. This sets the maximum requests per minute. |
|
||||
| share_crew | Share Crew | Input parameter. This determines if the crew information is shared among agents. |
|
||||
| function_calling_llm | Function Calling LLM | Input parameter. The language model for function calling. |
|
||||
| crew | Crew | Output parameter. The constructed Crew object with hierarchical task execution. |
|
||||
|
||||
</details>
|
||||
|
||||
### Vector Store Router Agent
|
||||
<details>
|
||||
<summary>CrewAI Sequential Crew</summary>
|
||||
|
||||
This component creates a Vector Store Router Agent using LangChain.
|
||||
This component represents a group of agents with tasks that are executed sequentially. This component allows for the creation of a crew that performs tasks in a specific order.
|
||||
For more information, see the [CrewAI sequential crew documentation](https://docs.crewai.com/how-to/Sequential/).
|
||||
|
||||
It accepts the following parameters:
|
||||
|
||||
| Name | Display Name | Info |
|
||||
|------|--------------|------|
|
||||
| tasks | Tasks | Input parameter. The list of SequentialTask objects representing the tasks to be executed. |
|
||||
| verbose | Verbose | Input parameter. This enables verbose output for detailed logging. |
|
||||
| memory | Memory | Input parameter. The memory configuration for the crew. |
|
||||
| use_cache | Use Cache | Input parameter. This enables caching of results. |
|
||||
| max_rpm | Max RPM | Input parameter. This sets the maximum requests per minute. |
|
||||
| share_crew | Share Crew | Input parameter. This determines if the crew information is shared among agents. |
|
||||
| function_calling_llm | Function Calling LLM | Input parameter. The language model for function calling. |
|
||||
| crew | Crew | Output parameter. The constructed Crew object with sequential task execution. |
|
||||
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
<summary>CrewAI Sequential Task Agent</summary>
|
||||
|
||||
**Inputs**
|
||||
This component creates a CrewAI Task and its associated Agent allowing for the definition of sequential tasks with specific agent roles and capabilities.
|
||||
For more information, see the [CrewAI sequential agents documentation](https://docs.crewai.com/how-to/Sequential/).
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| llm | LanguageModel | The language model to use for the agent. |
|
||||
| vectorstores | List[VectorStoreInfo] | The list of vector store information for the agent to route between. |
|
||||
It accepts the following parameters:
|
||||
|
||||
**Outputs**
|
||||
| Name | Display Name | Info |
|
||||
|------|--------------|------|
|
||||
| role | Role | Input parameter. The role of the agent. |
|
||||
| goal | Goal | Input parameter. The objective of the agent. |
|
||||
| backstory | Backstory | Input parameter. The backstory of the agent. |
|
||||
| tools | Tools | Input parameter. The tools at the agent's disposal. |
|
||||
| llm | Language Model | Input parameter. The language model that runs the agent. |
|
||||
| memory | Memory | Input parameter. This determines whether the agent should have memory or not. |
|
||||
| verbose | Verbose | Input parameter. This enables verbose output. |
|
||||
| allow_delegation | Allow Delegation | Input parameter. This determines whether the agent is allowed to delegate tasks to other agents. |
|
||||
| allow_code_execution | Allow Code Execution | Input parameter. This determines whether the agent is allowed to execute code. |
|
||||
| agent_kwargs | Agent kwargs | Input parameter. The additional kwargs for the agent. |
|
||||
| task_description | Task Description | Input parameter. The descriptive text detailing the task's purpose and execution. |
|
||||
| expected_output | Expected Task Output | Input parameter. The clear definition of the expected task outcome. |
|
||||
| async_execution | Async Execution | Input parameter. The boolean flag indicating asynchronous task execution. |
|
||||
| previous_task | Previous Task | Input parameter. The previous task in the sequence for chaining. |
|
||||
| task_output | Sequential Task | Output parameter. The list of SequentialTask objects representing the created tasks. |
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| agent | AgentExecutor | The Vector Store Router Agent instance. |
|
||||
</details>
|
||||
|
||||
</details>
|
||||
## See also
|
||||
|
||||
* [**Message History** component](/components-helpers#message-history)
|
||||
* [Store chat memory](/memory#store-chat-memory)
|
||||
* [Bundles](/components-bundle-components)
|
||||
* [Legacy LangChain components](/bundles-langchain#legacy-langchain-components)
|
||||
File diff suppressed because it is too large
Load diff
|
|
@ -5,576 +5,520 @@ slug: /components-data
|
|||
|
||||
import Icon from "@site/src/components/icon";
|
||||
|
||||
# Data components in Langflow
|
||||
You can use Langflow's data components to bring data into your flows from various sources like files, API endpoints, and URLs.
|
||||
For example:
|
||||
|
||||
Data components load data from a source into your flow.
|
||||
* **Load files**: Import data from a file or directory with the [**File**](#file) and [**Directory**](#directory) components.
|
||||
|
||||
They may perform some processing or type checking, like converting raw HTML data into text, or ensuring your loaded file is of an acceptable type.
|
||||
* **Search the web**: Fetch data from the web with components like the [**News Search**](#news-search), [**RSS Reader**](#rss-reader), [**Web Search**](#web-search), and [**URL**](#url) components.
|
||||
|
||||
## Use data components in a flow
|
||||
* **Make API calls**: Use APIs to trigger flows or perform actions with the [**API Request**](#api-request) and [**Webhook**](#webhook) components.
|
||||
|
||||
Components like [News search](#news-search), [RSS reader](#rss-reader), and [Web search](#web-search) all fetch data into Langflow, and connect to Langflow in the same way. They can output the retrieved data in [DataFrame](/data-types#dataframe) format, or can be connected to an **Agent** component to be used as tools.
|
||||
* **Run SQL queries**: Query an SQL database with the [**SQL Database**](#sql-database) component.
|
||||
|
||||
For example, to connect all three components to an Agent component, do the following:
|
||||
Each component runs different commands for retrieval, processing, and type checking.
|
||||
Some components are a minimal wrapper for a command that you provide, and others include built-in scripts to fetch and process data based on variable inputs.
|
||||
Additionally, some components return raw data, whereas others can convert, restructure, or validate the data before outputting it.
|
||||
This means that some similar components might produce different results.
|
||||
|
||||
1. Create the [Simple Agent starter flow](/simple-agent).
|
||||
2. In the **Agent** component, in the **OpenAI API Key** field, add your OpenAI API key.
|
||||
3. Add the **News search**, **RSS reader**, and **Web Search** components to your flow.
|
||||
4. In all three components, enable **Tool Mode**.
|
||||
5. Connect the three components to the **Agent** component's **Tools** port.
|
||||
The flow looks like the following:
|
||||
:::tip
|
||||
Data components pair well with [processing components](/components-processing) that can perform additional parsing, transformation, and validation after retrieving the data.
|
||||
|
||||

|
||||
This can include basic operations, like saving a file in a specific format, or more complex tasks, like using a **Text Splitter** component to break down a large document into smaller chunks before generating embeddings for vector search.
|
||||
:::
|
||||
|
||||
6. Open the **Playground** and enter `Use the websearch component to get me an RSS feed of the latest news.`
|
||||
The Agent uses the `perform_search` tool to return a list of RSS feeds.
|
||||
7. Enter the name of an RSS feed that interests you.
|
||||
The Agent uses the `read_rss` tool to fetch and summarize the latest RSS feed.
|
||||
## Use data components in flows
|
||||
|
||||
Data components are used often in flows because they offer a versatile way to perform common, basic functions.
|
||||
|
||||
You can use data components to perform their base functions as isolated steps in your flow, or you can connect them to an **Agent** component as tools.
|
||||
|
||||

|
||||
|
||||
For examples of data components in flows, see the following:
|
||||
|
||||
* [Create a chatbot that can ingest files](/chat-with-files): Learn how to use a **File** component to load a file as context for a chatbot.
|
||||
The file and user input are both passed to the LLM so you can ask questions about the file you uploaded.
|
||||
|
||||
* [Create a vector RAG chatbot](/chat-with-rag): Learn how to ingest files for use in Retrieval-Augmented Generation (RAG), and then set up a chatbot that can use the ingested files as context.
|
||||
The two flows in this tutorial prepare files for RAG, and then let your LLM use vector search to retrieve contextually relevant data during a chat session.
|
||||
|
||||
* [Configure tools for agents](/agents-tools): Learn how to use any component as a tool for an agent.
|
||||
When used as tools, the agent autonomously decides when to call a component based on the user's query.
|
||||
|
||||
* [Trigger flows with webhooks](/webhook): Learn how to use the **Webhook** component to trigger a flow run in response to an external event.
|
||||
|
||||
## API Request
|
||||
|
||||
This component makes HTTP requests using URLs or cURL commands.
|
||||
The **API Request** component constructs and sends an HTTP requests using URLs or curl commands:
|
||||
|
||||
1. To use this component in a flow, connect the **Data** output to a component that accepts the input.
|
||||
For example, connect the **API Request** component to a **Chat Output** component.
|
||||
* **URL mode**: Enter one or more comma-separated URLs, and then select the method for the request to each URL.
|
||||
* **curl mode**: Enter the curl command to execute.
|
||||
|
||||
2. In the API component's **URLs** field, enter the endpoint for your request.
|
||||
This example uses `https://dummy-json.mock.beeceptor.com/posts`, which is a list of technology blog posts.
|
||||
You can enable additional request options and fields in the component's parameters.
|
||||
|
||||
3. In the **Method** field, enter the type of request.
|
||||
This example uses GET to retrieve a list of blog posts.
|
||||
The component also supports POST, PATCH, PUT, and DELETE.
|
||||
Returns a [`Data` object](/data-types#data) containing the response.
|
||||
|
||||
4. Optionally, enable the **Use cURL** button to create a field for pasting curl requests.
|
||||
The equivalent call in this example is `curl -v https://dummy-json.mock.beeceptor.com/posts`.
|
||||
For provider-specific API components, see [Bundles](/components-bundle-components).
|
||||
|
||||
5. Click **Playground**, and then click **Run Flow**.
|
||||
Your request returns a list of blog posts in the `result` field.
|
||||
### API Request parameters
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
|
||||
**Inputs**
|
||||
Most **API Request** component input parameters are hidden by default in the visual editor.
|
||||
You can toggle parameters through the <Icon name="SlidersHorizontal" aria-hidden="true"/> **Controls** in the [component's header menu](/concepts-components#component-menus).
|
||||
|
||||
| Name | Display Name | Info |
|
||||
|------|--------------|------|
|
||||
| urls | URLs | Enter one or more URLs, separated by commas. |
|
||||
| curl | cURL | Paste a curl command to populate the dictionary fields for headers and body. |
|
||||
| method | Method | The HTTP method to use. |
|
||||
| use_curl | Use cURL | Enable cURL mode to populate fields from a cURL command. |
|
||||
| query_params | Query Parameters | The query parameters to append to the URL. |
|
||||
| body | Body | The body to send with the request as a dictionary (for `POST`, `PATCH`, `PUT`). |
|
||||
| headers | Headers | The headers to send with the request as a dictionary. |
|
||||
| timeout | Timeout | The timeout to use for the request. |
|
||||
| follow_redirects | Follow Redirects | Whether to follow http redirects. |
|
||||
| save_to_file | Save to File | Save the API response to a temporary file. |
|
||||
| include_httpx_metadata | Include HTTPx Metadata | Include properties such as `headers`, `status_code`, `response_headers`, and `redirection_history` in the output. |
|
||||
|
||||
**Outputs**
|
||||
|
||||
| Name | Display Name | Info |
|
||||
|------|--------------|------|
|
||||
| data | Data | The result of the API requests. Returns a Data object containing source URL and results. |
|
||||
| dataframe | DataFrame | Converts the API response data into a tabular DataFrame format. |
|
||||
|
||||
</details>
|
||||
| mode | Mode | Input parameter. Set the mode to either **URL** or **curl**. |
|
||||
| urls | URL | Input parameter. Enter one or more comma-separated URLs for the request. |
|
||||
| curl | cURL | Input parameter. **curl mode** only. Enter a complete curl command. Other component parameters are populated from the command arguments. |
|
||||
| method | Method | Input parameter. The HTTP method to use. |
|
||||
| query_params | Query Parameters | Input parameter. The query parameters to append to the URL. |
|
||||
| body | Body | Input parameter. The body to send with POST, PATCH, and PUT requests as a dictionary. |
|
||||
| headers | Headers | Input parameter. The headers to send with the request as a dictionary. |
|
||||
| timeout | Timeout | Input parameter. The timeout to use for the request. |
|
||||
| follow_redirects | Follow Redirects | Input parameter. Whether to follow http redirects. Default: Enabled/true |
|
||||
| save_to_file | Save to File | Input parameter. Whether to save the API response to a temporary file. Default: Disabled/false |
|
||||
| include_httpx_metadata | Include HTTPx Metadata | Input parameter. Whether to include properties such as `headers`, `status_code`, `response_headers`, and `redirection_history` in the output. Default: Disabled/false |
|
||||
|
||||
## Directory
|
||||
|
||||
This component recursively loads files from a directory, with options for file types, depth, and concurrency.
|
||||
The **Directory** component recursively loads files from a directory, with options for file types, depth, and concurrency.
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
Files must be of a [supported type and size](#file-type-and-size-limits) to be loaded.
|
||||
|
||||
**Inputs**
|
||||
Outputs either a [`Data`](/data-types#data) or [`DataFrame`](/data-types#dataframe) object, depending on the directory contents.
|
||||
|
||||
| Input | Type | Description |
|
||||
### Directory parameters
|
||||
|
||||
Many **Directory** component input parameters are hidden by default in the visual editor.
|
||||
You can toggle parameters through the <Icon name="SlidersHorizontal" aria-hidden="true"/> **Controls** in the [component's header menu](/concepts-components#component-menus).
|
||||
|
||||
| Name | Type | Description |
|
||||
| ------------------ | ---------------- | -------------------------------------------------- |
|
||||
| path | MessageTextInput | The path to the directory to load files from. |
|
||||
| types | MessageTextInput | The file types to load (leave empty to load all types). |
|
||||
| depth | IntInput | The depth to search for files. |
|
||||
| max_concurrency | IntInput | The maximum concurrency for loading files. |
|
||||
| load_hidden | BoolInput | If true, hidden files are loaded. |
|
||||
| recursive | BoolInput | If true, the search is recursive. |
|
||||
| silent_errors | BoolInput | If true, errors do not raise an exception. |
|
||||
| use_multithreading | BoolInput | If true, multithreading is used. |
|
||||
|
||||
**Outputs**
|
||||
|
||||
| Output | Type | Description |
|
||||
| ------ | ---------- | ----------------------------------- |
|
||||
| data | List[Data] | The loaded file data from the directory. |
|
||||
| dataframe | DataFrame | The loaded file data in tabular DataFrame format. |
|
||||
|
||||
</details>
|
||||
| path | MessageTextInput | Input parameter. The path to the directory to load files from. Default: Current directory (`.`) |
|
||||
| types | MessageTextInput | Input parameter. The file types to load. Select one or more, or leave empty to attempt to load all files. |
|
||||
| depth | IntInput | Input parameter. The depth to search for files. |
|
||||
| max_concurrency | IntInput | Input parameter. The maximum concurrency for loading multiple files. |
|
||||
| load_hidden | BoolInput | Input parameter. If true, hidden files are loaded. |
|
||||
| recursive | BoolInput | Input parameter. If true, the search is recursive. |
|
||||
| silent_errors | BoolInput | Input parameter. If true, errors do not raise an exception. |
|
||||
| use_multithreading | BoolInput | Input parameter. If true, multithreading is used. |
|
||||
|
||||
## File
|
||||
|
||||
This component loads and parses files of various supported formats and converts the content into a [Data](/data-types#data) object. It supports multiple file types and provides options for parallel processing and error handling.
|
||||
The **File** component loads and parses files, converts the content into a `Data`, `DataFrame`, or `Message` object.
|
||||
It supports multiple file types and provides parameters for parallel processing and error handling.
|
||||
|
||||
To load a document, follow these steps:
|
||||
You can add files to the **File** component in the visual editor or at runtime, and you can upload multiple files at once.
|
||||
For more information about uploading files and working with files in flows, see [File management](/concepts-file-management) and [Create a chatbot that can ingest files](/chat-with-files).
|
||||
|
||||
1. Click the **Select files** button.
|
||||
2. Select a local file or a file loaded with [File management](/concepts-file-management), and then click **Select file**.
|
||||
### File type and size limits
|
||||
|
||||
The loaded file name appears in the component.
|
||||
|
||||
The default maximum supported file size is 100 MB.
|
||||
To modify this value, see [--max-file-size-upload](/environment-variables#LANGFLOW_MAX_FILE_SIZE_UPLOAD).
|
||||
|
||||
The **File** component’s outputs change dynamically based on the number and type of files you select.
|
||||
For more information, expand the following **Parameters** section, and then review the **Outputs** parameters.
|
||||
By default, the maximum file size is 100 MB.
|
||||
To modify this value, change the [`--max-file-size-upload` environment variable](/environment-variables#LANGFLOW_MAX_FILE_SIZE_UPLOAD).
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
<summary>Supported file types</summary>
|
||||
|
||||
**Inputs**
|
||||
The following file types are supported by the **File** component.
|
||||
Use archive and compressed formats to bundle multiple files together, or use the [**Directory** component](#directory) to load all files in a directory.
|
||||
|
||||
| Name | Display Name | Info |
|
||||
|------|--------------|------|
|
||||
| path | Files | The path to files to load. Supports individual files or bundled archives. |
|
||||
| file_path | Server File Path | A Data object with a `file_path` property pointing to the server file or a Message object with a path to the file. Supersedes 'Path' but supports the same file types. |
|
||||
| separator | Separator | The separator to use between multiple outputs in Message format. |
|
||||
| silent_errors | Silent Errors | If true, errors do not raise an exception. |
|
||||
| delete_server_file_after_processing | Delete Server File After Processing | If true, the Server File Path is deleted after processing. |
|
||||
| ignore_unsupported_extensions | Ignore Unsupported Extensions | If true, files with unsupported extensions are not processed. |
|
||||
| ignore_unspecified_files | Ignore Unspecified Files | If true, `Data` with no `file_path` property is ignored. |
|
||||
| use_multithreading | [Deprecated] Use Multithreading | Set 'Processing Concurrency' greater than `1` to enable multithreading. This option is deprecated. |
|
||||
| concurrency_multithreading | Processing Concurrency | When multiple files are being processed, the number of files to process concurrently. Default is 1. Values greater than 1 enable parallel processing for 2 or more files. |
|
||||
|
||||
**Outputs**
|
||||
|
||||
The outputs change dynamically based on the number and type of files selected.
|
||||
|
||||
If a single file is selected:
|
||||
- **Structured Content** [DataFrame](/data-types#dataframe): If a CSV or Excel file is selected, the component outputs tabular data.
|
||||
- **Structured Content** [Data](/data-types#data): If a JSON file is selected, the component outputs parsed JSON data.
|
||||
- **Raw Content** [Message](/data-types#message): Outputs the file's raw text content.
|
||||
- **File Path** [Message](/data-types#message): Outputs the path to the file on the Langflow server.
|
||||
|
||||
If multiple files are selected:
|
||||
- **Files** [DataFrame](/data-types#dataframe): A table containing the content and metadata of all selected files.
|
||||
|
||||
If no files are selected:
|
||||
- No outputs are displayed.
|
||||
- `.bz2`
|
||||
- `.csv`
|
||||
- `.docx`
|
||||
- `.gz`
|
||||
- `.htm`
|
||||
- `.html`
|
||||
- `.json`
|
||||
- `.js`
|
||||
- `.md`
|
||||
- `.mdx`
|
||||
- `.pdf`
|
||||
- `.py`
|
||||
- `.sh`
|
||||
- `.sql`
|
||||
- `.tar`
|
||||
- `.tgz`
|
||||
- `.ts`
|
||||
- `.tsx`
|
||||
- `.txt`
|
||||
- `.xml`
|
||||
- `.yaml`
|
||||
- `.yml`
|
||||
- `.zip`
|
||||
|
||||
</details>
|
||||
|
||||
### Supported File Types
|
||||
If you need to load an unsupported file type, you must use a different component that supports that file type and, potentially, parses it outside Langflow, or you must convert it to a supported type before uploading it.
|
||||
|
||||
Text files:
|
||||
- `.txt` - Text files
|
||||
- `.md`, `.mdx` - Markdown files
|
||||
- `.csv` - CSV files
|
||||
- `.json` - JSON files
|
||||
- `.yaml`, `.yml` - YAML files
|
||||
- `.xml` - XML files
|
||||
- `.html`, `.htm` - HTML files
|
||||
- `.pdf` - PDF files
|
||||
- `.docx` - Word documents
|
||||
- `.py` - Python files
|
||||
- `.sh` - Shell scripts
|
||||
- `.sql` - SQL files
|
||||
- `.js` - JavaScript files
|
||||
- `.ts`, `.tsx` - TypeScript files
|
||||
For images, see [Upload images](/concepts-file-management#upload-images).
|
||||
|
||||
Archive formats (for bundling multiple files):
|
||||
- `.zip` - ZIP archives
|
||||
- `.tar` - TAR archives
|
||||
- `.tgz` - Gzipped TAR archives
|
||||
- `.bz2` - Bzip2 compressed files
|
||||
- `.gz` - Gzip compressed files
|
||||
For videos, see the **Twelve Labs** and **YouTube** [bundles](/components-bundle-components) in the Langflow **Components** menu.
|
||||
|
||||
## News search
|
||||
### File parameters
|
||||
|
||||
This component searches Google News with RSS and returns clean article data. The `clean_html` method parses the HTML content with the BeautifulSoup library, and then removes HTML markup and strips whitespace so the output data is clean.
|
||||
|
||||
It returns news content as a DataFrame containing article titles, links, publication dates, and summaries. The component can also be used in **Tool Mode** with a connected **Agent**.
|
||||
|
||||
To use this component in a flow, connect the **News Search** output to a component that accepts the DataFrame input.
|
||||
For example, connect the **News Search** component to a **Chat Output** component. Enter a search query, open the Playground, and click **Run Flow**.
|
||||
|
||||
The latest content is returned in a structured DataFrame, with the key columns `title`, `link`, `published` and `summary`.
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
|
||||
**Inputs**
|
||||
Most **File** component input parameters are hidden by default in the visual editor.
|
||||
You can toggle parameters through the <Icon name="SlidersHorizontal" aria-hidden="true"/> **Controls** in the [component's header menu](/concepts-components#component-menus).
|
||||
|
||||
| Name | Display Name | Info |
|
||||
|------|--------------|------|
|
||||
| query | Search Query | Search keywords for news articles. |
|
||||
| hl | Language (hl) | Language code, such as en-US, fr, de. Default: `en-US`. |
|
||||
| gl | Country (gl) | Country code, such as US, FR, DE. Default: `US`. |
|
||||
| ceid | Country:Language (ceid) | Language, such as US:en, FR:fr. Default: `US:en`. |
|
||||
| topic | Topic | One of: WORLD, NATION, BUSINESS, TECHNOLOGY, ENTERTAINMENT, SCIENCE, SPORTS, HEALTH. |
|
||||
| location | Location (Geo) | City, state, or country for location-based news. Leave blank for keyword search. |
|
||||
| timeout | Timeout | Timeout for the request in seconds. |
|
||||
| path | Files | Input parameter. The path to files to load. Can be local or in [Langflow file management](/concepts-file-management). Supports individual files and bundled archives. |
|
||||
| file_path | Server File Path | Input parameter. A `Data` object with a `file_path` property pointing to a file in [Langflow file management](/concepts-file-management) or a `Message` object with a path to the file. Supersedes **Files** (`path`) but supports the same file types. |
|
||||
| separator | Separator | Input parameter. The separator to use between multiple outputs in `Message` format. |
|
||||
| silent_errors | Silent Errors | Input parameter. If true, errors in the component don't raise an exception. The default is false/disabled. |
|
||||
| delete_server_file_after_processing | Delete Server File After Processing | Input parameter. If true (default), the **Server File Path** (`file_path`) is deleted after processing. |
|
||||
| ignore_unsupported_extensions | Ignore Unsupported Extensions | Input parameter. If true/enabled (default), files with unsupported extensions are accepted but not processed. If false/disabled, the **File** component either can throw an error if an unsupported file type is provided. |
|
||||
| ignore_unspecified_files | Ignore Unspecified Files | Input parameter. If true, `Data` with no `file_path` property is ignored. If false (default), the component errors when a file is not specified. |
|
||||
| concurrency_multithreading | Processing Concurrency | Input parameter. The number of files to process concurrently if multiple files are uploaded. Default is 1. Values greater than 1 enable parallel processing for 2 or more files. |
|
||||
|
||||
**Outputs**
|
||||
### File output
|
||||
|
||||
The output of the **File** component depends on the number and type of files loaded:
|
||||
|
||||
- **No files**: Throws an error or, if **Silent Errors** is enabled, produces no output.
|
||||
|
||||
- **One file**: Produces one of the following depending on the file type. If multiple types are available, you can select the output type by clicking the output field (near the component's output port).
|
||||
|
||||
- **Structured Content**: Available for some tabular and structured data.
|
||||
For `.csv` files, produces a [`DataFrame`](/data-types#dataframe) representing the table data.
|
||||
For `.json` files, produces a [`Data`](/data-types#data) object with the parsed JSON data.
|
||||
- **Raw Content**: A [`Message`](/data-types#message) containing the file's raw text content.
|
||||
- **File Path**: A [`Message`](/data-types#message) containing the path to the file in [Langflow file management](/concepts-file-management).
|
||||
|
||||
- **Multiple files**: Produces a **Files** [`DataFrame`](/data-types#dataframe) containing the content and metadata of all selected files.
|
||||
|
||||
## News Search
|
||||
|
||||
The **News Search** component searches Google News through RSS, and then returns clean article data as a [`DataFrame`](/data-types#dataframe) containing article titles, links, publication dates, and summaries.
|
||||
The component's `clean_html` method parses the HTML content with the BeautifulSoup library, removes HTML markup, and strips whitespace to output clean data.
|
||||
|
||||
For other RSS feeds, use the [**RSS Reader** component](#rss-reader), and for other searches use the [**Web Search** component](#web-search) or a provider-specific [bundle](/components-bundle-components).
|
||||
|
||||
When used as a standard component in a flow, the **News Search** component must be connected to a component that accepts `DataFrame` input.
|
||||
You can connect the **News Search** component directly to a compatible component, or you can use a [processing component](/components-processing) to convert or extract data of a different type between components.
|
||||
|
||||
When used in **Tool Mode** with an **Agent** component, the **News Search** component can be connected directly to the **Agent** component's **Tools** port without converting the data.
|
||||
The agent decides whether to use the **News Search** component based on the user's query, and it can process the `DataFrame` output directly.
|
||||
|
||||
### News Search parameters
|
||||
|
||||
Most **News Search** component input parameters are hidden by default in the visual editor.
|
||||
You can toggle parameters through the <Icon name="SlidersHorizontal" aria-hidden="true"/> **Controls** in the [component's header menu](/concepts-components#component-menus).
|
||||
|
||||
| Name | Display Name | Info |
|
||||
|------|--------------|------|
|
||||
| articles | News Articles | A DataFrame containing article titles, links, publication dates, and summaries. |
|
||||
|
||||
</details>
|
||||
| query | Search Query | Input parameter. Search keywords for news articles. |
|
||||
| hl | Language (hl) | Input parameter. Language code, such as en-US, fr, de. Default: `en-US`. |
|
||||
| gl | Country (gl) | Input parameter. Country code, such as US, FR, DE. Default: `US`. |
|
||||
| ceid | Country:Language (ceid) | Input parameter. Language, such as US:en, FR:fr. Default: `US:en`. |
|
||||
| topic | Topic | Input parameter. One of: `WORLD`, `NATION`, `BUSINESS`, `TECHNOLOGY`, `ENTERTAINMENT`, `SCIENCE`, `SPORTS`, `HEALTH`. |
|
||||
| location | Location (Geo) | Input parameter. City, state, or country for location-based news. Leave blank for keyword search. |
|
||||
| timeout | Timeout | Input parameter. Timeout for the request in seconds. |
|
||||
| articles | News Articles | Output parameter. A `DataFrame` with the key columns `title`, `link`, `published` and `summary`. |
|
||||
|
||||
## RSS Reader
|
||||
|
||||
This component fetches and parses RSS feeds from any valid RSS feed URL. It returns the feed content as a DataFrame containing article titles, links, publication dates, and summaries. The component can also be used in **Tool Mode** with a connected **Agent**.
|
||||
The **RSS Reader** component fetches and parses RSS feeds from any valid RSS feed URL, and then returns the feed content as a [`DataFrame`](/data-types#dataframe) containing article titles, links, publication dates, and summaries.
|
||||
|
||||
To use this component in a flow, do the following:
|
||||
When used as a standard component in a flow, the **RSS Reader** component must be connected to a component that accepts `DataFrame` input.
|
||||
You can connect the **RSS Reader** component directly to a compatible component, or you can use a [processing component](/components-processing) to convert or extract data of a different type between components.
|
||||
|
||||
1. Connect the **RSS reader** output to a component that accepts the DataFrame input, such as a **Chat Output** component.
|
||||
2. In the **RSS Feed URL** field, enter an RSS feed, such as `https://rss.nytimes.com/services/xml/rss/nyt/HomePage.xml` for the New York Times.
|
||||
3. Open the **Playground**, and then click **Run Flow**.
|
||||
When used in **Tool Mode** with an **Agent** component, the **RSS Reader** component can be connected directly to the **Agent** component's **Tools** port without converting the data.
|
||||
The agent decides whether to use the **RSS Reader** component based on the user's query, and it can process the `DataFrame` output directly.
|
||||
|
||||
The latest content is returned in a structured DataFrame, with the key columns `title`, `link`, `published` and `summary`.
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
|
||||
**Inputs**
|
||||
### RSS Reader parameters
|
||||
|
||||
| Name | Display Name | Info |
|
||||
|------|--------------|------|
|
||||
| rss_url | RSS Feed URL | URL of the RSS feed to parse. |
|
||||
| timeout | Timeout | Timeout for the RSS feed request in seconds. Default: `5`. |
|
||||
| rss_url | RSS Feed URL | Input parameter. URL of the RSS feed to parse, such as `https://rss.nytimes.com/services/xml/rss/nyt/HomePage.xml`. |
|
||||
| timeout | Timeout | Input parameter. Timeout for the RSS feed request in seconds. Default: `5`. |
|
||||
| articles | Articles | Output parameter. A `DataFrame` containing the key columns `title`, `link`, `published` and `summary`. |
|
||||
|
||||
**Outputs**
|
||||
## SQL Database
|
||||
|
||||
The **SQL Database** component executes SQL queries on [SQLAlchemy-compatible databases](https://docs.sqlalchemy.org/en/20/).
|
||||
It supports any SQLAlchemy-compatible database, such as PostgreSQL, MySQL, and SQLite.
|
||||
|
||||
For CQL queries, see the [**DataStax** bundle](/bundles-datastax).
|
||||
|
||||
### Query an SQL database with natural language prompts
|
||||
|
||||
The following example demonstrates how to use the **SQL Database** component in a flow, and then modify the component to support natural language queries through an **Agent** component.
|
||||
|
||||
This allows you to use the same **SQL Database** component for any query, rather than limiting it to a single manually entered query or requiring the user, application, or another component to provide valid SQL syntax as input.
|
||||
Users don't need to master SQL syntax because the **Agent** component translates the users' natural language prompts into SQL queries, passes the query to the **SQL Database** component, and then returns the results to the user.
|
||||
|
||||
Additionally, input from applications and other components doesn't have to be extracted and transformed to exact SQL queries.
|
||||
Instead, you only need to provide enough context for the agent to understand that it should create and run a SQL query according to the incoming data.
|
||||
|
||||
1. Use your own sample database or create a test database.
|
||||
|
||||
<details>
|
||||
<summary>Create a test SQL database</summary>
|
||||
|
||||
1. Create a database called `test.db`:
|
||||
|
||||
```shell
|
||||
sqlite3 test.db
|
||||
```
|
||||
|
||||
2. Add some values to the database:
|
||||
|
||||
```shell
|
||||
sqlite3 test.db "
|
||||
CREATE TABLE users (
|
||||
id INTEGER PRIMARY KEY,
|
||||
name TEXT,
|
||||
email TEXT,
|
||||
age INTEGER
|
||||
);
|
||||
|
||||
INSERT INTO users (name, email, age) VALUES
|
||||
('John Doe', 'john@example.com', 30),
|
||||
('Jane Smith', 'jane@example.com', 25),
|
||||
('Bob Johnson', 'bob@example.com', 35);
|
||||
"
|
||||
```
|
||||
|
||||
3. Verify that the database has been created and contains your data:
|
||||
|
||||
```shell
|
||||
sqlite3 test.db "SELECT * FROM users;"
|
||||
```
|
||||
|
||||
The result should list the text data you entered in the previous step:
|
||||
|
||||
```shell
|
||||
1|John Doe|john@example.com
|
||||
2|Jane Smith|jane@example.com
|
||||
3|John Doe|john@example.com
|
||||
4|Jane Smith|jane@example.com
|
||||
```
|
||||
|
||||
</details>
|
||||
|
||||
2. Add an **SQL Database** component to your flow.
|
||||
|
||||
3. In the **Database URL** field, add the connection string for your database, such as `sqlite:///test.db`.
|
||||
|
||||
At this point, you can enter an SQL query in the **SQL Query** field or use the [port](/concepts-components#component-ports) to pass a query from another component, such as a **Chat Input** component.
|
||||
If you need more space, click <Icon name="Expand" aria-hidden="true"/> **Expand** to open a full-screen text field.
|
||||
|
||||
However, to make this component more dynamic in an agentic context, use an **Agent** component to transform natural language input to SQL queries, as explained in the following steps.
|
||||
|
||||
4. Click the **SQL Database** component to expose the [component's header menu](/concepts-components#component-menus), and then enable **Tool Mode**.
|
||||
|
||||
You can now use this component as a tool for an agent.
|
||||
In **Tool Mode**, no query is set in the **SQL Database** component because the agent will generate and send one if it determines that the tool is required to complete the user's request.
|
||||
For more information, see [Configure tools for agents](/agents-tools).
|
||||
|
||||
5. Add an **Agent** component to your flow, and then enter your OpenAI API key.
|
||||
|
||||
The default model is an OpenAI model.
|
||||
If you want to use a different model, edit the **Model Provider**, **Model Name**, and **API Key** fields accordingly.
|
||||
|
||||
If you need to execute highly specialized queries, consider selecting a model that is trained for tasks like advanced SQL queries.
|
||||
If your preferred model isn't in the **Agent** component's built-in model list, select the **Custom** model provider, and then use a [**Language Model** component](/components-models) to attach a specific model.
|
||||
|
||||
6. Connect the **SQL Database** component's **Toolset** output to the **Agent** component's **Tools** input.
|
||||
|
||||

|
||||
|
||||
7. Click **Playground**, and then ask the agent a question about the data in your database, such as `Which users are in my database?`
|
||||
|
||||
The agent determines that it needs to query the database to answer the question, uses the LLM to generate an SQL query, and then uses the **SQL Database** component's `RUN_SQL_QUERY` action to run the query on your database.
|
||||
Finally, it returns the results in a conversational format, unless you provide instructions to return raw results or a different format.
|
||||
|
||||
The following example queried a test database with little data, but with a more robust dataset you could ask more detailed or complex questions.
|
||||
|
||||
```text
|
||||
Here are the users in your database:
|
||||
|
||||
1. **John Doe** - Email: john@example.com
|
||||
2. **Jane Smith** - Email: jane@example.com
|
||||
3. **John Doe** - Email: john@example.com
|
||||
4. **Jane Smith** - Email: jane@example.com
|
||||
|
||||
It seems there are duplicate entries for the users.
|
||||
```
|
||||
|
||||
### SQL Database parameters
|
||||
|
||||
Some **SQL Database** component input parameters are hidden by default in the visual editor.
|
||||
You can toggle parameters through the <Icon name="SlidersHorizontal" aria-hidden="true"/> **Controls** in the [component's header menu](/concepts-components#component-menus).
|
||||
|
||||
| Name | Display Name | Info |
|
||||
|------|--------------|------|
|
||||
| articles | Articles | A DataFrame containing article titles, links, publication dates, and summaries. |
|
||||
|
||||
</details>
|
||||
|
||||
## SQL database
|
||||
|
||||
This component executes SQL queries on [SQLAlchemy-compatible databases](https://docs.sqlalchemy.org/en/20/).
|
||||
It supports any SQLAlchemy-compatible database, including PostgreSQL, MySQL, SQLite, and others.
|
||||
|
||||
To use this component in a flow, do the following:
|
||||
|
||||
1. Create a test database called `test.db`.
|
||||
```shell
|
||||
sqlite3 test.db
|
||||
```
|
||||
|
||||
2. Add values to the test database.
|
||||
```shell
|
||||
sqlite3 test.db "CREATE TABLE users (id INTEGER PRIMARY KEY, name TEXT, email TEXT, age INTEGER); INSERT INTO users (name, email, age) VALUES ('John Doe', 'john@example.com', 30), ('Jane Smith', 'jane@example.com', 25), ('Bob Johnson', 'bob@example.com', 35);"
|
||||
```
|
||||
|
||||
3. Verify that `test.db` has been created and contains your data.
|
||||
```shell
|
||||
sqlite3 test.db "SELECT * FROM users;"
|
||||
```
|
||||
|
||||
Result:
|
||||
```shell
|
||||
1|John Doe|john@example.com
|
||||
2|Jane Smith|jane@example.com
|
||||
3|John Doe|john@example.com
|
||||
4|Jane Smith|jane@example.com
|
||||
```
|
||||
|
||||
4. In the **SQL Database** component's **Database URL** field, add the connection string for `test.db`, such as `sqlite:///test.db`.
|
||||
|
||||
With this connection established, the **SQL Query** field now accepts SQL queries.
|
||||
Instead of manually entering SQL queries, connect this database to an agent as a **Tool** to query it with natural language.
|
||||
|
||||
5. In the **SQL Database** component, enable **Tool Mode**, and then connect it to an **Agent** component.
|
||||
The flow looks like the following:
|
||||
|
||||

|
||||
|
||||
6. In the **Agent** component, in the **OpenAI API Key** field, add your OpenAI API key.
|
||||
7. Open the **Playground** and ask `What users are in my database?`
|
||||
The Agent uses the `run_sql_query` tool to retrieve the information, and additionally identifies the duplicate `users` entries.
|
||||
|
||||
Result:
|
||||
```text
|
||||
Here are the users in your database:
|
||||
|
||||
1. **John Doe** - Email: john@example.com
|
||||
2. **Jane Smith** - Email: jane@example.com
|
||||
3. **John Doe** - Email: john@example.com
|
||||
4. **Jane Smith** - Email: jane@example.com
|
||||
|
||||
It seems there are duplicate entries for the users.
|
||||
|
||||
> Finished chain.
|
||||
```
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
|
||||
**Inputs**
|
||||
|
||||
| Name | Display Name | Info |
|
||||
|------|--------------|------|
|
||||
| database_url | Database URL | The SQLAlchemy-compatible database connection URL. |
|
||||
| query | SQL Query | The SQL query to execute. |
|
||||
| include_columns | Include Columns | If enabled, includes column names in the result. Default: `true`. |
|
||||
| add_error | Add Error | If enabled, adds any error messages to the result. Default: `false`. |
|
||||
|
||||
**Outputs**
|
||||
|
||||
| Name | Display Name | Info |
|
||||
|------|--------------|------|
|
||||
| run_sql_query | Result Table | The query results as a DataFrame. |
|
||||
|
||||
</details>
|
||||
|
||||
## Web search
|
||||
|
||||
This component performs web searches using DuckDuckGo's HTML interface, and returns the search results as a [DataFrame](/data-types#dataframe) containing the key columns `title`, `links`, and `snippets`. The component can also be used in **Tool Mode** with a connected **Agent**.
|
||||
|
||||
To use this component in a flow, do the following:
|
||||
|
||||
1. Add the **Web search** component to the [Basic prompting](/basic-prompting) flow. In the **Search Query** field, enter a query, such as `environmental news`.
|
||||
2. Connect the **Web search** component's output to a component that accepts the DataFrame input.
|
||||
3. Connect a **Type Convert** component to convert the DataFrame to a Message.
|
||||
4. In the **Type Convert** component, in the **Output Type** field, select **Message**.
|
||||
Your flow looks like the following:
|
||||
|
||||

|
||||
|
||||
5. In the **Language Model** component, in the **OpenAI API Key** field, add your OpenAI API key.
|
||||
6. Click **Playground**, and then ask about `latest news`.
|
||||
|
||||
The search results are returned to the Playground as a message.
|
||||
|
||||
Result:
|
||||
```text
|
||||
Latest news
|
||||
AI
|
||||
gpt-4o-mini
|
||||
Here are some of the latest news articles related to the environment:
|
||||
Ozone Pollution and Global Warming: A recent study highlights that ozone pollution is a significant global environmental concern, threatening human health and crop production while exacerbating global warming. Read more
|
||||
...
|
||||
```
|
||||
|
||||
:::note
|
||||
This component uses web scraping and may be subject to rate limits. For production use, consider using an official search API.
|
||||
:::
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
|
||||
**Inputs**
|
||||
|
||||
| Name | Display Name | Info |
|
||||
|------|--------------|------|
|
||||
| query | Search Query | Keywords to search for. |
|
||||
| timeout | Timeout | Timeout for the web search request in seconds. Default: `5`. |
|
||||
|
||||
**Outputs**
|
||||
|
||||
| Name | Display Name | Info |
|
||||
|------|--------------|------|
|
||||
| results | Search Results | A DataFrame containing search results with titles, links, and snippets. |
|
||||
|
||||
</details>
|
||||
| database_url | Database URL | Input parameter. The SQLAlchemy-compatible database connection URL. |
|
||||
| query | SQL Query | Input parameter. The SQL query to execute, which can be entered directly, passed in from another component, or, in **Tool Mode**, automatically provided by an **Agent** component. |
|
||||
| include_columns | Include Columns | Input parameter. If enabled, includes column names in the result. The default is enabled (`true`). |
|
||||
| add_error | Add Error | Input parameter. If enabled, adds any error messages to the result, if any are returned. The default is disabled (`false`). |
|
||||
| run_sql_query | Result Table | Output parameter. The query results as a [`DataFrame`](/data-types#dataframe). |
|
||||
|
||||
## URL
|
||||
|
||||
This component fetches content from one or more URLs, processes the content, and returns it in various formats. It supports output in plain text or raw HTML.
|
||||
The **URL** component fetches content from one or more URLs, processes the content, and returns it in various formats.
|
||||
It follows links recursively to a given depth, and it supports output in plain text or raw HTML.
|
||||
|
||||
In the component's **URLs** field, enter the URL you want to load. To add multiple URL fields, click <Icon name="Plus" aria-hidden="true"/> **Add URL**.
|
||||
### URL parameters
|
||||
|
||||
1. To use this component in a flow, connect the **DataFrame** output to a component that accepts the input.
|
||||
For example, connect the **URL** component to a **Chat Output** component.
|
||||
Most **URL** component input parameters are hidden by default in the visual editor.
|
||||
You can toggle parameters through the <Icon name="SlidersHorizontal" aria-hidden="true"/> **Controls** in the [component's header menu](/concepts-components#component-menus).
|
||||
|
||||
2. In the URL component's **URLs** field, enter the URL for your request.
|
||||
This example uses `langflow.org`.
|
||||
|
||||
3. Optionally, in the **Max Depth** field, enter how many pages away from the initial URL you want to crawl.
|
||||
Select `1` to crawl only the page specified in the **URLs** field.
|
||||
Select `2` to crawl all pages linked from that page.
|
||||
The component crawls by link traversal, not by URL path depth.
|
||||
|
||||
4. Click **Playground**, and then click **Run Flow**.
|
||||
The text contents of the URL are returned to the Playground as a structured DataFrame.
|
||||
|
||||
5. In the **URL** component, change the output port to **Message**, and then run the flow again.
|
||||
The text contents of the URL are returned as unstructured raw text, which you can extract patterns with the [Parser](/components-processing#parser) component.
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
|
||||
**Inputs**
|
||||
Some of the available parameters include the following:
|
||||
|
||||
| Name | Display Name | Info |
|
||||
|------|--------------|------|
|
||||
| urls | URLs | Click the '+' button to enter one or more URLs to crawl recursively. |
|
||||
| max_depth | Max Depth | Controls how many 'clicks' away from the initial page the crawler will go. |
|
||||
| prevent_outside | Prevent Outside | If enabled, only crawls URLs within the same domain as the root URL. |
|
||||
| use_async | Use Async | If enabled, uses asynchronous loading which can be significantly faster but might use more system resources. |
|
||||
| format | Output Format | Output Format. Use `Text` to extract the text from the HTML or `HTML` for the raw HTML content. |
|
||||
| timeout | Timeout | Timeout for the request in seconds. |
|
||||
| headers | Headers | The headers to send with the request. |
|
||||
| urls | URLs | Input parameter. One or more URLs to crawl recursively. In the visual editor, click <Icon name="Plus" aria-hidden="true"/> **Add URL** to add multiple URLs. |
|
||||
| max_depth | Depth | Input parameter. Controls link traversal: how many "clicks" away from the initial page the crawler will go. A depth of 1 limits the crawl to the first page at the given URL only. A depth of 2 means the crawler crawls the first page plus each page directly linked from the first page, then stops. This setting exclusively controls link traversal; it doesn't limit the number of URL path segments or the domain. |
|
||||
| prevent_outside | Prevent Outside | Input parameter. If enabled, only crawls URLs within the same domain as the root URL. This prevents the crawler from accessing sites outside the given URL's domain, even if they are linked from one of the crawled pages. |
|
||||
| use_async | Use Async | Input parameter. If enabled, uses asynchronous loading which can be significantly faster but might use more system resources. |
|
||||
| format | Output Format | Input parameter. Sets the desired output format as **Text** or **HTML**. The default is **Text**. For more information, see [URL output](#url-output).|
|
||||
| timeout | Timeout | Input parameter. Timeout for the request in seconds. |
|
||||
| headers | Headers | Input parameter. The headers to send with the request if needed for authentication or otherwise. |
|
||||
|
||||
**Outputs**
|
||||
Additional input parameters are available for error handling and encoding.
|
||||
|
||||
### URL output
|
||||
|
||||
There are two settings that control the output of the **URL** component at different stages:
|
||||
|
||||
* **Output Format**: This optional parameter controls the content extracted from the crawled pages:
|
||||
|
||||
* **Text (default)**: The component extracts only the text from the HTML of the crawled pages.
|
||||
* **HTML**: The component extracts the entire raw HTML content of the crawled pages.
|
||||
|
||||
* **Output data type**: In the component's output field (near the output port) you can select the structure of the outgoing data when it is passed to other components:
|
||||
|
||||
* **Extracted Pages**: Outputs a [`DataFrame`](/data-types#dataframe) that breaks the crawled pages into columns for the entire page content (`text`) and metadata like `url` and `title`.
|
||||
* **Raw Content**: Outputs a [`Message`](/data-types#message) containing the entire text or HTML from the crawled pages, including metadata, in a single block of text.
|
||||
|
||||
When used as a standard component in a flow, the **URL** component must be connected to a component that accepts the selected output data type (`DataFrame` or `Message`).
|
||||
You can connect the **URL** component directly to a compatible component, or you can use a [**Type Convert** component](/components-processing#type-convert) to convert the output to another type before passing the data to other components if the data types aren't directly compatible.
|
||||
|
||||
Processing components, like the **Type Convert** component, are useful with the **URL** component because it can extract a large amount of data from the crawled pages.
|
||||
For example, if you only want to pass specific fields to other components, you can use a [**Parser** component](/components-processing#parser) to extract only that data from the crawled pages before passing the data to other components.
|
||||
|
||||
When used in **Tool Mode** with an **Agent** component, the **URL** component can be connected directly to the **Agent** component's **Tools** port without converting the data.
|
||||
The agent decides whether to use the **URL** component based on the user's query, and it can process the `DataFrame` or `Message` output directly.
|
||||
|
||||
## Web Search
|
||||
|
||||
The **Web Search** component performs a basic web search using DuckDuckGo's HTML scraping interface.
|
||||
For other search APIs, see [Bundles](/components-bundle-components).
|
||||
|
||||
:::important
|
||||
The **Web Search** component uses web scraping that can be subject to rate limits.
|
||||
|
||||
For production use, consider using another search component with more robust API support, such as a provider-specific [bundle](/components-bundle-components).
|
||||
:::
|
||||
|
||||
### Use the Web Search component in a flow
|
||||
|
||||
The following steps demonstrate one way that you can use a **Web Search** component in a flow:
|
||||
|
||||
1. Create a flow based on the [**Basic Prompting** template](/basic-prompting).
|
||||
|
||||
2. Add a **Web Search** component, and then enter a search query, such as `environmental news`.
|
||||
|
||||
3. Add a [**Type Convert** component](/components-processing#type-convert), set the **Output Type** to **Message**, and then connect the **Web Search** component's output to the **Type Convert** component's input.
|
||||
|
||||
By default, the **Web Search** component outputs a `DataFrame`.
|
||||
Because the **Prompt Template** component only accepts `Message` data, this conversion is required so that the flow can pass the search results to the **Prompt Template** component.
|
||||
For more information, see [Web Search output](#web-search-output).
|
||||
|
||||
5. In the **Prompt Template** component's **Template** field, add a variable like `{searchresults}` or `{context}`.
|
||||
|
||||
This adds a field to the **Prompt Template** component that you can use to pass the converted search results to the prompt.
|
||||
|
||||
6. Connect the **Type Convert** component's output to the new variable field on the **Prompt Template** component.
|
||||
|
||||

|
||||
|
||||
7. In the **Language Model** component, add your OpenAI API key, or select a different provider and model.
|
||||
|
||||
8. Click **Playground**, and then enter `latest news`.
|
||||
|
||||
The LLM processes the request, including the context passed through the **Prompt Template** component, and then prints the response in the **Playground** chat interface.
|
||||
|
||||
<details>
|
||||
<summary>Result</summary>
|
||||
|
||||
The following is an example of a possible response.
|
||||
Your response may vary based on the current state of the web, your specific query, the model, and other factors.
|
||||
|
||||
```text
|
||||
Here are some of the latest news articles related to the environment:
|
||||
Ozone Pollution and Global Warming: A recent study highlights that ozone pollution is a significant global environmental concern, threatening human health and crop production while exacerbating global warming. Read more
|
||||
...
|
||||
```
|
||||
|
||||
</details>
|
||||
|
||||
### Web Search parameters
|
||||
|
||||
| Name | Display Name | Info |
|
||||
|------|--------------|------|
|
||||
| data | Data | A list of [Data](/data-types#data) objects containing fetched content and metadata. |
|
||||
| text | Message | The fetched content as formatted text. |
|
||||
| dataframe | DataFrame | The content formatted as a [DataFrame](/data-types#dataframe) object. |
|
||||
| query | Search Query | Input parameter. Keywords to search for. |
|
||||
| timeout | Timeout | Input parameter. Timeout for the web search request in seconds. Default: `5`. |
|
||||
| results | Search Results | Output parameter. Returns a `DataFrame` containing `title`, `links`, and `snippets`. For more information, see [Web Search output](#web-search-output). |
|
||||
|
||||
</details>
|
||||
### Web Search output
|
||||
|
||||
The **Web Search** component outputs a [`DataFrame`](/data-types#dataframe) containing the key columns `title`, `links`, and `snippets`.
|
||||
|
||||
When used as a standard component in a flow, the **Web Search** component must be connected to a component that accepts `DataFrame` input, or you must use a [**Type Convert** component](/components-processing#type-convert) to convert the output to `Data` or `Message` type before passing the data to other components.
|
||||
|
||||
When used in **Tool Mode** with an **Agent** component, the **Web Search** component can be connected directly to the **Agent** component's **Tools** port without converting the data.
|
||||
The agent decides whether to use the **Web Search** component based on the user's query, and it can process the `DataFrame` output directly.
|
||||
|
||||
## Webhook
|
||||
|
||||
This component defines a webhook trigger that runs a flow when it receives an HTTP POST request.
|
||||
The **Webhook** component defines a webhook trigger that runs a flow when it receives an HTTP POST request.
|
||||
|
||||
If the input is not valid JSON, the component wraps it in a `payload` object so that it can be processed and still trigger the flow.
|
||||
### Trigger the webhook
|
||||
|
||||
When a **Webhook** component is added to the workspace, a new **Webhook cURL** tab becomes available in the **API** pane that contains an HTTP POST request for triggering the webhook component. For example:
|
||||
Replace `LANGFLOW_SERVER_ADDRESS`, `FLOW_ID`, and `LANGFLOW_API_KEY` with the values from your Langflow deployment.
|
||||
When you add a **Webhook** component to your flow, a **Webhook cURL** tab is added to the flow's [**API Access** pane](/concepts-publish#api-access).
|
||||
This tab automatically generates an HTTP POST request code snippet that you can use to trigger your flow through the **Webhook** component.
|
||||
For example:
|
||||
|
||||
```bash
|
||||
curl -X POST \
|
||||
"http://LANGFLOW_SERVER_ADDRESS/api/v1/webhook/FLOW_ID" \
|
||||
"http://$LANGFLOW_SERVER_ADDRESS/api/v1/webhook/$FLOW_ID" \
|
||||
-H 'Content-Type: application/json' \
|
||||
-H 'x-api-key: LANGFLOW_API_KEY' \
|
||||
-H 'x-api-key: $LANGFLOW_API_KEY' \
|
||||
-d '{"any": "data"}'
|
||||
```
|
||||
|
||||
The **Webhook** component is often paired with a [**Parser** component](/components-processing#parser) to extract relevant data from the raw payload.
|
||||
For more information, see [Trigger flows with webhooks](/webhook).
|
||||
|
||||
To troubleshoot a flow with a **Webhook** component and verify that the component is receiving data, you can create a small flow that outputs only the parsed payload:
|
||||
|
||||
1. Create a flow with **Webhook**, **Parser**, and **Chat Output** components.
|
||||
2. Connect the Webhook component's **Data** output to the Parser component's **Data** input.
|
||||
3. Connect the Parser component's **Parsed Text** output to the Chat Output component's **Text** input.
|
||||
4. Edit the **Parser** component to set **Mode** to **Stringify**.
|
||||
|
||||
This mode passes the data received by the Webhook component as a string that is printed by the **Chat Output** component.
|
||||
|
||||
5. Click **Share**, select **API access**, and then copy the **Webhook cURL** code snippet.
|
||||
6. Optional: Edit the `data` in the code snippet if you want to pass a different payload.
|
||||
7. Send the POST request to trigger the flow.
|
||||
8. Click **Playground** to verify that the **Chat Output** component printed the JSON data from your POST request.
|
||||
|
||||
For more information, see [Trigger flows with webhooks](/webhook).
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
|
||||
**Inputs**
|
||||
### Webhook parameters
|
||||
|
||||
| Name | Display Name | Description |
|
||||
|------|--------------|-------------|
|
||||
| data | Payload | Receives a payload from external systems through HTTP POST requests. |
|
||||
| curl | cURL | The cURL command template for making requests to this webhook. |
|
||||
| endpoint | Endpoint | The endpoint URL where this webhook receives requests. |
|
||||
| data | Payload | Input parameter. Receives a payload from external systems through HTTP POST requests. |
|
||||
| curl | cURL | Input parameter. The cURL command template for making requests to this webhook. |
|
||||
| endpoint | Endpoint | Input parameter. The endpoint URL where this webhook receives requests. |
|
||||
| output_data | Data | Output parameter. The processed data from the webhook input. Returns an empty [`Data`](/data-types#data) object if no input is provided. If the input is not valid JSON, the **Webhook** component wraps it in a `payload` object so that it can be accepted as input to trigger the flow. |
|
||||
|
||||
**Outputs**
|
||||
## Additional data components
|
||||
|
||||
| Name | Display Name | Description |
|
||||
|------|--------------|-------------|
|
||||
| output_data | Data | Outputs processed data from the webhook input, and returns an empty [Data](/data-types#data) object if no input is provided. If the input is not valid JSON, the component wraps it in a `payload` object. |
|
||||
Langflow's core components are meant to be generic and support a range of use cases.
|
||||
Core components are typically not limited to a single provider.
|
||||
|
||||
</details>
|
||||
If the core data components don't meet your needs, you can find provider-specific components in the [**Bundles**](/components-bundle-components) section of the **Components** menu.
|
||||
|
||||
## Legacy components
|
||||
For example, the [**DataStax** bundle](/bundles-datastax) includes components for CQL queries, and the [**Google** bundle](/bundles-google) includes components for Google Search APIs.
|
||||
|
||||
Legacy components are available for use but are no longer supported.
|
||||
## Legacy data components
|
||||
|
||||
### Gmail Loader
|
||||
The **Load CSV** and **Load JSON** components are legacy components.
|
||||
You can still use them in your flows, but they are no longer maintained and can be removed in a future release.
|
||||
|
||||
:::warning Legacy Google OAuth Components
|
||||
Google OAuth Components are in **Legacy**, which means they are available for use but no longer in active development as of Langflow 1.4.0.
|
||||
They may not work in newer versions of Langflow.
|
||||
To connect your flows to Google OAuth services, use [Composio](/integrations-composio).
|
||||
:::
|
||||
Replace these components with the **File** component, which supports loading CSV and JSON files, as well as many other file types.
|
||||
|
||||
This component loads emails from Gmail using provided credentials and filters.
|
||||
## See also
|
||||
|
||||
For more information about creating a service account JSON, see [Service Account JSON](https://developers.google.com/identity/protocols/oauth2/service-account).
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
|
||||
**Inputs**
|
||||
|
||||
| Input | Type | Description |
|
||||
| ----------- | ---------------- | ------------------------------------------------------------------------------------ |
|
||||
| json_string | SecretStrInput | A JSON string containing OAuth 2.0 access token information for service account access. |
|
||||
| label_ids | MessageTextInput | A comma-separated list of label IDs to filter emails. |
|
||||
| max_results | MessageTextInput | The maximum number of emails to load. |
|
||||
|
||||
**Outputs**
|
||||
|
||||
| Output | Type | Description |
|
||||
| ------ | ---- | ----------------- |
|
||||
| data | Data | The loaded email data. |
|
||||
|
||||
</details>
|
||||
|
||||
### Google Drive Loader
|
||||
|
||||
:::warning Legacy Google OAuth Components
|
||||
Google OAuth Components are in **Legacy**, which means they are available for use but no longer in active development as of Langflow 1.4.0.
|
||||
They may not work in newer versions of Langflow.
|
||||
To connect your flows to Google OAuth services, use [Composio](/integrations-composio).
|
||||
:::
|
||||
|
||||
For more information about creating a service account JSON, see [Service Account JSON](https://developers.google.com/identity/protocols/oauth2/service-account).
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
|
||||
**Inputs**
|
||||
|
||||
| Input | Type | Description |
|
||||
| ----------- | ---------------- | ------------------------------------------------------------------------------------ |
|
||||
| json_string | SecretStrInput | A JSON string containing OAuth 2.0 access token information for service account access. |
|
||||
| document_id | MessageTextInput | A single Google Drive document ID. |
|
||||
|
||||
**Outputs**
|
||||
|
||||
| Output | Type | Description |
|
||||
| ------ | ---- | -------------------- |
|
||||
| docs | Data | The loaded document data. |
|
||||
|
||||
</details>
|
||||
|
||||
### Google Drive Search
|
||||
|
||||
:::warning Legacy Google OAuth Components
|
||||
Google OAuth Components are in **Legacy**, which means they are available for use but no longer in active development as of Langflow 1.4.0.
|
||||
They may not work in newer versions of Langflow.
|
||||
To connect your flows to Google OAuth services, use [Composio](/integrations-composio).
|
||||
:::
|
||||
|
||||
This component searches Google Drive files using provided credentials and query parameters.
|
||||
|
||||
For more information about creating a service account JSON, see [Service Account JSON](https://developers.google.com/identity/protocols/oauth2/service-account).
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
|
||||
**Inputs**
|
||||
|
||||
| Input | Type | Description |
|
||||
| -------------- | ---------------- | ------------------------------------------------------------------------------------ |
|
||||
| token_string | SecretStrInput | A JSON string containing OAuth 2.0 access token information for service account access. |
|
||||
| query_item | DropdownInput | The field to query. |
|
||||
| valid_operator | DropdownInput | The operator to use in the query. |
|
||||
| search_term | MessageTextInput | The value to search for in the specified query item. |
|
||||
| query_string | MessageTextInput | The query string used for searching. |
|
||||
|
||||
**Outputs**
|
||||
|
||||
| Output | Type | Description |
|
||||
| ---------- | --------- | ----------------------------------------------- |
|
||||
| doc_urls | List[str] | The URLs of the found documents. |
|
||||
| doc_ids | List[str] | The IDs of the found documents. |
|
||||
| doc_titles | List[str] | The titles of the found documents. |
|
||||
| Data | Data | The document titles and URLs in a structured format. |
|
||||
|
||||
</details>
|
||||
- [Google components](/bundles-google)
|
||||
- [Composio components](/integrations-composio)
|
||||
- [File management](/concepts-file-management)
|
||||
|
|
@ -1,74 +1,120 @@
|
|||
---
|
||||
title: Embedding models
|
||||
title: Embedding Model
|
||||
slug: /components-embedding-models
|
||||
---
|
||||
|
||||
import Icon from "@site/src/components/icon";
|
||||
|
||||
:::important
|
||||
In [Langflow version 1.5](/release-notes), the singular **Embedding model** component replaces many provider-specific embedding models components. Any provider-specific embedding model components that weren't incorporated into the singular component were moved to [**Bundles**](/components-bundle-components).
|
||||
Embedding model components in Langflow generate text embeddings using a specified Large Language Model (LLM).
|
||||
|
||||
Langflow includes a core **Embedding Model** component that has built-in support for some LLMs.
|
||||
Alternatively, you can use any [additional embedding model component](#additional-embedding-model-components) in place of the core **Embedding Model** component.
|
||||
|
||||
The built-in LLMs are appropriate for most text-based embedding model use cases in Langflow.
|
||||
|
||||
## Use embedding model components in a flow
|
||||
|
||||
Use embedding model components anywhere you need to generate embeddings in a flow.
|
||||
|
||||
This example shows how to use an embedding model component in a flow to create a semantic search system.
|
||||
This flow loads a text file, splits the text into chunks, generates embeddings for each chunk, and then loads the chunks and embeddings into a vector store. The input and output components allow a user to query the vector store through a chat interface.
|
||||
|
||||

|
||||
|
||||
:::tip
|
||||
This example uses the core **Embedding Model** component.
|
||||
|
||||
To use another model, you can replace the core **Embedding Model** component with any [additional embedding model component](#additional-embedding-model-components) in these steps.
|
||||
However, your component might have slightly different parameters than the core **Embedding Model** component.
|
||||
:::
|
||||
|
||||
Embedding model components in Langflow generate text embeddings using the selected Large Language Model (LLM). The core **Embedding model** component supports many LLM providers, models, and use cases. For additional providers and models not supported by the core **Embedding model** component, see [Bundles](/components-bundle-components).
|
||||
1. Create a flow, add a **File** component, and then select a file containing text data, such as a PDF, that you can use to test the flow.
|
||||
|
||||
The core **Language Model** and **Embedding Model** components are adequate for most use cases.
|
||||
2. Add an **Embedding Model** component, and then provide a valid OpenAI API key.
|
||||
|
||||
By default, the **Embedding Model** component uses an OpenAI model.
|
||||
If you want to use a different model, edit the **Model Name**, and **API Key** fields accordingly.
|
||||
Or, see [Additional embedding model components](#additional-embedding-model-components) for other embedding model components that you can use in place of the core **Embedding Model** component.
|
||||
|
||||
## Use an Embedding Model component in a flow
|
||||
You can enter component API keys directly or use Langflow global variables to reference your API keys.
|
||||
|
||||
Create a semantic search system with the **Embedding model** component.
|
||||
3. Add a [**Split Text** component](/components-processing#split-text) to your flow.
|
||||
This component splits text input into smaller chunks to be processed into embeddings.
|
||||
|
||||
1. Add the **Embedding model** component to your flow.
|
||||
The default model is OpenAI's `text-embedding-3-small`, which is a balanced model, based on [OpenAI's recommendations](https://platform.openai.com/docs/guides/embeddings#embedding-models).
|
||||
2. In the **OpenAI API Key** field, enter your OpenAI API key.
|
||||
3. Add a [Split text](/components-processing#split-text) component to your flow.
|
||||
This component splits your input text into smaller chunks to be processed into embeddings.
|
||||
4. Add a [Chroma DB](/components-vector-stores#chroma-db) vector store component to your flow.
|
||||
This component stores your text embeddings for later retrieval.
|
||||
5. Connect the **Text Splitter** component's **Chunks** output to the **Chroma DB** component's **Ingest Data** input.
|
||||
6. Connect the **Embedding model** component's **Embeddings** output to the **Chroma DB** component's **Embeddings** input.
|
||||
4. Add a [**Vector Store** component](/components-vector-stores), such as the **Chroma DB** component, to your flow, and then configure the component to connect to your vector store database.
|
||||
This component stores the generated embeddings so they can be used for similarity search.
|
||||
|
||||
This flow loads a file from the File loader, splits the text, and embeds the split text into the local Chroma vector store using the `text-embedding-3-small` model.
|
||||
5. Connect the components:
|
||||
|
||||

|
||||
* Connect the **File** component's **Loaded Files** output to the **Split Text** component's **Data or DataFrame** input.
|
||||
* Connect the **Split Text** component's **Chunks** output to the **Vector Store** component's **Ingest Data** input.
|
||||
* Connect the **Embedding Model** component's **Embeddings** output to the **Vector Store** component's **Embedding** input.
|
||||
|
||||
To query the vector store, include [Chat Input](/components-io#chat-input) and [Chat Output](/components-io#chat-output) components.
|
||||
6. To query the vector store, add [**Chat Input/Output** components](/components-io#chat-io):
|
||||
|
||||
7. Connect a [Chat Input](/components-io#chat-input) component to the **Search Query** input of the Chroma DB vector store.
|
||||
8. Connect a [Chat Output](/components-io#chat-output) component to the **Search Results** port of the Chroma DB vector store.
|
||||
* Connect the **Chat Input** component to the **Vector Store** component's **Search Query** input.
|
||||
* Connect the **Vector Store** component's **Search Results** output to the **Chat Output** component.
|
||||
|
||||
Your flow looks like the following:
|
||||

|
||||
7. Click **Playground**, and then enter a search query to retrieve text chunks that are most semantically similar to your query.
|
||||
|
||||
9. Open the **Playground** and enter a search query.
|
||||
The Playground returns the most semantically similar text chunks.
|
||||
## Embedding Model
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
|
||||
**Inputs**
|
||||
Some **Embedding Model** component input parameters are hidden by default in the visual editor.
|
||||
You can toggle parameters through the <Icon name="SlidersHorizontal" aria-hidden="true"/> **Controls** in the [component's header menu](/concepts-components#component-menus).
|
||||
|
||||
| Name | Display Name | Type | Description |
|
||||
|------|--------------|------|-------------|
|
||||
| provider | Model Provider | Dropdown | Select the embedding model provider. |
|
||||
| model | Model Name | Dropdown | Select the embedding model to use.|
|
||||
| api_key | OpenAI API Key | SecretString | The API key required for authenticating with the provider. |
|
||||
| api_base | API Base URL | String | Base URL for the API. Leave empty for default. |
|
||||
| dimensions | Dimensions | Integer | The number of dimensions for the output embeddings. |
|
||||
| chunk_size | Chunk Size | Integer | The size of text chunks to process. Default: `1000`. |
|
||||
| request_timeout | Request Timeout | Float | Timeout for API requests |
|
||||
| max_retries | Max Retries | Integer | Maximum number of retry attempts. Default: `3`. |
|
||||
| show_progress_bar | Show Progress Bar | Boolean | Whether to display a progress bar during embedding generation. |
|
||||
| model_kwargs | Model Kwargs | Dictionary | Additional keyword arguments to pass to the model. |
|
||||
| provider | Model Provider | List | Input parameter. Select the embedding model provider. |
|
||||
| model | Model Name | List | Input parameter. Select the embedding model to use.|
|
||||
| api_key | OpenAI API Key | Secret[String] | Input parameter. The API key required for authenticating with the provider. |
|
||||
| api_base | API Base URL | String | Input parameter. Base URL for the API. Leave empty for default. |
|
||||
| dimensions | Dimensions | Integer | Input parameter. The number of dimensions for the output embeddings. |
|
||||
| chunk_size | Chunk Size | Integer | Input parameter. The size of text chunks to process. Default: `1000`. |
|
||||
| request_timeout | Request Timeout | Float | Input parameter. Timeout for API requests. |
|
||||
| max_retries | Max Retries | Integer | Input parameter. Maximum number of retry attempts. Default: `3`. |
|
||||
| show_progress_bar | Show Progress Bar | Boolean | Input parameter. Whether to display a progress bar during embedding generation. |
|
||||
| model_kwargs | Model Kwargs | Dictionary | Input parameter. Additional keyword arguments to pass to the model. |
|
||||
| embeddings | Embeddings | Embeddings | Output parameter. An instance for generating embeddings using the selected provider. |
|
||||
|
||||
**Outputs**
|
||||
## Additional embedding model components
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| embeddings | Embeddings | An instance for generating embeddings using the selected provider. |
|
||||
If your provider or model isn't supported by the core **Embedding Model** component, additional single-provider embedding model components are available in the [**Bundles**](/components-bundle-components) section of the **Components** menu.
|
||||
|
||||
## Legacy embedding components
|
||||
|
||||
The following components are legacy components.
|
||||
You can still use them in your flows, but they are no longer maintained and they can be removed in future releases.
|
||||
|
||||
<details>
|
||||
<summary>Embedding Similarity</summary>
|
||||
|
||||
The **Embedding Similarity** component is replaced by built-in similarity search functionality in [**Vector Store** components](/components-vector-stores).
|
||||
|
||||
This component calculates similarity scores for two embedding vectors.
|
||||
|
||||
It accepts the following parameters:
|
||||
|
||||
| Name | Display Name | Info |
|
||||
|------|--------------|------|
|
||||
| embedding_vectors | Embedding Vectors | Input parameter. A list containing exactly two data objects with embedding vectors to compare. |
|
||||
| similarity_metric | Similarity Metric | Input parameter. Select the similarity metric to use. Options: "Cosine Similarity", "Euclidean Distance", "Manhattan Distance". |
|
||||
| similarity_data | Similarity Data | Output parameter. A data object containing the computed similarity score and additional information. |
|
||||
|
||||
</details>
|
||||
|
||||
## Embedding models bundles
|
||||
<details>
|
||||
<summary>Text Embedder</summary>
|
||||
|
||||
If your provider or model isn't supported by the core **Embedding model** component, see [Bundles](/components-bundle-components) for additional language model and embedding model components developed by third-party contributors.
|
||||
The **Text Embedder** component is replaced by the **Embedding Model** component.
|
||||
|
||||
This component generates embeddings for a given message using a specified embedding model.
|
||||
|
||||
It accepts the following parameters:
|
||||
|
||||
| Name | Display Name | Info |
|
||||
|------|--------------|------|
|
||||
| embedding_model | Embedding Model | Input parameter. The embedding model to use for generating embeddings. |
|
||||
| message | Message | Input parameter. The message for which to generate embeddings. |
|
||||
| embeddings | Embedding Data | Output parameter. A data object containing the original text and its embedding vector. |
|
||||
|
||||
</details>
|
||||
|
|
@ -4,198 +4,244 @@ slug: /components-helpers
|
|||
---
|
||||
|
||||
import Icon from "@site/src/components/icon";
|
||||
import Tabs from '@theme/Tabs';
|
||||
import TabItem from '@theme/TabItem';
|
||||
|
||||
Helper components provide utility functions to help manage data, tasks, and other components in your flow.
|
||||
Helper components provide utility functions to help manage data and perform simple tasks in your flow.
|
||||
|
||||
## Calculator
|
||||
|
||||
The Calculator component performs basic arithmetic operations on mathematical expressions. It supports addition, subtraction, multiplication, division, and exponentiation operations.
|
||||
The Calculator component performs basic arithmetic operations on mathematical expressions.
|
||||
It supports addition, subtraction, multiplication, division, and exponentiation operations.
|
||||
|
||||
For an example of using this component in a flow, see the [Python interpreter](/components-processing#python-interpreter) component.
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
### Calculator parameters
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| expression | String | The arithmetic expression to evaluate, such as `4*4*(33/22)+12-20`. |
|
||||
| expression | String | Input parameter. The arithmetic expression to evaluate, such as `4*4*(33/22)+12-20`. |
|
||||
| result | Data | Output parameter. The calculation result as a [`Data` object](/data-types) containing the evaluated expression. |
|
||||
|
||||
**Outputs**
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| result | Data | The calculation result as a Data object containing the evaluated expression. |
|
||||
|
||||
</details>
|
||||
|
||||
## Current date
|
||||
## Current Date
|
||||
|
||||
The Current Date component returns the current date and time in a selected timezone. This component provides a flexible way to obtain timezone-specific date and time information within a Langflow pipeline.
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
|
||||
**Inputs**
|
||||
### Current Date parameters
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| timezone | String | The timezone for the current date and time. |
|
||||
| timezone | String | Input parameter. The timezone for the current date and time. |
|
||||
| current_date | String | Output parameter. The resulting current date and time in the selected timezone. |
|
||||
|
||||
**Outputs**
|
||||
## Message History
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| current_date | String | The resulting current date and time in the selected timezone. |
|
||||
The **Message History** component provides combined chat history and message storage functionality.
|
||||
It can store and retrieve chat messages from either [Langflow storage](/memory) _or_ a dedicated chat memory database like Mem0 or Redis.
|
||||
|
||||
</details>
|
||||
It replaces the legacy **Chat History** and **Message Store** components.
|
||||
|
||||
## Message history
|
||||
:::important
|
||||
The **Language Model** and **Agent** components have built-in chat memory that is enabled by default and uses Langflow storage.
|
||||
|
||||
:::info
|
||||
Prior to Langflow 1.5, this component was two separate components called **Chat History** and **Message Store**.
|
||||
This built-in chat memory functionality is sufficient for most use cases.
|
||||
|
||||
Use the **Message History** component only if you need to access chat memories outside the chat context, such as sentiment analysis flow that retrieves and analyzes recently stored memories, or you want to store memories in a specific database, separate from Langflow storage.
|
||||
|
||||
For more information, see [Store chat memory](/memory#store-chat-memory).
|
||||
:::
|
||||
|
||||
This component handles chat history and message storage using Langflow’s SQLite database or an external memory source to save and retrieve chat messages. The default storage option is a [SQLite](https://www.sqlite.org/) database stored in your system's cache directory:
|
||||
### Use the Message History component in a flow
|
||||
|
||||
- **macOS Desktop**: `/Users/<username>/.langflow/data/database.db`
|
||||
- **Windows Desktop**: `C:\Users\<name>\AppData\Roaming\com.Langflow\data\langflow.db`
|
||||
- **OSS macOS/Windows/Linux/WSL (uv pip install)**: `<path_to_venv>/lib/python3.12/site-packages/langflow/langflow.db` (Python version may vary)
|
||||
- **OSS macOS/Windows/Linux/WSL (git clone)**: `<path_to_clone>/src/backend/base/langflow/langflow.db`
|
||||
The **Message History** component has two modes, depending on where you want to use it in your flow:
|
||||
|
||||
If your Langflow deployment has `LANGFLOW_DATABASE_URL` set to PostgreSQL, the Message History component will use the PostgreSQL database.
|
||||
* **Retrieve mode**: The component retrieves chat messages from your Langflow database or external memory.
|
||||
* **Store mode**: The component stores chat messages in your Langflow database or external memory.
|
||||
|
||||
Chat memory is distinct from vector store memory, because it is built specifically for storing and retrieving chat messages from databases.
|
||||
This means that you need multiple **Message History** components in your flow if you want to both store and retrieve chat messages.
|
||||
|
||||
Memory components provide access to their respective external databases **as memory**. This allows Large Language Models (LLMs) or [agents](/agents) to access external memory for persistence and context retention.
|
||||
<Tabs>
|
||||
<TabItem value="langflow" label="Use Langflow storage" default>
|
||||
|
||||
In **Retrieve** mode, this component retrieves chat messages from Langflow tables or external memory.
|
||||
In **Store** mode, this component stores chat messages in Langflow tables or external memory.
|
||||
The following steps explain how to create a chat-based flow that uses **Message History** components to store and retrieve chat memory from your Langflow installation's database:
|
||||
|
||||
In this example, one **Message History** component stores the complete chat history in a local Langflow table, which the other **Message History** component retrieves as context for the LLM to answer each question.
|
||||
1. Create or edit a flow where you want to use chat memory.
|
||||
|
||||

|
||||
2. At the beginning of the flow, add a **Message History** component, and then set it to **Retrieve** mode.
|
||||
|
||||
To configure Langflow to store and retrieve messages from an external database instead of local Langflow memory, follow these steps.
|
||||
3. Optional: In the **Message History** [component's header menu](/concepts-components#component-menus), click <Icon name="SlidersHorizontal" aria-hidden="true"/> **Controls** to enable parameters for memory sorting, filtering, and limits.
|
||||
|
||||
1. Add two **Memory** components to your flow.
|
||||
This example uses **Redis Chat Memory**.
|
||||
2. To enable external memory ports, in both **Memory** components, click <Icon name="SlidersHorizontal" aria-hidden="true"/> **Controls**, and then enable **External Memory**.
|
||||
3. Connect the **Memory** ports to the **Message History** components.
|
||||
The flow looks like this:
|
||||

|
||||
4. In the **Redis Chat Memory** components, add your connection information. These values are found in your Redis deployment. For more information, see the [Redis documentation](https://redis.io/docs/latest/).
|
||||
3. Add a [**Prompt Template** component](/components-prompts), add a `{memory}` variable to the **Template** field, and then connect the **Message History** output to the **memory** input.
|
||||
|
||||
For more information on configuring memory in Langflow, see [Memory](/memory).
|
||||
The **Prompt Template** component supplies instructions and context to LLMs, separate from chat messages passed through a **Chat Input** component.
|
||||
Variables in a **Prompt Template** component dynamically add fields to the **Prompt Template** component so that your flow can receive definitions for those values from other components, Langflow global variables, or fixed input.
|
||||
|
||||
In this case, the `{memory}` variable is populated by the retrieved chat memories, which are then passed to a **Language Model** or **Agent** component to provide additional context to the LLM.
|
||||
|
||||
4. Connect the **Prompt Template** component's output to a **Language Model** component's **System Message** input.
|
||||
|
||||
This example uses a **Language Model** component as the central chat driver, but you can also use an **Agent** component.
|
||||
|
||||
5. Add a **Chat Input** component, and then connect it to the **Language Model** component's **Input** input.
|
||||
|
||||
6. Connect the **Language Model** component's output to a **Chat Output** component.
|
||||
|
||||
7. At the end of the flow, add another **Message History** component, and then set it to **Store** mode.
|
||||
|
||||
Configure any additional parameters in the second **Message History** component as needed, taking into consideration that this particular component will store chat messages rather than retrieve them.
|
||||
|
||||
8. Connect the **Chat Output** component's output to the **Message History** component's **Message** input.
|
||||
|
||||
Each response from the LLM is output from the **Language Model** component to the **Chat Output** component, and then stored in chat memory by the final **Message History** component.
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="external" label="Use external chat memory">
|
||||
|
||||
To store and retrieve chat memory from a dedicated, external chat memory database, use the **Message History** component _and_ a provider-specific chat memory component.
|
||||
|
||||
Available provider-specific chat memory components include [**Cassandra Chat Memory** component](/bundles-datastax#cassandra-chat-memory), [**Mem0 Chat Memory**](/bundles-mem0), and [**Redis Chat Memory** component](/bundles-redis).
|
||||
For all provider-specific chat memory components, see [Bundles](/components-bundle-components).
|
||||
|
||||
The following steps explain how to create a flow that stores and retrieves chat memory from Redis chat memory:
|
||||
|
||||
1. Create or edit a flow where you want to use chat memory.
|
||||
|
||||
2. At the beginning of the flow, add **Message History** and **Redis Chat Memory** components:
|
||||
|
||||
1. Configure the **Redis Chat Memory** component to connect to your Redis database. For more information, see the [Redis documentation](https://redis.io/docs/latest/).
|
||||
2. Set the **Message History** component to **Retrieve** mode.
|
||||
3. In the **Message History** [component's header menu](/concepts-components#component-menus), click <Icon name="SlidersHorizontal" aria-hidden="true"/> **Controls**, enable **External Memory**, and then click **Close**.
|
||||
|
||||
In **Controls**, you can also enable parameters for memory sorting, filtering, and limits.
|
||||
|
||||
4. Connect the **Redis Chat Memory** component's output to the **Message History** component's **External Memory** input.
|
||||
|
||||
3. Add a [**Prompt Template** component](/components-prompts), add a `{memory}` variable to the **Template** field, and then connect the **Message History** output to the **memory** input.
|
||||
|
||||
The **Prompt Template** component supplies instructions and context to LLMs, separate from chat messages passed through a **Chat Input** component.
|
||||
Variables in a **Prompt Template** component dynamically add fields to the **Prompt Template** component so that your flow can receive definitions for those values from other components, Langflow global variables, or fixed input.
|
||||
|
||||
In this case, the `{memory}` variable is populated by the retrieved chat memories, which are then passed to a **Language Model** or **Agent** component to provide additional context to the LLM.
|
||||
|
||||
4. Connect the **Prompt Template** component's output to a **Language Model** component's **System Message** input.
|
||||
|
||||
This example uses a **Language Model** component as the central chat driver, but you can also use an **Agent** component.
|
||||
|
||||
5. Add a **Chat Input** component, and then connect it to the **Language Model** component's **Input** input.
|
||||
|
||||
6. Connect the **Language Model** component's output to a **Chat Output** component.
|
||||
|
||||
7. At the end of the flow, add another pair of **Message History** and **Redis Chat Memory** components:
|
||||
|
||||
1. Configure the **Redis Chat Memory** component to connect to your Redis database.
|
||||
2. Set the **Message History** component to **Store** mode.
|
||||
3. In the **Message History** [component's header menu](/concepts-components#component-menus), click <Icon name="SlidersHorizontal" aria-hidden="true"/> **Controls**, enable **External Memory**, and then click **Close**.
|
||||
|
||||
Configure any additional parameters in this component as needed, taking into consideration that this particular component will store chat messages rather than retrieve them.
|
||||
|
||||
4. Connect the **Redis Chat Memory** component to the **Message History** component's **External Memory** input.
|
||||
|
||||
8. Connect the **Chat Output** component's output to the **Message History** component's **Message** input.
|
||||
|
||||
Each response from the LLM is output from the **Language Model** component to the **Chat Output** component, and then stored in chat memory by passing it to the final **Message History** and **Redis Chat Memory** components.
|
||||
|
||||

|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
### Message History parameters
|
||||
|
||||
Many **Message History** component input parameters are hidden by default in the visual editor.
|
||||
You can toggle parameters through the <Icon name="SlidersHorizontal" aria-hidden="true"/> **Controls** in the [component's header menu](/concepts-components#component-menus).
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| memory | Memory | Input parameter. Retrieve messages from an external memory. If empty, the Langflow tables are used. |
|
||||
| sender | String | Input parameter. Filter by sender type. |
|
||||
| sender_name | String | Input parameter. Filter by sender name. |
|
||||
| n_messages | Integer | Input parameter. The number of messages to retrieve. |
|
||||
| session_id | String | Input parameter. The [session ID](/session-id) of the chat memories to store or retrieve. If omitted or empty, the current session ID for the flow run is used. Use custom session IDs if you need to segregate chat memory for different users or applications that run the same flow. |
|
||||
| order | String | Input parameter. The order of the messages. |
|
||||
| template | String | Input parameter. The template to use for formatting the data. It can contain the keys `{text}`, `{sender}` or any other key in the message data. |
|
||||
| messages | Message | Output parameter. The retrieved memories as `Message` objects, including `messages_text` containing retrieved chat message text. This is the typical output format used to pass memories _as chat messages_ to another component. |
|
||||
| dataframe | DataFrame | Output parameter. A `DataFrame` containing the message data. Useful for cases where you need to retrieve memories in a tabular format rather than as chat messages. |
|
||||
|
||||
## Legacy helper components
|
||||
|
||||
The following components are legacy components.
|
||||
You can use these components in your flows, but they are no longer maintained and may be removed in a future release.
|
||||
It is recommended that you replace legacy components with the recommended alternatives as soon as possible.
|
||||
|
||||
* **Chat History**: Replaced by the [**Message History** component](#message-history)
|
||||
* **Message Store**: Replaced by the [**Message History** component](#message-history)
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
|
||||
**Inputs**
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| memory | Memory | Retrieve messages from an external memory. If empty, the Langflow tables are used. |
|
||||
| sender | String | Filter by sender type. |
|
||||
| sender_name | String | Filter by sender name. |
|
||||
| n_messages | Integer | The number of messages to retrieve. |
|
||||
| session_id | String | The session ID of the chat. If empty, the current session ID parameter is used. |
|
||||
| order | String | The order of the messages. |
|
||||
| template | String | The template to use for formatting the data. It can contain the keys `{text}`, `{sender}` or any other key in the message data. |
|
||||
|
||||
**Outputs**
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| messages | Data | The retrieved messages as Data objects. |
|
||||
| messages_text | Message | The retrieved messages formatted as text. |
|
||||
| dataframe | DataFrame | A DataFrame containing the message data. |
|
||||
|
||||
</details>
|
||||
|
||||
## Legacy components
|
||||
|
||||
Legacy components are available for use but are no longer supported.
|
||||
|
||||
### Create List
|
||||
<summary>Create List</summary>
|
||||
|
||||
This component dynamically creates a record with a specified number of fields.
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
|
||||
**Inputs**
|
||||
It accepts the following parameters:
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| n_fields | Integer | The number of fields to be added to the record. |
|
||||
| text_key | String | The key used as text. |
|
||||
|
||||
**Outputs**
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| list | List | The dynamically created list with the specified number of fields. |
|
||||
| n_fields | Integer | Input parameter. The number of fields to be added to the record. |
|
||||
| text_key | String | Input parameter. The key used as text. |
|
||||
| list | List | Output parameter. The dynamically created list with the specified number of fields. |
|
||||
|
||||
</details>
|
||||
|
||||
### ID Generator
|
||||
<details>
|
||||
<summary>ID Generator</summary>
|
||||
|
||||
This component generates a unique ID.
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
|
||||
**Inputs**
|
||||
It accepts the following parameters:
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| unique_id | String | The generated unique ID. |
|
||||
|
||||
**Outputs**
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| id | String | The generated unique ID. |
|
||||
| unique_id | String | Input parameter. The generated unique ID. |
|
||||
| id | String | Output parameter. The generated unique ID. |
|
||||
|
||||
</details>
|
||||
|
||||
### Output Parser
|
||||
|
||||
This component transforms the output of a language model into a specified format. It supports CSV format parsing, which converts LLM responses into comma-separated lists using Langchain's `CommaSeparatedListOutputParser`.
|
||||
|
||||
:::note
|
||||
This component only provides formatting instructions and parsing functionality. It does not include a prompt. You'll need to connect it to a separate Prompt component to create the actual prompt template for the LLM to use.
|
||||
:::
|
||||
|
||||
Both the **Output Parser** and **Structured Output** components format LLM responses, but they have different use cases.
|
||||
The **Output Parser** is simpler and focused on converting responses into comma-separated lists. Use this when you just need a list of items, for example `["item1", "item2", "item3"]`.
|
||||
The **Structured Output** is more complex and flexible, and allows you to define custom schemas with multiple fields of different types. Use this when you need to extract structured data with specific fields and types.
|
||||
|
||||
To use this component:
|
||||
|
||||
1. Create a Prompt component and connect the Output Parser's `format_instructions` output to it. This ensures the LLM knows how to format its response.
|
||||
2. Write your actual prompt text in the Prompt component, including the `{format_instructions}` variable.
|
||||
For example, in your Prompt component, the template might look like:
|
||||
```
|
||||
{format_instructions}
|
||||
Please list three fruits.
|
||||
```
|
||||
3. Connect the `output_parser` output to your LLM model.
|
||||
|
||||
4. The output parser converts this into a Python list: `["apple", "banana", "orange"]`.
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
<summary>Output Parser</summary>
|
||||
|
||||
**Inputs**
|
||||
Replace the legacy **Output Parser** component with the [**Structured Output** component](/components-processing#structured-output) and [**Parser** component](/components-processing#parser).
|
||||
The components you need depend on the data types and complexity of the parsing task.
|
||||
|
||||
The **Output Parser** component transforms the output of a language model into comma-separated values (CSV) format, such as `["item1", "item2", "item3"]`, using LangChain's `CommaSeparatedListOutputParser`.
|
||||
The **Structured Output** component is a good alternative for this component because it also formats LLM responses with support for custom schemas and more complex parsing.
|
||||
|
||||
Parsing components only provide formatting instructions and parsing functionality.
|
||||
_They don't include prompts._
|
||||
You must connect parsers to **Prompt Template** components to create prompts that LLMs can use.
|
||||
|
||||
1. Open a flow that has a **Chat Input**, **Language Model**, and **Chat Output** components.
|
||||
|
||||
2. Add **Output Parser** and **Prompt Template** components to your flow.
|
||||
|
||||
3. Define your LLM's prompt in the **Prompt Template** component's **Template**, including all instructions and pre-loaded context.
|
||||
Make sure to include a `{format_instructions}` variable where you will inject the formatting instructions from the **Output Parser** component.
|
||||
For example:
|
||||
|
||||
```
|
||||
You are a helpful assistant that provides lists of information.
|
||||
|
||||
{format_instructions}
|
||||
```
|
||||
|
||||
Variables in the template dynamically add fields to the **Prompt Template** component so that your flow can receive definitions for those values from other components, Langflow global variables, or fixed input.
|
||||
|
||||
4. Connect the **Output Parser** component's output to the **Prompt Template** component's **format instructions** input.
|
||||
|
||||
The **Output Parser** component accepts the following parameters:
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| parser_type | String | The parser type. Currently supports "CSV". |
|
||||
|
||||
**Outputs**
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| format_instructions | String | Pass to a prompt template to include formatting instructions for LLM responses. |
|
||||
| output_parser | Parser | The constructed output parser that can be used to parse LLM responses. |
|
||||
| parser_type | String | Input parameter. Sets the parser type as "CSV". |
|
||||
| format_instructions | String | Output parameter. Pass to a prompt template to include formatting instructions for LLM responses. |
|
||||
| output_parser | Parser | Output parameter. The constructed output parser that can be used to parse LLM responses. |
|
||||
|
||||
</details>
|
||||
|
|
|
|||
|
|
@ -1,57 +1,59 @@
|
|||
---
|
||||
title: Inputs and outputs
|
||||
title: Input / Output
|
||||
slug: /components-io
|
||||
---
|
||||
|
||||
import Icon from "@site/src/components/icon";
|
||||
|
||||
# Input and output components in Langflow
|
||||
Langflow's input and output components define where data enters and exits your flow, but they don't have identical functionality.
|
||||
|
||||
Input and output components define where data enters and exits your flow.
|
||||
Specifically, **Chat Input/Output** components are designed to facilitate conversational interactions where messages are exchanged in a cumulative dialog.
|
||||
The data handled by these components includes the message text plus additional metadata like senders, session IDs, and timestamps.
|
||||
|
||||
Both components accept user input and return a `Message` object, but serve different purposes.
|
||||
In contrast, **Text Input/Output** components are designed for simple string input and output that doesn't require the additional context and metadata associated with chat messages.
|
||||
The data handled by these components is pared down to basic text strings.
|
||||
|
||||
The **Text Input** component accepts a text string input and returns a `Message` object containing only the input text. The output does not appear in the **Playground**.
|
||||
## Chat Input/Output {#chat-io}
|
||||
|
||||
The **Chat Input** component accepts multiple input types including text, files, and metadata, and returns a `Message` object containing the text along with sender information, session ID, and file attachments.
|
||||
:::important
|
||||
**Chat Input/Output** components are required to chat with your flow in the **Playground**.
|
||||
For more information, see [Test flows in the Playground](/concepts-playground).
|
||||
:::
|
||||
|
||||
The **Chat Input** component provides an interactive chat interface in the **Playground**.
|
||||
**Chat Input/Output** components are designed to handle conversational interactions in Langflow.
|
||||
|
||||
## Chat Input
|
||||
### Chat Input
|
||||
|
||||
This component collects user input as `Text` strings from the chat and wraps it in a [Message](/data-types#message) object that includes the input text, sender information, session ID, file attachments, and styling properties.
|
||||
The **Chat Input** component accepts text and file input, such as a chat message or a file.
|
||||
This data is passed to other components as [`Message` data](/data-types) containing the provided input as well as associated chat metadata, such as the sender, session ID, timestamp, and file attachments.
|
||||
|
||||
It can optionally store the message in a chat history.
|
||||
Initial input should _not_ be provided as a complete `Message` object because the **Chat Input** component constructs the `Message` object that is then passed to other components in the flow.
|
||||
|
||||
#### Chat Input parameters
|
||||
|
||||
Most **Chat Input** component input parameters are hidden by default in the visual editor.
|
||||
You can enable other parameters through the <Icon name="SlidersHorizontal" aria-hidden="true"/> **Controls** in the [component's header menu](/concepts-components#component-menus).
|
||||
|
||||
For information about the resulting `Message` object, including input parameters that are directly mapped to `Message` attributes, see [`Message` data](/data-types#message).
|
||||
|
||||
| Name | Display Name | Info |
|
||||
|------|--------------|------|
|
||||
|input_value|Input Text| Input parameter. The message text string to be passed as input. |
|
||||
|sender|Sender Type| Input parameter. Identifies the sender as either `User` or `Language Model`.|
|
||||
|sender_name|Sender Name| Input parameter. The name of the sender. If unspecified, defaults to `User` or `Language Model`. |
|
||||
|session_id|Session ID| Input parameter. The unique identifier for the chat session. If empty, the current session ID parameter is used.|
|
||||
|files|Files| Input parameter. The files to be sent with the message.|
|
||||
|background_color|Background Color| Input parameter. The background color of the icon.|
|
||||
|chat_icon|Icon| Input parameter. The icon of the message.|
|
||||
|should_store_message|Store Messages| Input parameter. Whether to store the message in chat history.|
|
||||
|text_color|Text Color| Input parameter. The text color of the name.|
|
||||
|message|Message|Output parameter. The resulting chat `Message` object with all specified properties.|
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
|
||||
**Inputs**
|
||||
|
||||
| Name | Display Name | Info |
|
||||
|------|--------------|------|
|
||||
|input_value|Text|The Message to be passed as input.
|
||||
|should_store_message|Store Messages|Store the message in the history.|
|
||||
|sender|Sender Type|The type of sender.|
|
||||
|sender_name|Sender Name|The name of the sender.|
|
||||
|session_id|Session ID|The unique identifier for the chat session. If empty, the current session ID parameter is used.|
|
||||
|files|Files|The files to be sent with the message.|
|
||||
|background_color|Background Color|The background color of the icon.|
|
||||
|chat_icon|Icon|The icon of the message.|
|
||||
|text_color|Text Color|The text color of the name.|
|
||||
|
||||
**Outputs**
|
||||
|
||||
| Name | Display Name | Info |
|
||||
|------|--------------|------|
|
||||
|message|Message|The resulting chat message object with all specified properties.|
|
||||
|
||||
</details>
|
||||
|
||||
### Message method
|
||||
<summary>Message method for Chat Input</summary>
|
||||
|
||||
The `ChatInput` class provides an asynchronous method to create and store a `Message` object based on the input parameters.
|
||||
The `Message` object is created in the `message_response` method of the ChatInput class using the `Message.create()` factory method.
|
||||
The `Message` object is created in the `message_response` method of the `ChatInput` class using the `Message.create()` factory method.
|
||||
|
||||
```python
|
||||
message = await Message.create(
|
||||
|
|
@ -68,154 +70,66 @@ message = await Message.create(
|
|||
)
|
||||
```
|
||||
|
||||
## Text Input
|
||||
|
||||
The **Text Input** component accepts a text string input and returns a `Message` object containing only the input text.
|
||||
|
||||
The output does not appear in the **Playground**.
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
|
||||
**Inputs**
|
||||
|
||||
| Name | Display Name | Info |
|
||||
|------|--------------|------|
|
||||
|input_value|Text|The text/content to be passed as output.|
|
||||
|
||||
**Outputs**
|
||||
|
||||
| Name | Display Name | Info |
|
||||
|------|--------------|------|
|
||||
|text|Text|The resulting text message.|
|
||||
|
||||
</details>
|
||||
|
||||
## Chat Output
|
||||
### Chat Output
|
||||
|
||||
The **Chat Output** component creates a [Message](/data-types#message) object that includes the input text, sender information, session ID, and styling properties.
|
||||
The **Chat Output** component ingests `Message`, `Data`, or `DataFrame` data from other components, transforms it into `Message` data if needed, and then emits the final output as a chat message.
|
||||
For information about these data types, see [Use Langflow data types](/data-types).
|
||||
|
||||
The component accepts the following input types.
|
||||
* [Data](/data-types#data)
|
||||
* [DataFrame](/data-types#dataframe)
|
||||
* [Message](/data-types#message)
|
||||
In the **Playground**, chat output is limited to the parts of the `Message` object that are relevant to the chat interface, such as the text response, sender name, and file attachments.
|
||||
To see the metadata associated with a chat message, inspect the message logs in the **Playground**.
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
When using the Langflow API, the API response includes the **Chat Output** `Message` object along with other response data from the flow run.
|
||||
Langflow API responses can be extremely verbose, so your applications must include code to extract relevant data from the response to return to the user.
|
||||
For an example, see the [Langflow quickstart](/get-started-quickstart).
|
||||
|
||||
**Inputs**
|
||||
#### Chat Output parameters
|
||||
|
||||
Most **Chat Output** component input parameters are hidden by default in the visual editor.
|
||||
You can enable them through the <Icon name="SlidersHorizontal" aria-hidden="true"/> **Controls** in the [component's header menu](/concepts-components#component-menus).
|
||||
|
||||
For information about the resulting `Message` object, including input parameters that are directly mapped to `Message` attributes, see [`Message` data](/data-types#message).
|
||||
|
||||
| Name | Display Name | Info |
|
||||
|------|--------------|------|
|
||||
|input_value|Text|The message to be passed as output.|
|
||||
|should_store_message|Store Messages|The flag to store the message in the history.|
|
||||
|sender|Sender Type|The type of sender.|
|
||||
|sender_name|Sender Name|The name of the sender.|
|
||||
|session_id|Session ID|The unique identifier for the chat session. If empty, the current session ID parameter is used.|
|
||||
|data_template|Data Template|The template to convert Data to Text. If the option is left empty, it is dynamically set to the Data's text key.|
|
||||
|background_color|Background Color|The background color of the icon.|
|
||||
|chat_icon|Icon|The icon of the message.|
|
||||
|text_color|Text Color|The text color of the name.|
|
||||
|clean_data|Basic Clean Data|When enabled, `DataFrame` inputs are cleaned when converted to text. Cleaning removes empty rows, empty lines in cells, and multiple newlines.|
|
||||
|input_value|Inputs| Input parameter. The message text string to be passed as output. |
|
||||
|should_store_message|Store Messages| Input parameter. Whether to store the message in chat history.|
|
||||
|sender|Sender Type| Input parameter. Identifies the sender as either `User` or `Language Model`.|
|
||||
|sender_name|Sender Name| Input parameter. The name of the sender. If unspecified, defaults to `User` or `Language Model`. |
|
||||
|session_id|Session ID| Input parameter. The unique identifier for the chat session. If empty, the current session ID parameter is used.|
|
||||
|data_template|Data Template| Input parameter. The template to convert [`Data` input](/data-types#data) to `text`. If empty, it is dynamically set to the `Data` object's `text` key.|
|
||||
|background_color|Background Color| Input parameter. The background color of the icon.|
|
||||
|chat_icon|Icon| Input parameter. The icon of the message.|
|
||||
|text_color|Text Color| Input parameter. The text color of the name.|
|
||||
|clean_data|Basic Clean Data| Input parameter. When enabled, [`DataFrame` input](/data-types#dataframe) is cleaned when converted to text. Cleaning removes empty rows, empty lines in cells, and multiple newlines.|
|
||||
|message|Message|Output parameter. The resulting chat `Message` object with all specified properties.|
|
||||
|
||||
**Outputs**
|
||||
### Use Chat Input/Output components in a flow
|
||||
|
||||
| Name | Display Name | Info |
|
||||
|------|--------------|------|
|
||||
|message|Message|The resulting chat message object with all specified properties.|
|
||||
To use the **Chat Input** and **Chat Output** components in a flow, connect them to components that accept or emit [`Message` data](/data-types#message).
|
||||
|
||||
</details>
|
||||
For example, the following flow connects **Chat Input** and **Chat Output** to a **Language Model** component, creating a simple LLM-based chat flow.
|
||||
|
||||
## Text Output
|
||||

|
||||
|
||||
The **Text Output** takes a single input of text and returns a [Message](/data-types#message) object containing that text.
|
||||
:::tip
|
||||
For detailed examples of **Chat Input/Output** components in flows, see the following:
|
||||
|
||||
The output does not appear in the **Playground**.
|
||||
* [Langflow quickstart](/get-started-quickstart): Create and run a basic agent flow.
|
||||
* [**Basic prompting** template](/basic-prompting): Create an LLM-based chat flow that accepts chat input as well as a prompt with additional instructions for the LLM. Many other Langflow templates also use **Chat Input/Output** components.
|
||||
* [Connect applications to agents](/agent-tutorial): Explore more advanced concepts around agentic flows and prompting, including triggering agent flows from external applications.
|
||||
:::
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
### Send chat input with the Langflow API
|
||||
|
||||
**Inputs**
|
||||
You can use the Langflow API to run a flow by sending input to a **Chat Input** component:
|
||||
|
||||
| Name | Display Name | Info |
|
||||
|------|--------------|------|
|
||||
|input_value|Text|The text to be passed as output.|
|
||||
|
||||
**Outputs**
|
||||
|
||||
| Name | Display Name | Info |
|
||||
|------|--------------|------|
|
||||
|text|Text|The resulting text message.|
|
||||
|
||||
</details>
|
||||
|
||||
## Chat components example flow
|
||||
|
||||
1. To use the **Chat Input** and **Chat Output** components in a flow, connect them to components that accept or send the [Message](/data-types#message) type.
|
||||
|
||||
For this example, connect a **Chat Input** component to an **OpenAI** model component's **Input** port, and then connect the **OpenAI** model component's **Message** port to the **Chat Output** component.
|
||||
|
||||
2. In the **OpenAI** model component, in the **OpenAI API Key** field, add your **OpenAI API key**.
|
||||
|
||||
The flow looks like this:
|
||||
|
||||

|
||||
|
||||
3. To send a message to your flow, open the **Playground**, and then enter a message.
|
||||
The **OpenAI** model component responds.
|
||||
Optionally, in the **OpenAI** model component, enter a **System Message** to control the model's response.
|
||||
4. In the Langflow UI, click **Logs**.
|
||||
The **Logs** pane opens.
|
||||
Here, you can inspect your component logs.
|
||||

|
||||
|
||||
5. Your first message was sent by the **Chat Input** component to the **OpenAI** model component.
|
||||
Click **Outputs** to view the sent message:
|
||||
```text
|
||||
"messages": [
|
||||
{
|
||||
"message": "What's the recommended way to install Docker on Mac M1?",
|
||||
"sender": "User",
|
||||
"sender_name": "User",
|
||||
"session_id": "Session Apr 21, 17:37:04",
|
||||
"stream_url": null,
|
||||
"component_id": "ChatInput-4WKag",
|
||||
"files": [],
|
||||
"type": "text"
|
||||
}
|
||||
],
|
||||
```
|
||||
6. Your second message was sent by the **OpenAI** model component to the **Chat Output** component.
|
||||
This is the raw text output of the model's response.
|
||||
The **Chat Output** component accepts this text as input and presents it as a formatted message.
|
||||
Click **Outputs** to view the sent message:
|
||||
```text
|
||||
"outputs":
|
||||
"text_output":
|
||||
"message": "To install Docker on a Mac with an M1 chip, you should use Docker Desktop for Mac, which is optimized for Apple Silicon. Here's a step-by-step guide to installing Docker on your M1 Mac:\n\n1.
|
||||
...
|
||||
"type": "text"
|
||||
```
|
||||
|
||||
:::tip
|
||||
Optionally, to view the outputs of each component in the flow, click <Icon name="TextSearch" aria-hidden="true"/> **Inspect output**.
|
||||
:::
|
||||
|
||||
### Send chat messages with the API
|
||||
|
||||
The **Chat Input** component is often the entry point for passing messages to the Langflow API.
|
||||
To send the same example messages programmatically to your Langflow server, do the following:
|
||||
|
||||
1. To get your Langflow endpoint, click **Share**, and then click **API access**.
|
||||
2. Copy the command from the **cURL** tab, and then paste it in your terminal.
|
||||
|
||||
The values for `LANGFLOW_SERVER_ADDRESS`, `FLOW_ID`, and `LANGFLOW_API_KEY` are automatically completed with values from your Langflow deployment.
|
||||
If your values are different, you must replace them.
|
||||
```text
|
||||
```bash
|
||||
curl --request POST \
|
||||
--url "http://LANGFLOW_SERVER_ADDRESS/api/v1/run/FLOW_ID" \
|
||||
--url "http://$LANGFLOW_SERVER_ADDRESS/api/v1/run/$FLOW_ID" \
|
||||
--header "Content-Type: application/json" \
|
||||
--header "x-api-key: LANGFLOW_API_KEY" \
|
||||
--header "x-api-key: $LANGFLOW_API_KEY" \
|
||||
--data '{
|
||||
"input_value": "What's the recommended way to install Docker on Mac M1?",
|
||||
"output_type": "chat",
|
||||
|
|
@ -223,55 +137,61 @@ curl --request POST \
|
|||
}'
|
||||
```
|
||||
|
||||
3. Modify `input_value` so it contains the question, `What's the recommended way to install Docker on Mac M1?`.
|
||||
When triggering flows with the Langflow API, the payload must contain the values for the **Chat Input** component's input parameters, such as `input_value`.
|
||||
|
||||
Note the `output_type` and `input_type` parameters that are passed with the message. The `chat` type provides additional configuration options, and the messages appear in the **Playground**. The `text` type returns only text strings, and does not appear in the **Playground**.
|
||||
Not all parameters need to be specified in the request.
|
||||
For example, `session_id` uses the flow's default session ID if omitted.
|
||||
If you want to use a custom session ID, include `session_id` in your request:
|
||||
|
||||
4. Add a custom `session_id` to the message's `data` object.
|
||||
|
||||
```text
|
||||
```bash
|
||||
curl --request POST \
|
||||
--url "http://LANGFLOW_SERVER_ADDRESS/api/v1/run/FLOW_ID" \
|
||||
--url "http://$LANGFLOW_SERVER_ADDRESS/api/v1/run/$FLOW_ID" \
|
||||
--header "Content-Type: application/json" \
|
||||
--header "x-api-key: LANGFLOW_API_KEY" \
|
||||
--header "x-api-key: $LANGFLOW_API_KEY" \
|
||||
--data '{
|
||||
"input_value": "Whats the recommended way to install Docker on Mac M1",
|
||||
"session_id": "docker-question-on-m1",
|
||||
"session_id": "$USER_ID",
|
||||
"output_type": "chat",
|
||||
"input_type": "chat"
|
||||
}'
|
||||
```
|
||||
The custom `session_id` value starts a new chat session between your client and the Langflow server, and can be useful in keeping conversations and AI context separate.
|
||||
|
||||
5. Send the POST request.
|
||||
Your request is answered.
|
||||
6. Navigate to the **Playground**.
|
||||
A new chat session called `docker-question-on-m1` has appeared, using your unique `session_id`.
|
||||
7. To modify additional parameters with **Tweaks** for your **Chat Input** and **Chat Output** components, click **Share**, and then click **API access**.
|
||||
8. Click **Input schema** to modify parameters in the component's `data` object.
|
||||
For more information, see [Trigger flows with the Langflow API](/concepts-publish).
|
||||
|
||||
For example, disabling storing messages from the **Chat Input** component adds a **Tweak** to your command:
|
||||
## Text Input/Output {#text-io}
|
||||
|
||||
```text
|
||||
curl --request POST \
|
||||
--url "http://LANGFLOW_SERVER_ADDRESS/api/v1/run/FLOW_ID" \
|
||||
--header "Content-Type: application/json" \
|
||||
--header "x-api-key: LANGFLOW_API_KEY" \
|
||||
--data '{
|
||||
"input_value": "Text to input to the flow",
|
||||
"output_type": "chat",
|
||||
"input_type": "chat",
|
||||
"tweaks": {
|
||||
"ChatInput-4WKag": {
|
||||
"should_store_message": false
|
||||
}
|
||||
}
|
||||
}'
|
||||
```
|
||||
:::important
|
||||
**Text Input/Output** components aren't supported in the **Playground**.
|
||||
Because the data isn't formatted as a chat message, the data doesn't appear in the **Playground**, and you can't chat with your flow in the **Playground**.
|
||||
|
||||
9. To confirm your command is using the tweak, navigate to the **Logs** pane, and then view the request from the **Chat Input** component.
|
||||
Given the preceding example, the value for `should_store_message` should be `false`.
|
||||
If you want to chat with a flow in the **Playground**, you must use the [**Chat Input/Output** components](#chat-io).
|
||||
:::
|
||||
|
||||
## See also
|
||||
**Text Input/Output** components are designed for flows that ingest or emit simple text strings.
|
||||
These components don't support full conversational interactions.
|
||||
|
||||
- [Session ID](/session-id)
|
||||
Passing chat-like metadata to a **Text Input/Output** component doesn't change the component's behavior; the result is still a simple text string.
|
||||
|
||||
### Text Input
|
||||
|
||||
The **Text Input** component accepts a text string input that is passed to other components as [`Message` data](/data-types) containing only the provided text string.
|
||||
|
||||
Initial input should _not_ be provided as a complete `Message` object because the **Text Input** component constructs the `Message` object that is then passed to other components in the flow.
|
||||
|
||||
#### Text Input parameters
|
||||
|
||||
| Name | Display Name | Info |
|
||||
|------|--------------|------|
|
||||
|input_value|Text|Input parameter. Text supplied as input to the component. Can be entered directly or passed as `Message` data from other components.|
|
||||
|text|Text|Output parameter. The resulting `Message` object containing the input text in the `text` attribute.|
|
||||
|
||||
### Text Output
|
||||
|
||||
The **Text Output** component ingests [`Message` data](/data-types#message) from other components, emitting only the `text` attribute in a simplified `Message` object.
|
||||
|
||||
#### Text Output parameters
|
||||
|
||||
| Name | Display Name | Info |
|
||||
|------|--------------|------|
|
||||
|input_value|Text|Input parameter. Text to be ingested and output as a string. Can be entered directly or passed as `Message` data from other components.|
|
||||
|text|Text|Output parameter. The resulting `Message` object containing the output text in the `text` attribute.|
|
||||
|
|
@ -3,298 +3,264 @@ title: Logic
|
|||
slug: /components-logic
|
||||
---
|
||||
|
||||
# Logic components in Langflow
|
||||
import Icon from "@site/src/components/icon";
|
||||
|
||||
Logic components provide functionalities for routing, conditional processing, and flow management.
|
||||
Langflow's logic components provide functionalities for routing, conditional processing, and flow management.
|
||||
|
||||
## Conditional router (If-Else component)
|
||||
## If-Else (conditional router) {#if-else}
|
||||
|
||||
This component routes messages by comparing two strings.
|
||||
It evaluates a condition by comparing two text inputs using the specified operator and routes the message to `true_result` or `false_result`.
|
||||
The **If-Else** component is a conditional router that routes messages by comparing two strings.
|
||||
It evaluates a condition by comparing two text inputs using the specified operator, and then routes the message to `true_result` or `false_result` depending on the evaluation.
|
||||
|
||||
The operator looks for single strings based on your defined [operator behavior](#operator-behavior), but it can also search for multiple words by regex matching.
|
||||
The operator looks for single strings in the input (`input_text`) based on an operator and match text (`match_text`), but it can also search for multiple words by matching a regex.
|
||||
Available operators include:
|
||||
|
||||
To use the **Conditional router** component to check incoming messages with regex matching, do the following:
|
||||
- **equals**: Exact match comparison
|
||||
- **not equals**: Inverse of exact match
|
||||
- **contains**: Checks if the `match_text` is found within `input_text`
|
||||
- **starts with**: Checks if `input_text` begins with `match_text`
|
||||
- **ends with**: Checks if `input_text` ends with `match_text`
|
||||
- **regex**: Matches on a case-sensitive pattern
|
||||
|
||||
1. Connect the **If-Else** component's **Text Input** port to a **Chat Input** component.
|
||||
2. In the If-Else component, enter the following values.
|
||||
* In the **Match Text** field, enter `.*(urgent|warning|caution).*`. The component looks for these values. The regex match is case sensitive, so to look for all permutations of `warning`, enter `warning|Warning|WARNING`.
|
||||
* In the **Operator** field, enter `regex`. The component looks for the strings `urgent`, `warning`, and `caution`. For more operators, see [Operator behavior](#operator-behavior).
|
||||
* In the **Message** field, enter `New Message Detected`. This field is optional. The message is sent to both the **True** and **False** ports.
|
||||
The component is now set up to send a `New Message Detected` message out of its **True** port if it matches any of the strings.
|
||||
If no strings are detected, it sends a message out of the **False** port.
|
||||
3. Create two identical flows to process the messages. Connect an **Open AI** component, a **Prompt**, and a **Chat Output** component together.
|
||||
4. Connect one chain to the **If-Else** component's **True** port, and one chain to the **False** port.
|
||||
By default, all operators are case insensitive except **regex**.
|
||||
**regex** is always case sensitive, and you can enable case sensitivity for all other operators in the [If-Else parameters](#if-else-parameters).
|
||||
|
||||
The flow looks like this:
|
||||
### Use the If-Else component in a flow
|
||||
|
||||
The following example uses the **If-Else** component to check incoming chat messages with regex matching, and then output a different response depending on whether the match evaluated to true or false.
|
||||
|
||||

|
||||
|
||||
5. Add your **OpenAI API key** to both **OpenAI** components.
|
||||
6. In both **Prompt** components, enter the behavior you want each route to take.
|
||||
When a match is found:
|
||||
```text
|
||||
Send a message that a new message has been received and added to the Urgent queue.
|
||||
```
|
||||
When a match is not found:
|
||||
```text
|
||||
Send a message that a new message has been received and added to the backlog.
|
||||
```
|
||||
7. Open the **Playground**.
|
||||
8. Send the flow some messages. Your messages route differently based on the if-else component's evaluation.
|
||||
```
|
||||
User
|
||||
A new user was created.
|
||||
1. Add an **If-Else** component to your flow, and then configure it as follows:
|
||||
|
||||
AI
|
||||
A new message has been received and added to the backlog.
|
||||
* **Text Input**: Connect the **Text Input** port to a **Chat Input** component.
|
||||
|
||||
User
|
||||
Sign-in warning: new user locked out.
|
||||
* **Match Text**: Enter `.*(urgent|warning|caution).*` so the component looks for these values in incoming input. The regex match is case sensitive, so if you need to look for all permutations of `warning`, enter `warning|Warning|WARNING`.
|
||||
|
||||
AI
|
||||
A new message has been received and added to the Urgent queue. Please review it at your earliest convenience.
|
||||
```
|
||||
* **Operator**: Select **regex**.
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
* **Case True**: In the [component's header menu](/concepts-components#component-menus), click <Icon name="SlidersHorizontal" aria-hidden="true"/> **Controls**, enable the **Case True** parameter, click **Close**, and then enter `New Message Detected` in the field.
|
||||
|
||||
**Inputs**
|
||||
The **Case True** message is sent from the **True** output port when the match condition evaluates to true.
|
||||
|
||||
No message is set for **Case False** so the component doesn't emit a message when the condition evaluates to false.
|
||||
|
||||
3. Depending on what you want to happen when the outcome is **True**, add components to your flow to execute that logic:
|
||||
|
||||
1. Add a **Language Model**, **Prompt Template**, and **Chat Output** component to your flow.
|
||||
|
||||
2. In the **Language Model** component, enter your OpenAI API key or select a different provider and model.
|
||||
|
||||
3. Connect the **If-Else** component's **True** output port to the **Language Model** component's **Input** port.
|
||||
|
||||
4. In the **Prompt Template** component, enter a prompt to instruct the model in the event of the `true` condition, such as `Send a message that a new warning, caution, or urgent message was received`.
|
||||
|
||||
5. Connect the **Prompt Template** component to the **Language Model** component's **System Message** port.
|
||||
|
||||
6. Connect the **Language Model** component's output to the **Chat Output** component.
|
||||
|
||||
4. Repeat the same process with another set of **Language Model**, **Prompt Template**, and **Chat Output** components for the **False** outcome.
|
||||
|
||||
Connect the **If-Else** component's **False** output port to the second **Language Model** component's **Input** port.
|
||||
|
||||
Be sure to configure the second **Prompt Template** component to instruct the model in the event of the `false` condition, such as `Send a message that a new low-priority message was received`.
|
||||
|
||||
5. To test the flow, open the **Playground**, and then send the flow some messages with and without your regex strings.
|
||||
The chat output should reflect the instructions in your prompts based on the regex evaluation.
|
||||
|
||||
```text
|
||||
User: A new user was created.
|
||||
|
||||
AI: A new low-priority message was received.
|
||||
|
||||
User: Sign-in warning: new user locked out.
|
||||
|
||||
AI: A new warning, caution, or urgent message was received. Please review it at your earliest convenience.
|
||||
```
|
||||
|
||||
### If-Else parameters
|
||||
|
||||
Some **If-Else** component input parameters are hidden by default in the visual editor.
|
||||
You can toggle parameters through the <Icon name="SlidersHorizontal" aria-hidden="true"/> **Controls** in the [component's header menu](/concepts-components#component-menus).
|
||||
|
||||
| Name | Type | Description |
|
||||
|----------------|----------|-------------------------------------------------------------------|
|
||||
| input_text | String | The primary text input for the operation. |
|
||||
| match_text | String | The text to compare against. |
|
||||
| operator | Dropdown | The operator used to compare texts. Options include equals, not equals, contains, starts with, ends with, and regex. The default is equals. |
|
||||
| case_sensitive | Boolean | When set to true, the comparison is case sensitive. This setting does not apply to regex comparison. The default is false. |
|
||||
| message | Message | The message to pass through either route. |
|
||||
| max_iterations | Integer | The maximum number of iterations allowed for the conditional router. The default is 10. |
|
||||
| default_route | Dropdown | The route to take when max iterations are reached. Options include true_result or false_result. The default is false_result. |
|
||||
|
||||
**Outputs**
|
||||
|
||||
| Name | Type | Description |
|
||||
|--------------|---------|--------------------------------------------|
|
||||
| true_result | Message | The output produced when the condition is true. |
|
||||
| false_result | Message | The output produced when the condition is false. |
|
||||
|
||||
</details>
|
||||
|
||||
### Operator Behavior
|
||||
|
||||
The **If-else** component includes a comparison operator to compare the values in `input_text` and `match_text`.
|
||||
|
||||
All options respect the `case_sensitive` setting except **regex**.
|
||||
|
||||
- **equals**: Exact match comparison.
|
||||
- **not equals**: Inverse of exact match.
|
||||
- **contains**: Checks if match_text is found within input_text.
|
||||
- **starts with**: Checks if input_text begins with match_text.
|
||||
- **ends with**: Checks if input_text ends with match_text.
|
||||
- **regex**: Performs regular expression matching. It is always case sensitive and ignores the case_sensitive setting.
|
||||
| input_text | String | Input parameter. The primary text input for the operation. |
|
||||
| match_text | String | Input parameter. The text to compare against. |
|
||||
| operator | Dropdown | Input parameter. The operator used to compare texts. Options include `equals`, `not equals`, `contains`, `starts with`, `ends with`, and `regex`. The default is `equals`. |
|
||||
| case_sensitive | Boolean | Input parameter. When set to true, the comparison is case sensitive. The default is false. This setting doesn't apply to regex comparisons. |
|
||||
| message | Message | Input parameter. The message to pass through either route. |
|
||||
| max_iterations | Integer | Input parameter. The maximum number of iterations allowed for the conditional router. The default is 10. |
|
||||
| default_route | Dropdown | Input parameter. The route to take when max iterations are reached. Options include `true_result` or `false_result`. The default is `false_result`. |
|
||||
| true_result | Message | Output parameter. The output produced when the condition is true. |
|
||||
| false_result | Message | Output parameter. The output produced when the condition is false. |
|
||||
|
||||
## Loop
|
||||
|
||||
:::tip
|
||||
For another **Loop** component example, see the **Research Translation Loop** template.
|
||||
:::
|
||||
The **Loop** component iterates over a list of input by passing individual items to other components attached at the **Item** output port until there are no items left to process. Then, the **Loop** component passes the aggregated result of all looping to the component connected to the **Done** port.
|
||||
|
||||
This component iterates over a list of [Data](/data-types#data) objects, outputting one item at a time and aggregating results from loop inputs.
|
||||
The **Loop** component is like a miniature flow within your flow.
|
||||
Here's a breakdown of the looping process:
|
||||
|
||||
In this example, the **Loop** component iterates over a CSV file through the **Item** port until there are no rows left to process. Then, the **Loop** component performs the actions connected to the **Done** port, which in this case is loading the structured data into **Chroma DB**.
|
||||
1. Accepts a list of [`Data`](/data-types#data) or [`DataFrame`](/data-types#dataframe) objects, such as a CSV file, through the **Loop** component's **Inputs** port.
|
||||
|
||||
Think of it this way: the **Item** port forms the "main" loop that repeats until a "complete" condition is reached.
|
||||
2. Splits the input into individual items. For example, a CSV file is broken down by rows.
|
||||
|
||||
1. The **Loop** component accepts **Data** from the **Load CSV** component, and outputs the data from the **Item** port.
|
||||
2. Each CSV row is converted to a **Message** and processed into structured data with the **Structured Output** component.
|
||||
The dotted line connected from the **Structured Output** component's **Looping** port tells you where the loop begins again.
|
||||
3. The **Loop** component repeatedly extracts rows by **Text Key** until there are no more rows to extract.
|
||||
Specifically, the **Loop** component repeatedly extracts items by `text` key in the `Data` or `DataFrame` objects until there are no more items to extract.
|
||||
Each `item` output is a `Data` objects.
|
||||
|
||||
Once all items are processed, the action connected to the **Done** port is performed.
|
||||
In this example, the data is loaded into **Chroma DB**.
|
||||
3. Iterates over each `item` by passing them to the **Item** output port.
|
||||
|
||||
This port connects to one or more components that perform actions on each item.
|
||||
The final component in the **Item** loop connects back to the **Loop** component's **Looping** port to process the next item.
|
||||
|
||||
Only one component connects to the **Item** port, but you can pass the data through as many components as you need, as long as the last component in the chain connects back to the **Looping** port.
|
||||
|
||||
4. After processing all items, the results are aggregated into a single `Data` object that is passed from the **Loop** component's **Done** port to the next component in the flow.
|
||||
|
||||
In terms of simplified code, the **Loop** component works like this:
|
||||
|
||||
```python
|
||||
for i in input: # Receive input data as a list
|
||||
process_item(i) # Process each item through components connected at the Item port
|
||||
if has_more_items():
|
||||
continue # Loop back to Looping port to process the next item
|
||||
else:
|
||||
break # Exit the loop when no more items are left
|
||||
|
||||
done = aggregate_results() # Compile all returned items
|
||||
|
||||
print(done) # Send the aggregated results from the Done port to another component
|
||||
```
|
||||
|
||||
<details>
|
||||
<summary>Loop example</summary>
|
||||
|
||||
In the follow example, the **Loop** component iterates over a CSV file until there are no rows left to process.
|
||||
In this case, the **Item** port passes each row to a **Type Convert** component to convert the row into a `Message` object, passes the `Message` to a **Structured Output** component to be processed into structured data that is then passed back to the **Loop** component's **Looping** port.
|
||||
After processing all rows, the **Loop** component loads the aggregated list of structured data into a Chroma DB database through the **Chroma DB** component connected to the **Done** port.
|
||||
|
||||

|
||||
|
||||
Follow along with this step-by-step video guide for creating this flow and adding agentic RAG: [Mastering the Loop Component & Agentic RAG in Langflow](https://www.youtube.com/watch?v=9Wx7WODSKTo).
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
|
||||
**Inputs**
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|-----------|------------------------------------------------------|
|
||||
| data | Data/List | The initial list of Data objects to process. |
|
||||
|
||||
**Outputs**
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|---------|-------------------------------------------------------|
|
||||
| item | Data | The current item being processed from the data list. |
|
||||
| done | Data | The aggregated results after all items are processed. |
|
||||
:::tip
|
||||
For more examples of the **Loop** component, try the **Research Translation Loop** template in Langflow, or follow this video tutorial for creating a flow with a loop and agentic RAG: [Mastering the Loop Component & Agentic RAG in Langflow](https://www.youtube.com/watch?v=9Wx7WODSKTo).
|
||||
:::
|
||||
|
||||
</details>
|
||||
|
||||
## Notify and Listen
|
||||
|
||||
The **Notify** and **Listen** components are used together.
|
||||
|
||||
The **Notify** component builds a notification from the current flow's context, including specific data content and a status identifier.
|
||||
|
||||
The resulting notification is sent to the **Listen** component.
|
||||
The notification data can then be passed to other components in the flow, such as the **If-Else** component.
|
||||
|
||||
## Run flow
|
||||
|
||||
This component allows you to run any flow stored in your Langflow database without opening the flow editor.
|
||||
The **Run Flow** component runs another Langflow flow as a subprocess of the current flow.
|
||||
|
||||
The Run Flow component can also be used as a tool when connected to an [Agent](/components-agents). The `name` and `description` metadata that the Agent uses to register the tool are created automatically.
|
||||
You can use this component to chain flows together, run flows conditionally, and attach flows to [**Agent** component](/components-agents) as [tools for the agent](/agents-tools) to run as needed.
|
||||
|
||||
When you select a flow, the component fetches the flow's graph structure and uses it to generate the inputs and outputs for the Run Flow component.
|
||||
When used with an agent, the `name` and `description` metadata that the agent uses to register the tool are created automatically.
|
||||
|
||||
To use the Run Flow component as a tool, do the following:
|
||||
1. Add the **Run Flow** component to the [Simple Agent](/simple-agent) flow.
|
||||
2. In the **Flow Name** menu, select the sub-flow you want to run.
|
||||
The appearance of the **Run Flow** component changes to reflect the inputs and outputs of the selected flow.
|
||||
3. On the **Run Flow** component, enable **Tool Mode**.
|
||||
4. Connect the **Run Flow** component to the **Toolset** input of the Agent.
|
||||
Your flow should now look like this:
|
||||

|
||||
5. Run the flow. The Agent uses the Run Flow component as a tool to run the selected sub-flow.
|
||||
When you select a flow for the **Run Flow** component, it uses the target flow's graph structure to dynamically generate input and output fields on the **Run Flow** component.
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
### Run Flow parameters
|
||||
|
||||
**Inputs**
|
||||
Some **Run Flow** component input parameters are hidden by default in the visual editor.
|
||||
You can toggle parameters through the <Icon name="SlidersHorizontal" aria-hidden="true"/> **Controls** in the [component's header menu](/concepts-components#component-menus).
|
||||
|
||||
| Name | Type | Description |
|
||||
|-------------------|----------|----------------------------------------------------------------|
|
||||
| flow_name_selected| Dropdown | The name of the flow to run. |
|
||||
| flow_tweak_data | Dict | Dictionary of tweaks to customize the flow's behavior. |
|
||||
| dynamic inputs | Various | Additional inputs that are generated based on the selected flow. |
|
||||
| flow_name_selected| Dropdown | Input parameter. The name of the flow to run. |
|
||||
| session_id | String | Input parameter. The session ID for the flow run, if you want to pass a custom session ID for the subflow. |
|
||||
| flow_tweak_data | Dict | Input parameter. Dictionary of tweaks to customize the flow's behavior. Available tweaks depend on the selected flow. |
|
||||
| dynamic inputs | Various | Input parameter. Additional inputs are generated based on the selected flow. |
|
||||
| run_outputs | A `List` of types (`Data`, `Message`, or `DataFrame`) | Output parameter. All outputs are generated from running the flow. |
|
||||
|
||||
**Outputs**
|
||||
## Legacy logic components
|
||||
|
||||
| Name | Type | Description |
|
||||
|--------------|-------------|---------------------------------------------------------------|
|
||||
| run_outputs | A `List` of types `Data`, `Message,` or `DataFrame` | All outputs are generated from running the flow. |
|
||||
The following logic components are legacy components.
|
||||
You can still use them in your flows, but they are no longer supported and can be removed in a future release.
|
||||
|
||||
</details>
|
||||
|
||||
## Legacy components
|
||||
|
||||
**Legacy** components are available for use but are no longer supported.
|
||||
|
||||
### Data Conditional Router
|
||||
|
||||
:::important
|
||||
This component is in **Legacy**, which means it is no longer in active development as of Langflow version 1.3.
|
||||
:::
|
||||
|
||||
This component routes `Data` objects based on a condition applied to a specified key, including boolean validation. It can process either a single Data object or a list of Data objects.
|
||||
|
||||
This component is particularly useful in workflows that require conditional routing of complex data structures, enabling dynamic decision-making based on data content.
|
||||
|
||||
#### Inputs
|
||||
|
||||
| Name | Type | Description |
|
||||
|---------------|----------|-----------------------------------------------------------------------------------|
|
||||
| data_input | Data | The Data object or list of Data objects to process. This input can handle both single items and lists. |
|
||||
| key_name | String | The name of the key in the Data object to check. |
|
||||
| operator | Dropdown | The operator to apply. Options: "equals", "not equals", "contains", "starts with", "ends with", "boolean validator". Default: "equals". |
|
||||
| compare_value | String | The value to compare against. Not shown/used when operator is "boolean validator". |
|
||||
|
||||
#### Outputs
|
||||
|
||||
| Name | Type | Description |
|
||||
|--------------|-------------|------------------------------------------------------|
|
||||
| true_output | Data/List | Output when the condition is met. |
|
||||
| false_output | Data/List | Output when the condition is not met. |
|
||||
|
||||
#### Operator behavior
|
||||
|
||||
- **equals**: Exact match comparison between the key's value and compare_value.
|
||||
- **not equals**: Inverse of exact match.
|
||||
- **contains**: Checks if compare_value is found within the key's value.
|
||||
- **starts with**: Checks if the key's value begins with compare_value.
|
||||
- **ends with**: Checks if the key's value ends with compare_value.
|
||||
- **boolean validator**: Treats the key's value as a boolean. The following values are considered true:
|
||||
- Boolean `true`.
|
||||
- Strings: "true", "1", "yes", "y", "on" (case-insensitive).
|
||||
- Any other value is converted using Python's `bool()` function.
|
||||
|
||||
#### List processing
|
||||
|
||||
The following actions occur when processing a list of Data objects:
|
||||
- Each object in the list is evaluated individually
|
||||
- Objects meeting the condition go to true_output
|
||||
- Objects not meeting the condition go to false_output
|
||||
- If all objects go to one output, the other output is empty
|
||||
|
||||
### Pass
|
||||
|
||||
:::important
|
||||
This component is in **Legacy**, which means it is available for use but no longer in active development.
|
||||
:::
|
||||
|
||||
This component forwards the input message, unchanged.
|
||||
Replace these components with suggested alternatives as soon as possible.
|
||||
Components marked deprecated in addition to legacy should be replaced immediately.
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
<summary>Condition/Data Conditional Router</summary>
|
||||
|
||||
**Inputs**
|
||||
As an alternative to this legacy component, see the [**If-Else** component](#if-else).
|
||||
|
||||
| Name | Display Name | Info |
|
||||
|------|--------------|------|
|
||||
| input_message | Input Message | The message to forward. |
|
||||
| ignored_message | Ignored Message | A second message that is ignored. Used as a workaround for continuity. |
|
||||
The **Condition** component routes `Data` objects based on a condition applied to a specified key, including Boolean validation.
|
||||
It supports `true_output` and `false_output` for routing the results based on the condition evaluation.
|
||||
|
||||
**Outputs**
|
||||
This component is useful in workflows that require conditional routing of complex data structures, enabling dynamic decision-making based on data content.
|
||||
|
||||
| Name | Display Name | Info |
|
||||
|------|--------------|------|
|
||||
| output_message | Output Message | The forwarded message from the input. |
|
||||
It can process either a single `Data` object or a list of `Data` objects.
|
||||
The following actions occur when processing a list of `Data` objects:
|
||||
|
||||
- Each object in the list is evaluated individually.
|
||||
- Objects meeting the condition go to `true_output`.
|
||||
- Objects not meeting the condition go to `false_output`.
|
||||
- If all objects go to one output, the other output is empty.
|
||||
|
||||
The **Condition** component accepts the following parameters:
|
||||
|
||||
| Name | Type | Description |
|
||||
|---------------|----------|---------------------------------------------|
|
||||
| data_input | Data | Input parameter. The Data object or list of Data objects to process. This input can handle both single items and lists. |
|
||||
| key_name | String | Input parameter. The name of the key in the Data object to check. |
|
||||
| operator | Dropdown | Input parameter. The operator to apply. Options: `equals`, `not equals`, `contains`, `starts with`, `ends with`, `boolean validator`. Default: `equals`. |
|
||||
| compare_value | String | Input parameter. The value to compare against. Not shown/used when operator is `boolean validator`. |
|
||||
|
||||
The `operator` options have the following behaviors:
|
||||
|
||||
- `equals`: Exact match comparison between the key's value and compare_value.
|
||||
- `not equals`: Inverse of exact match.
|
||||
- `contains`: Checks if compare_value is found within the key's value.
|
||||
- `starts with`: Checks if the key's value begins with compare_value.
|
||||
- `ends with`: Checks if the key's value ends with compare_value.
|
||||
- `boolean validator`: Treats the key's value as a Boolean. The following values are considered true:
|
||||
- Boolean `true`.
|
||||
- Strings: `true`, `1`, `yes`, `y`, `on` (case-insensitive)
|
||||
- Any other value is converted using Python's `bool()` function
|
||||
|
||||
</details>
|
||||
|
||||
## Deprecated components
|
||||
<details>
|
||||
<summary>Pass</summary>
|
||||
|
||||
Deprecated components have been replaced by newer alternatives and should not be used in new projects.
|
||||
As an alternative to this legacy component, use the [**If-Else** component](#if-else) to pass a message without modification.
|
||||
|
||||
### Flow as tool {#flow-as-tool}
|
||||
The **Pass** component forwards the input message without modification.
|
||||
|
||||
:::important
|
||||
This component is deprecated as of Langflow version 1.1.2.
|
||||
Instead, use the [Run flow component](/components-logic#run-flow)
|
||||
:::
|
||||
It accepts the following parameters:
|
||||
|
||||
This component constructs a tool from a function that runs a loaded flow.
|
||||
| Name | Display Name | Info |
|
||||
|------|--------------|------|
|
||||
| input_message | Input Message | Input parameter. The message to forward. |
|
||||
| ignored_message | Ignored Message | Input parameter. A second message that is ignored. Used as a workaround for continuity. |
|
||||
| output_message | Output Message | Output parameter. The forwarded message from the input. |
|
||||
|
||||
#### Inputs
|
||||
</details>
|
||||
|
||||
| Name | Type | Description |
|
||||
|------------------|----------|------------------------------------------------------------|
|
||||
| flow_name | Dropdown | The name of the flow to run. |
|
||||
| tool_name | String | The name of the tool. |
|
||||
| tool_description | String | The description of the tool. |
|
||||
| return_direct | Boolean | If true, returns the result directly from the tool. |
|
||||
<details>
|
||||
<summary>Flow As Tool (deprecated)</summary>
|
||||
|
||||
#### Outputs
|
||||
This component constructed a tool from a function that ran a loaded flow.
|
||||
|
||||
| Name | Type | Description |
|
||||
|----------------|------|----------------------------------------|
|
||||
| api_build_tool | Tool | The constructed tool from the flow. |
|
||||
It was deprecated in Langflow version 1.1.2 and replaced by the [**Run Flow** component](#run-flow).
|
||||
|
||||
### Sub flow
|
||||
</details>
|
||||
|
||||
:::important
|
||||
This component is deprecated as of Langflow version 1.1.2.
|
||||
Instead, use the [Run flow component](/components-logic#run-flow)
|
||||
:::
|
||||
<details>
|
||||
<summary>Sub Flow (deprecated)</summary>
|
||||
|
||||
This `SubFlowComponent` generates a component from a flow with all of its inputs and outputs.
|
||||
This component integrated entire flows as components within a larger workflow.
|
||||
It dynamically generated inputs based on the selected flow and executed the flow with provided parameters.
|
||||
|
||||
This component can integrate entire flows as components within a larger workflow. It dynamically generates inputs based on the selected flow and executes the flow with provided parameters.
|
||||
It was deprecated in Langflow version 1.1.2 and replaced by the [**Run Flow** component](#run-flow).
|
||||
|
||||
#### Inputs
|
||||
|
||||
| Name | Type | Description |
|
||||
|-----------|----------|------------------------------------|
|
||||
| flow_name | Dropdown | The name of the flow to run. |
|
||||
|
||||
#### Outputs
|
||||
|
||||
| Name | Type | Description |
|
||||
|--------------|-------------|---------------------------------------|
|
||||
| flow_outputs | List[Data] | The outputs generated from the flow. |
|
||||
</details>
|
||||
|
|
@ -3,25 +3,53 @@ title: Memories
|
|||
slug: /components-memories
|
||||
---
|
||||
|
||||
# Memory components in Langflow
|
||||
In Langflow version 1.5, the **Memory** category was removed.
|
||||
|
||||
Components in the **Memories** category are moved to [Bundles](/components-bundle-components) as of Langflow 1.5.
|
||||
All components that were in this category were replaced by other components or moved to other categories in the **Components** menu.
|
||||
|
||||
**Bundles** are third-party components grouped by provider.
|
||||
:::important
|
||||
Some components that were in the **Memory** category are legacy components.
|
||||
You can use these components in your flows, but they are no longer maintained and may be removed in a future release.
|
||||
|
||||
For more information on bundled components, see the component provider's documentation.
|
||||
It is recommended that you replace all legacy components with the replacement components described on this page.
|
||||
:::
|
||||
|
||||
## Use a memory component in a flow
|
||||
## Message History
|
||||
|
||||
Memory components store and retrieve chat messages by `session_id`.
|
||||
The [**Message History** component](/components-helpers#message-history) was moved to the **Helpers** category.
|
||||
This component combines the functionality of the legacy **Chat History** and **Message Store** components.
|
||||
|
||||
They are distinct from vector store components, because they are built specifically for storing and retrieving chat messages from external databases.
|
||||
## Message Store
|
||||
|
||||
Memory components provide access to their respective external databases **as memory**. This allows Large Language Models (LLMs) or [agents](/components-agents) to access external memory for persistence and context retention.
|
||||
The **Message Store** component is a legacy component.
|
||||
The functionality provided by this component is available in the **Message History** component.
|
||||
Replace this component with the [**Message History** component](/components-helpers#message-history).
|
||||
|
||||
This example flow stores and retrieves chat history with an **Redis Chat Memory** component connected to **Store Message** and **Message history** components.
|
||||
## Provider-specific chat memory components
|
||||
|
||||
The **Store Message** helper component stores chat memories as [Data](/data-types#data) objects, and the **Message History** helper component retrieves chat messages as [Data](/data-types#data) objects or strings.
|
||||
Provider-specific components were moved to the **Bundles** category:
|
||||
|
||||

|
||||
- [**Mem0 Chat Memory** component](/bundles-mem0)
|
||||
- [**Redis Chat Memory** component](/bundles-redis)
|
||||
- [**Cassandra Chat Memory** component](/bundles-datastax#cassandra-chat-memory)
|
||||
- [**Astra DB Chat Memory** component](/bundles-datastax#astra-db-chat-memory)
|
||||
|
||||
<details>
|
||||
<summary>Zep Chat Memory</summary>
|
||||
|
||||
The **Zep Chat Memory** component is a legacy component.
|
||||
Replace this component with the [**Message History** component](/components-helpers#message-history).
|
||||
|
||||
This component creates a `ZepChatMessageHistory` instance, enabling storage and retrieval of chat messages using Zep, a memory server for LLMs.
|
||||
|
||||
It accepts the following parameters:
|
||||
|
||||
| Name | Type | Description |
|
||||
|---------------|---------------|-----------------------------------------------------------|
|
||||
| url | MessageText | Input parameter. The URL of the Zep instance. Required. |
|
||||
| api_key | SecretString | Input parameter. The API Key for authentication with the Zep instance. |
|
||||
| api_base_path | Dropdown | Input parameter. The API version to use. Options include api/v1 or api/v2. |
|
||||
| session_id | MessageText | Input parameter. The unique identifier for the chat session. Optional. |
|
||||
| message_history | BaseChatMessageHistory | Output parameter. An instance of ZepChatMessageHistory for the session. |
|
||||
|
||||
</details>
|
||||
|
|
@ -1,64 +1,85 @@
|
|||
---
|
||||
title: Language models
|
||||
title: Language Model
|
||||
slug: /components-models
|
||||
---
|
||||
|
||||
import Icon from "@site/src/components/icon";
|
||||
|
||||
:::important
|
||||
In [Langflow version 1.5](/release-notes), the singular **Language model** component replaces many provider-specific model components. Any provider-specific model components that weren't incorporated into the singular component were moved to [Bundles](/components-bundle-components).
|
||||
:::
|
||||
Language model components in Langflow generate text using a specified Large Language Model (LLM).
|
||||
|
||||
Language components in Langflow generate text using the selected Large Language Model (LLM). The core **Language model** component supports many LLM providers, models, and use cases. For additional providers and models not supported by the core **Language model** component, see [**Bundles**](/components-bundle-components).
|
||||
Langflow includes a core **Language Model** component that has built-in support for many LLMs, as well as an interface to connect any [additional language model component](#additional-language-model-components).
|
||||
The built-in LLMs are appropriate for most text-based language model use cases in Langflow.
|
||||
|
||||
Most use cases can be performed with the **Language Model** and **Embedding Model** components.
|
||||
## Use language model components in a flow
|
||||
|
||||
If you want to try additional providers not supported by the new components, the single-provider LLM components of both the **Language Model** and **Embedding Model** types are now found in **Bundles**, and are still available for use.
|
||||
Use language model components anywhere you would use an LLM in a flow.
|
||||
|
||||
### Use a Language Model component in a flow
|
||||
These components accept inputs like chat messages, files, and instructions in order to generate a text response.
|
||||
The flow must include [**Chat Input/Output** component](/components-io#chat-io) to allow chat-based interactions with the LLM.
|
||||
However, you can also use the **Language Model** component for actions that don't emit chat output directly, such as the **Smart Function** component.
|
||||
|
||||
Use a **Language Model** component in your flow anywhere you would use an LLM.
|
||||
|
||||
Model components receive inputs and prompts for generating text, and the generated text is sent to an output component.
|
||||
|
||||
This example has the OpenAI model in a chatbot flow. For more information, see the [Basic prompting flow](/basic-prompting).
|
||||
The following example uses the core **Language Model** component and a built-in LLM to create a chatbot flow similar to the [**Basic Prompting** template](/basic-prompting).
|
||||
The example focuses on using the built-in models, but it also indicates where you can integrate another model.
|
||||
|
||||
1. Add the **Language Model** component to your flow.
|
||||
The default model is OpenAI's GPT-4.1 mini model. Based on [OpenAI's recommendations](https://platform.openai.com/docs/models/gpt-4.1-mini), this model is a good, balanced starter model.
|
||||
2. In the **OpenAI API Key** field, enter your OpenAI API key.
|
||||
3. Add a [Prompt](/components-prompts) component to your flow.
|
||||
4. To connect the [Prompt](/components-prompts) component to the **Language Model** component, on the **Language Model** component, click **Controls**.
|
||||
5. Enable the **System Message** setting.
|
||||
On the **Language Model** component, a new **System Message** port opens.
|
||||
6. Connect the **Prompt** port to the **System Message** port.
|
||||
7. Add [Chat input](/components-io#chat-input) and [Chat output](/components-io#chat-output) components to your flow.
|
||||
Your flow looks like this:
|
||||

|
||||
|
||||
8. Open the **Playground**, and ask a question.
|
||||
The bot responds to your question with sources.
|
||||
2. In the **OpenAI API Key** field, enter your OpenAI API key.
|
||||
|
||||
This example uses the default OpenAI model and a built-in Anthropic model to compare responses from different providers.
|
||||
|
||||
If you want to use a different provider, edit the **Model Provider**, **Model Name**, and **API Key** fields accordingly.
|
||||
|
||||
If you want to use provider or model that isn't built-in to the **Language Model** component, see [Additional language model components](#additional-language-model-components) to learn how to connect a **Custom** model provider to the **Language Model** component.
|
||||
Then, you can continue following these steps to build your flow.
|
||||
|
||||
3. In the [component's header menu](/concepts-components#component-menus), click <Icon name="SlidersHorizontal" aria-hidden="true"/> **Controls**, enable the **System Message** parameter, and then click **Close**.
|
||||
|
||||
4. Add a [**Prompt Template** component](/components-prompts) to your flow.
|
||||
|
||||
5. In the **Template** field, enter some instructions for the LLM, such as `You are an expert in geography who is tutoring high school students`.
|
||||
|
||||
6. Connect the **Prompt Template** component's output to the **Language Model** component's **System Message** input.
|
||||
|
||||
7. Add [**Chat Input** and **Chat Output** components](/components-io#chat-io) to your flow.
|
||||
|
||||
8. Connect the **Chat Input** component to the **Language Model** component's **Input**, and then connect the **Language Model** component's **Message** output to the **Chat Output** component.
|
||||
|
||||

|
||||
|
||||
9. Open the **Playground**, and ask a question to chat with the LLM and test the flow, such as `What is the capital of Utah?`.
|
||||
|
||||
<details>
|
||||
<summary>Result</summary>
|
||||
|
||||
The following response is an example of an OpenAI model's response.
|
||||
Your actual response may vary based on the model version at the time of your request, your template, and input.
|
||||
|
||||
```
|
||||
What is the capital of Utah?
|
||||
|
||||
AI
|
||||
gpt-4o-mini
|
||||
The capital of Utah is Salt Lake City. It is not only the largest city in the state but also serves as the cultural and economic center of Utah. Salt Lake City was founded in 1847 by Mormon pioneers and is known for its proximity to the Great Salt Lake and its role in the history of the Church of Jesus Christ of Latter-day Saints. For more information, you can refer to sources such as the U.S. Geological Survey or the official state website of Utah.
|
||||
```
|
||||
|
||||
9. Try an alternate model provider, and test how the response differs.
|
||||
In the **Language Model** component, in the **Model Provider** field, select **Anthropic**.
|
||||
10. In the **Model Name** field, select your Anthropic model.
|
||||
This model uses Claude 3.5 Haiku, based on [Anthropic's recommendation](https://docs.anthropic.com/en/docs/about-claude/models/choosing-a-model) for a fast and cost-effective model.
|
||||
11. In the **Anthropic API Key** field, enter your Anthropic API key.
|
||||
12. Open the **Playground**, and ask the same question as you did before.
|
||||
</details>
|
||||
|
||||
10. Try a different model or provider to see how the response changes. For example:
|
||||
|
||||
1. In the **Language Model** component, change the model provider to **Anthropic**.
|
||||
2. Select an Anthropic model, such as Claude 3.5 Haiku.
|
||||
3. Enter an Anthropic API key.
|
||||
|
||||
11. Open the **Playground**, ask the same question as you did before, and then compare the content and format of the responses.
|
||||
|
||||
This helps you understand how different models handle the same request so you can choose the best model for your use case.
|
||||
You can also learn more about different models in each model provider's documentation.
|
||||
|
||||
<details>
|
||||
<summary>Result</summary>
|
||||
|
||||
The following response is an example of an Anthropic model's response.
|
||||
Your actual response may vary based on the model version at the time of your request, your template, and input.
|
||||
|
||||
Note that this response is shorter and includes sources, whereas the OpenAI response was more encyclopedic and didn't cite sources.
|
||||
|
||||
```
|
||||
User
|
||||
What is the capital of Utah?
|
||||
|
||||
AI
|
||||
claude-3-5-haiku-latest
|
||||
The capital of Utah is Salt Lake City. It is also the most populous city in the state. Salt Lake City has been the capital of Utah since 1896, when Utah became a state.
|
||||
Sources:
|
||||
Utah State Government Official Website (utah.gov)
|
||||
|
|
@ -66,39 +87,55 @@ This model uses Claude 3.5 Haiku, based on [Anthropic's recommendation](https://
|
|||
Encyclopedia Britannica
|
||||
```
|
||||
|
||||
The response from the Anthropic model is less verbose, and lists its sources outside of the informative paragraph.
|
||||
For more information, see your LLM provider's documentation.
|
||||
</details>
|
||||
|
||||
### Use the LanguageModel output
|
||||
## Language Model parameters
|
||||
|
||||
The default output of the language model is the model's response as a `Message`, but it also supports a `LanguageModel` output.
|
||||
Select the Language Model's **LanguageModel** output to connect it to components that require an LLM.
|
||||
|
||||
For an example, see the [Smart function component](/components-processing#smart-function), which requires an LLM connected through this port to create a function from your natural language.
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
|
||||
**Inputs**
|
||||
Some **Language Model** component input parameters are hidden by default in the visual editor.
|
||||
You can toggle parameters through the <Icon name="SlidersHorizontal" aria-hidden="true"/> **Controls** in the [component's header menu](/concepts-components#component-menus).
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| provider | String | The model provider to use. |
|
||||
| model_name | String | The name of the model to use. Options depend on the selected provider. |
|
||||
| api_key | SecretString | The API Key for authentication with the selected provider. |
|
||||
| input_value | String | The input text to send to the model. |
|
||||
| system_message | String | A system message that helps set the behavior of the assistant. |
|
||||
| stream | Boolean | Whether to stream the response. Default: `False`. |
|
||||
| temperature | Float | Controls randomness in responses. Range: `[0.0, 1.0]`. Default: `0.1`. |
|
||||
| provider | String | Input parameter. The model provider to use. |
|
||||
| model_name | String | Input parameter. The name of the model to use. Options depend on the selected provider. |
|
||||
| api_key | SecretString | Input parameter. The API Key for authentication with the selected provider. |
|
||||
| input_value | String | Input parameter. The input text to send to the model. |
|
||||
| system_message | String | Input parameter. A system message that helps set the behavior of the assistant. |
|
||||
| stream | Boolean | Input parameter. Whether to stream the response. Default: `False`. |
|
||||
| temperature | Float | Input parameter. Controls randomness in responses. Range: `[0.0, 1.0]`. Default: `0.1`. |
|
||||
| model | LanguageModel | Output parameter. Alternative output type to the default `Message` output. Produces an instance of Chat configured with the specified parameters. See [Language Model output types](#language-model-output-types). |
|
||||
|
||||
**Outputs**
|
||||
## Language Model output types
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| model | LanguageModel | An instance of Chat configured with the specified parameters. |
|
||||
**Language Model** components, including the core component and bundled components, can produce two types of output:
|
||||
|
||||
</details>
|
||||
* **Model Response**: The default output type emits the model's generated response as [`Message` data](/data-types#message).
|
||||
Use this output type when you want the typical LLM interaction where the LLM produces a text response based on given input.
|
||||
|
||||
## Language models bundles
|
||||
* **Language Model**: Change the **Language Model** component's output type to [`LanguageModel`](/data-types#languagemodel) when you need to attach an LLM to another component in your flow.
|
||||
This is a specific data type that is only required by certain components, such as the [**Smart Function** component](/components-processing#smart-function).
|
||||
|
||||
If your provider or model isn't supported by the core **Language model** component, see [Bundles](/components-bundle-components) for additional language model and embedding model components developed by third-party contributors.
|
||||
With this configuration, the **Language Model** component is meant to support an action completed by another component, rather than producing a text response for a standard chat-based interaction.
|
||||
For an example, the **Smart Function** component uses an LLM to create a function from natural language input.
|
||||
|
||||
## Additional language model components
|
||||
|
||||
If your provider or model isn't supported by the core **Language Model** component, additional single-provider language model components are available in the [**Bundles**](/components-bundle-components) section of the **Components** menu.
|
||||
|
||||
You can use bundled components directly in your flows or you can connect them to other components that accept a [`LanguageModel`](/data-types#languagemodel) input, such as the **Language Model** and **Agent** components.
|
||||
|
||||
For example, to connect bundled components to the core **Language Model** component, do the following:
|
||||
|
||||
1. In the **Language Model** component, set **Model Provider** to **Custom**.
|
||||
|
||||
The field name changes to **Language Model** and the input port changes to a `LanguageModel` port.
|
||||
|
||||
2. Add a compatible bundled component to your flow, such as the [**Vertex AI** component for text generation](/bundles-vertexai).
|
||||
|
||||
3. Change the bundled component's output type to `LanguageModel`.
|
||||
To do this, click **Model Response** near the component's output port, and then select **Language Model**.
|
||||
For more information, see [Language Model output types](#language-model-output-types).
|
||||
|
||||
4. Connect the bundled component's output to the **Language Model** component's `LanguageModel` input port.
|
||||
|
||||
The bundled component now provides the LLM configuration for the component that it is connected to, and you can continue building your flow as needed.
|
||||
|
|
@ -1,123 +1,157 @@
|
|||
---
|
||||
title: Processing
|
||||
title: Processing components
|
||||
slug: /components-processing
|
||||
---
|
||||
|
||||
import Icon from "@site/src/components/icon";
|
||||
|
||||
Processing components process and transform data within a flow, like converting `Data` to text with a [Parser](#parser) component, filtering data with natural language with the [Smart function](#smart-function), or saving data to your local machine with [Save File](#save-file).
|
||||
Langflow's processing components process and transform data within a flow.
|
||||
They have many uses, including:
|
||||
|
||||
* Feed instructions and context to your LLMs and agents with the [**Prompt Template** component](#prompt-template).
|
||||
* Extract content from larger chunks of data with a [**Parser** component](#parser).
|
||||
* Filter data with natural language with the [**Smart Function** component](#smart-function).
|
||||
* Save data to your local machine with the [**Save File** component](#save-file).
|
||||
* Transform data into a different data type with the [**Type Convert** component](#type-convert) to pass it between incompatible components.
|
||||
|
||||
## Prompt Template
|
||||
|
||||
See [Prompt Template](/components-prompts).
|
||||
|
||||
## Batch Run
|
||||
|
||||
The **Batch Run** component runs a language model over **each row** of a [DataFrame](/data-types#dataframe) text column and returns a new DataFrame with the original text and an LLM response.
|
||||
The **Batch Run** component runs a language model over _each row of one text column_ in a [`DataFrame`](/data-types#dataframe), and then returns a new `DataFrame` with the original text and an LLM response.
|
||||
|
||||
The response contains the following columns:
|
||||
|
||||
* `text_input`: The original text from the input DataFrame.
|
||||
* `model_response`: The model's response for each input.
|
||||
* `batch_index`: The processing order, with a `0`-based index.
|
||||
* `metadata` (optional): Additional information about the processing.
|
||||
* `text_input`: The original text from the input `DataFrame`
|
||||
* `model_response`: The model's response for each input
|
||||
* `batch_index`: The 0-indexed processing order for all rows in the `DataFrame`
|
||||
* `metadata` (optional): Additional information about the processing
|
||||
|
||||
These columns, when connected to a **Parser** component, can be used as variables within curly braces.
|
||||
### Use the Batch Run component in a flow
|
||||
|
||||
To use the Batch Run component with a **Parser** component, do the following:
|
||||
|
||||
1. Connect a **Model** component to the **Batch Run** component's **Language model** port.
|
||||
2. Connect a component that outputs DataFrame, like **File** component, to the **Batch Run** component's **DataFrame** input.
|
||||
3. Connect the **Batch Run** component's **Batch Results** output to a **Parser** component's **DataFrame** input.
|
||||
The flow looks like this:
|
||||
If you pass this output to a [**Parser** component](/components-processing#parser), you can use variables in the parsing template to reference these keys, such as `{text_input}` and `{model_response}`.
|
||||
This is demonstrated in the following example.
|
||||
|
||||

|
||||
|
||||
4. In the **Column Name** field of the **Batch Run** component, enter a column name based on the data you're loading from the **File** loader. For example, to process a column of `name`, enter `name`.
|
||||
5. Optionally, in the **System Message** field of the **Batch Run** component, enter a **System Message** to instruct the connected LLM on how to process your file. For example, `Create a business card for each name.`
|
||||
6. In the **Template** field of the **Parser** component, enter a template for using the **Batch Run** component's new DataFrame columns.
|
||||
To use all three columns from the **Batch Run** component, include them like this:
|
||||
```text
|
||||
record_number: {batch_index}, name: {text_input}, summary: {model_response}
|
||||
```
|
||||
7. To run the flow, in the **Parser** component, click <Icon name="Play" aria-hidden="True" /> **Run component**.
|
||||
8. To view your created DataFrame, in the **Parser** component, click <Icon name="TextSearch" aria-hidden="True" /> **Inspect output**.
|
||||
9. Optionally, connect a **Chat Output** component, and open the **Playground** to see the output.
|
||||
1. Connect a **Language Model** component to a **Batch Run** component's **Language model** port.
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
2. Connect `DataFrame` output from another component to the **Batch Run** component's **DataFrame** input.
|
||||
For example, you could connect a **File** component with a CSV file.
|
||||
|
||||
**Inputs**
|
||||
3. In the **Batch Run** component's **Column Name** field, enter the name of the column in the incoming `DataFrame` that contains the text to process.
|
||||
For example, if you want to extract text from a `name` column in a CSV file, enter `name` in the **Column Name** field.
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| model | HandleInput | Connect the 'Language Model' output from your LLM component here. Required. |
|
||||
| system_message | MultilineInput | A multi-line system instruction for all rows in the DataFrame. |
|
||||
| df | DataFrameInput | The DataFrame whose column is treated as text messages, as specified by 'column_name'. Required. |
|
||||
| column_name | MessageTextInput | The name of the DataFrame column to treat as text messages. If empty, all columns are formatted in TOML. |
|
||||
| output_column_name | MessageTextInput | Name of the column where the model's response is stored. Default=`model_response`. |
|
||||
| enable_metadata | BoolInput | If True, add metadata to the output DataFrame. |
|
||||
4. Connect the **Batch Run** component's **Batch Results** output to a **Parser** component's **DataFrame** input.
|
||||
|
||||
**Outputs**
|
||||
5. Optional: In the **Batch Run** [component's header menu](/concepts-components#component-menus), click <Icon name="SlidersHorizontal" aria-hidden="true"/> **Controls**, enable the **System Message** parameter, click **Close**, and then enter an instruction for how you want the LLM to process each cell extracted from the file.
|
||||
For example, `Create a business card for each name.`
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| batch_results | DataFrame | A DataFrame with all original columns plus the model's response column. |
|
||||
6. In the **Parser** component's **Template** field, enter a template for processing the **Batch Run** component's new `DataFrame` columns (`text_input`, `model_response`, and `batch_index`):
|
||||
|
||||
</details>
|
||||
For example, this template uses three columns from the resulting, post-batch `DataFrame`:
|
||||
|
||||
## Data operations
|
||||
|
||||
This component performs operations on [Data](/data-types#data) objects, including selecting keys, evaluating literals, combining data, filtering values, appending/updating data, removing keys, and renaming keys.
|
||||
|
||||
1. To use this component in a flow, connect a component that outputs [Data](/data-types#data) to the **Data Operations** component's input.
|
||||
All operations in the component require at least one [Data](/data-types#data) input.
|
||||
2. In the **Operations** field, select the operation you want to perform.
|
||||
For example, send this request to the **Webhook** component.
|
||||
Replace `FLOW_ID` and `LANGFLOW_API_KEY` with the values from your deployment.
|
||||
```bash
|
||||
curl -X POST "http://localhost:7860/api/v1/webhook/FLOW_ID" \
|
||||
-H 'Content-Type: application/json' \
|
||||
-H 'x-api-key: LANGFLOW_API_KEY' \
|
||||
-d '{
|
||||
"id": 1,
|
||||
"name": "Leanne Graham",
|
||||
"username": "Bret",
|
||||
"email": "Sincere@april.biz",
|
||||
"address": {
|
||||
"street": "Kulas Light",
|
||||
"suite": "Apt. 556",
|
||||
"city": "Gwenborough",
|
||||
"zipcode": "92998-3874",
|
||||
"geo": {
|
||||
"lat": "-37.3159",
|
||||
"lng": "81.1496"
|
||||
}
|
||||
},
|
||||
"phone": "1-770-736-8031 x56442",
|
||||
"website": "hildegard.org",
|
||||
"company": {
|
||||
"name": "Romaguera-Crona",
|
||||
"catchPhrase": "Multi-layered client-server neural-net",
|
||||
"bs": "harness real-time e-markets"
|
||||
}
|
||||
}'
|
||||
```
|
||||
|
||||
3. In the **Data Operations** component, select the **Select Keys** operation to extract specific user information.
|
||||
To add additional keys, click <Icon name="Plus" aria-hidden="True" /> **Add more**.
|
||||

|
||||
4. Filter by `name`, `username`, and `email` to select the values from the request.
|
||||
```json
|
||||
{
|
||||
"name": "Leanne Graham",
|
||||
"username": "Bret",
|
||||
"email": "Sincere@april.biz"
|
||||
}
|
||||
```text
|
||||
record_number: {batch_index}, name: {text_input}, summary: {model_response}
|
||||
```
|
||||
|
||||
### Operations
|
||||
7. To test the processing, click the **Parser** component, and then click <Icon name="Play" aria-hidden="True" /> **Run component**, and then click <Icon name="TextSearch" aria-hidden="True" /> **Inspect output** to view the final `DataFrame`.
|
||||
|
||||
The component supports the following operations.
|
||||
All operations in the **Data operations** component require at least one [Data](/data-types#data) input.
|
||||
You can also connect a **Chat Output** component to the **Parser** component if you want to see the output in the **Playground**.
|
||||
|
||||
| Operation | Required Inputs | Info |
|
||||
### Batch Run parameters
|
||||
|
||||
Some **Batch Run** component input parameters are hidden by default in the visual editor.
|
||||
You can toggle parameters through the <Icon name="SlidersHorizontal" aria-hidden="true"/> **Controls** in the [component's header menu](/concepts-components#component-menus).
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| model | HandleInput | Input parameter. Connect the 'Language Model' output from your LLM component here. Required. |
|
||||
| system_message | MultilineInput | Input parameter. A multi-line system instruction for all rows in the DataFrame. |
|
||||
| df | DataFrameInput | Input parameter. The DataFrame whose column is treated as text messages, as specified by 'column_name'. Required. |
|
||||
| column_name | MessageTextInput | Input parameter. The name of the DataFrame column to treat as text messages. If empty, all columns are formatted in TOML. |
|
||||
| output_column_name | MessageTextInput | Input parameter. Name of the column where the model's response is stored. Default=`model_response`. |
|
||||
| enable_metadata | BoolInput | Input parameter. If True, add metadata to the output DataFrame. |
|
||||
| batch_results | DataFrame | Output parameter. A DataFrame with all original columns plus the model's response column. |
|
||||
|
||||
## Data Operations
|
||||
|
||||
The **Data Operations** component performs operations on [`Data`](/data-types#data) objects, including selecting keys, evaluating literals, combining data, filtering values, appending/updating data, removing keys, and renaming keys.
|
||||
|
||||
1. To use the **Data Operations** component in a flow, you must connect its **Data** input port to the output port of a component that outputs `Data`.
|
||||
All operations in the **Data Operations** component require at least one `Data` input.
|
||||
|
||||
For this example, add a **Webhook** component to the flow, and then connect it to a **Data Operations** component. Assume you'll send requests to the webhook with a consistent payload that has `name`, `username`, and `email` keys.
|
||||
|
||||
2. In the **Operations** field, select the operation you want to perform on the incoming `Data`.
|
||||
For this example, select the **Select Keys** operation to extract specific user information.
|
||||
|
||||
3. Add keys for `name`, `username`, and `email` to select those values from the incoming request payload.
|
||||
|
||||
To add additional keys, click <Icon name="Plus" aria-hidden="True" /> **Add more**.
|
||||
|
||||
4. Connect a **Chat Output** component.
|
||||
|
||||
|
||||

|
||||
|
||||
5. To test the flow, send the following request to your flow's webhook endpoint, and then open the **Playground** to see the resulting output from processing the payload.
|
||||
|
||||
```bash
|
||||
curl -X POST "http://$LANGFLOW_SERVER_URL/api/v1/webhook/$FLOW_ID" \
|
||||
-H "Content-Type: application/json" \
|
||||
-H "x-api-key: $LANGFLOW_API_KEY" \
|
||||
-d '{
|
||||
"id": 1,
|
||||
"name": "Leanne Graham",
|
||||
"username": "Bret",
|
||||
"email": "Sincere@april.biz",
|
||||
"address": {
|
||||
"street": "Main Street",
|
||||
"suite": "Apt. 556",
|
||||
"city": "Springfield",
|
||||
"zipcode": "92998-3874",
|
||||
"geo": {
|
||||
"lat": "-37.3159",
|
||||
"lng": "81.1496"
|
||||
}
|
||||
},
|
||||
"phone": "1-770-736-8031 x56442",
|
||||
"website": "hildegard.org",
|
||||
"company": {
|
||||
"name": "Acme-Corp",
|
||||
"catchPhrase": "Multi-layered client-server neural-net",
|
||||
"bs": "harness real-time e-markets"
|
||||
}
|
||||
}'
|
||||
```
|
||||
|
||||
### Data Operations parameters
|
||||
|
||||
Some **Data Operations** component input parameters are hidden by default in the visual editor.
|
||||
You can toggle parameters through the <Icon name="SlidersHorizontal" aria-hidden="true"/> **Controls** in the [component's header menu](/concepts-components#component-menus).
|
||||
|
||||
| Name | Display Name | Info |
|
||||
|------|--------------|------|
|
||||
| data | Data | Input parameter. The `Data` object to operate on. |
|
||||
| operations | Operations | Input parameter. The operation to perform on the data. See [Data Operations operations](#data-operations-operations) |
|
||||
| select_keys_input | Select Keys | Input parameter. A list of keys to select from the data. |
|
||||
| filter_key | Filter Key | Input parameter. The key to filter by. |
|
||||
| operator | Comparison Operator | Input parameter. The operator to apply for comparing values. |
|
||||
| filter_values | Filter Values | Input parameter. A list of values to filter by. |
|
||||
| append_update_data | Append or Update | Input parameter. The data to append or update the existing data with. |
|
||||
| remove_keys_input | Remove Keys | Input parameter. A list of keys to remove from the data. |
|
||||
| rename_keys_input | Rename Keys | Input parameter. A list of keys to rename in the data. |
|
||||
| data_output | Data | Output parameter. The resulting Data object after the operation. |
|
||||
|
||||
### Data Operations operations
|
||||
|
||||
Options for the `operations` input parameter are as follows.
|
||||
All operations act on an incoming `Data` object.
|
||||
|
||||
| Name | Required Inputs | Process |
|
||||
|-----------|----------------|-------------|
|
||||
| Select Keys | `select_keys_input` | Selects specific keys from the data. |
|
||||
| Literal Eval | None | Evaluates string values as Python literals. |
|
||||
|
|
@ -127,40 +161,16 @@ All operations in the **Data operations** component require at least one [Data](
|
|||
| Remove Keys | `remove_keys_input` | Removes specified keys from the data. |
|
||||
| Rename Keys | `rename_keys_input` | Renames keys in the data. |
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
|
||||
**Inputs**
|
||||
|
||||
| Name | Display Name | Info |
|
||||
|------|--------------|------|
|
||||
| data | Data | The [Data](/data-types#data) object to operate on. |
|
||||
| operations | Operations | The operation to perform on the data. |
|
||||
| select_keys_input | Select Keys | A list of keys to select from the data. |
|
||||
| filter_key | Filter Key | The key to filter by. |
|
||||
| operator | Comparison Operator | The operator to apply for comparing values. |
|
||||
| filter_values | Filter Values | A list of values to filter by. |
|
||||
| append_update_data | Append or Update | The data to append or update the existing data with. |
|
||||
| remove_keys_input | Remove Keys | A list of keys to remove from the data. |
|
||||
| rename_keys_input | Rename Keys | A list of keys to rename in the data. |
|
||||
|
||||
**Outputs**
|
||||
|
||||
| Name | Display Name | Info |
|
||||
|------|--------------|------|
|
||||
| data_output | Data | The resulting Data object after the operation. |
|
||||
|
||||
</details>
|
||||
|
||||
## DataFrame operations
|
||||
|
||||
This component performs operations on [DataFrame](https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.html) rows and columns.
|
||||
The **DataFrame** component performs operations on [`DataFrame`](https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.html) rows and columns.
|
||||
|
||||
To use this component in a flow, connect a component that outputs [DataFrame](/data-types#dataframe) to the **DataFrame Operations** component.
|
||||
To use the **DataFrame Operations** component in a flow, you must connect its **DataFrame** input port to the output port of a component that outputs `DataFrame`.
|
||||
All operations in the **DataFrame Operations** component require at least one `DataFrame` input.
|
||||
|
||||
This example fetches JSON data from an API. The **Smart Filter** component extracts and flattens the results into a tabular DataFrame. The **DataFrame Operations** component can then work with the retrieved data.
|
||||
The following example fetches JSON data from an API. The **Smart Filter** component extracts and flattens the results into a tabular `DataFrame` that is then processed through the **DataFrame Operations** component.
|
||||
|
||||

|
||||

|
||||
|
||||
1. The **API Request** component retrieves data with only `source` and `result` fields.
|
||||
For this example, the desired data is nested within the `result` field.
|
||||
|
|
@ -361,10 +371,12 @@ For an additional example of using the **Parser** component to format a DataFram
|
|||
|
||||
</details>
|
||||
|
||||
## Python interpreter
|
||||
## Python Interpreter
|
||||
|
||||
This component allows you to execute Python code with imported packages.
|
||||
|
||||
### Use the Python Interpreter in a flow
|
||||
|
||||
1. To use this component in a flow,in the **Global Imports** field, add the packages you want to import as a comma-separated list, such as `math,pandas`.
|
||||
At least one import is required.
|
||||
2. In the **Python Code** field, enter the Python code you want to execute. Use `print()` to see the output.
|
||||
|
|
@ -427,23 +439,13 @@ Output:
|
|||
|
||||
If you don't include the package imports in the chat, the Agent can still create the table using `pd.DataFrame`, because the `pandas` package is imported globally by the Python interpreter component in the **Global Imports** field.
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
|
||||
**Inputs**
|
||||
### Python Interpreter parameters
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| global_imports | String | A comma-separated list of modules to import globally, such as `math,pandas,numpy`. |
|
||||
| python_code | Code | The Python code to execute. Only modules specified in Global Imports can be used. |
|
||||
|
||||
**Outputs**
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| results | Data | The output of the executed Python code, including any printed results or errors. |
|
||||
|
||||
</details>
|
||||
| global_imports | String | Input parameter. A comma-separated list of modules to import globally, such as `math,pandas,numpy`. |
|
||||
| python_code | Code | Input parameter. The Python code to execute. Only modules specified in Global Imports can be used. |
|
||||
| results | Data | Output parameter. The output of the executed Python code, including any printed results or errors. |
|
||||
|
||||
## Save file
|
||||
|
||||
|
|
@ -567,7 +569,7 @@ The connected LLM creates a filter based on the instructions, and successfully e
|
|||
|
||||
</details>
|
||||
|
||||
## Split text
|
||||
## Split Text
|
||||
|
||||
This component splits text into chunks based on specified criteria. It's ideal for chunking data to be tokenized and embedded into vector databases.
|
||||
|
||||
|
|
@ -640,6 +642,10 @@ Third chunk: "s of Artificial Intelligence and its applications"
|
|||
|
||||
</details>
|
||||
|
||||
### Other text splitters
|
||||
|
||||
- [LangChain text splitter components](/bundles-langchain#text-splitters)
|
||||
|
||||
## Structured output
|
||||
|
||||
This component transforms LLM responses into structured data formats.
|
||||
|
|
@ -761,447 +767,259 @@ Ozone Pollution and Global Warming: A recent study highlights that ozone polluti
|
|||
|
||||
</details>
|
||||
|
||||
## Legacy components
|
||||
## Legacy processing components
|
||||
|
||||
**Legacy** components are available for use but are no longer supported.
|
||||
The following processing components are legacy components.
|
||||
You can still use them in your flows, but they are no longer supported and can be removed in a future release.
|
||||
|
||||
### Alter metadata
|
||||
|
||||
:::important
|
||||
This component is in **Legacy**, which means it is available for use but no longer in active development.
|
||||
Instead, use the [Data operations](#data-operations) component.
|
||||
:::
|
||||
|
||||
This component modifies metadata of input objects. It can add new metadata, update existing metadata, and remove specified metadata fields. The component works with both [Message](/data-types#message) and [Data](/data-types#data) objects, and can also create a new Data object from user-provided text.
|
||||
Replace these components with suggested alternatives as soon as possible.
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
<summary>Alter Metadata</summary>
|
||||
|
||||
**Inputs**
|
||||
Replace this legacy component with the [**Data Operations** component](#data-operations).
|
||||
|
||||
This component modifies metadata of input objects. It can add new metadata, update existing metadata, and remove specified metadata fields. The component works with both `Message` and `Data` objects, and can also create a new `Data` object from user-provided text.
|
||||
|
||||
It accepts the following parameters:
|
||||
|
||||
| Name | Display Name | Info |
|
||||
|------|--------------|------|
|
||||
| input_value | Input | Objects to which Metadata should be added. |
|
||||
| text_in | User Text | Text input; the value is contained in the 'text' attribute of the [Data](/data-types#data) object. Empty text entries are ignored. |
|
||||
| metadata | Metadata | Metadata to add to each object. |
|
||||
| remove_fields | Fields to Remove | Metadata fields to remove. |
|
||||
|
||||
**Outputs**
|
||||
|
||||
| Name | Display Name | Info |
|
||||
|------|--------------|------|
|
||||
| data | Data | List of Input objects, each with added metadata. |
|
||||
| input_value | Input | Input parameter. Objects to which Metadata should be added. |
|
||||
| text_in | User Text | Input parameter. Text input; the value is contained in the 'text' attribute of the `Data` object. Empty text entries are ignored. |
|
||||
| metadata | Metadata | Input parameter. Metadata to add to each object. |
|
||||
| remove_fields | Fields to Remove | Input parameter. Metadata fields to remove. |
|
||||
| data | Data | Output parameter. List of Input objects, each with added metadata. |
|
||||
|
||||
</details>
|
||||
|
||||
### Combine data
|
||||
|
||||
:::important
|
||||
This component is in **Legacy**, which means it is available for use but no longer in active development.
|
||||
Prior to Langflow version 1.1.3, this component was named **Merge Data**.
|
||||
:::
|
||||
|
||||
This component combines multiple data sources into a single unified [Data](/data-types#data) object.
|
||||
|
||||
The component iterates through the input list of data objects, merging them into a single data object. If the input list is empty, it returns an empty data object. If there's only one input data object, it returns that object unchanged. The merging process uses the addition operator to combine data objects.
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
<summary>Combine Data/Merge Data</summary>
|
||||
|
||||
**Inputs**
|
||||
Replace this legacy component with the [**Data Operations** component](#data-operations) or the [**Loop** component](/components-logic#loop).
|
||||
|
||||
| Name | Display Name | Info |
|
||||
|------|--------------|------|
|
||||
| data | Data | A list of data objects to be merged. |
|
||||
This component combines multiple data sources into a single unified `Data` object.
|
||||
|
||||
**Outputs**
|
||||
The component iterates through a list of `Data` objects, merging them into a single `Data` object (`merged_data`).
|
||||
If the input list is empty, it returns an empty data object.
|
||||
If there's only one input data object, it returns that object unchanged.
|
||||
|
||||
| Name | Display Name | Info |
|
||||
|------|--------------|------|
|
||||
| merged_data | Merged Data | A single [Data](/data-types#data) object containing the combined information from all input data objects. |
|
||||
The merging process uses the addition operator to combine data objects.
|
||||
|
||||
</details>
|
||||
|
||||
|
||||
### Combine text
|
||||
|
||||
:::important
|
||||
This component is in **Legacy**, which means it is available for use but no longer in active development.
|
||||
:::
|
||||
|
||||
This component concatenates two text sources into a single text chunk using a specified delimiter.
|
||||
|
||||
1. To use this component in a flow, connect two components that output [Messages](/data-types#message) to the **Combine Text** component's **First Text** and **Second Text** inputs.
|
||||
This example uses two **Text Input** components.
|
||||
|
||||

|
||||
|
||||
2. In the **Combine Text** component, in the **Text** fields of both **Text Input** components, enter some text to combine.
|
||||
3. In the **Combine Text** component, enter an optional **Delimiter** value.
|
||||
The delimiter character separates the combined texts.
|
||||
This example uses `\n\n **end first text** \n\n **start second text** \n\n` to label the texts and create newlines between them.
|
||||
4. Connect a **Chat Output** component to view the text combination.
|
||||
5. Click **Playground**, and then click **Run Flow**.
|
||||
The combined text appears in the **Playground**.
|
||||
```text
|
||||
This is the first text. Let's combine text!
|
||||
end first text
|
||||
start second text
|
||||
Here's the second part. We'll see how combining text works.
|
||||
```
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
<summary>Combine Text</summary>
|
||||
|
||||
**Inputs**
|
||||
Replace this legacy component with the [**Data Operations** component](#data-operations).
|
||||
|
||||
| Name | Display Name | Info |
|
||||
|------|--------------|------|
|
||||
| first_text | First Text | The first text input to concatenate. |
|
||||
| second_text | Second Text | The second text input to concatenate. |
|
||||
| delimiter | Delimiter | A string used to separate the two text inputs. The default is a space. |
|
||||
|
||||
**Outputs**
|
||||
|
||||
| Name | Display Name | Info |
|
||||
|------|--------------|------|
|
||||
| message | Message | A Message object containing the combined text. |
|
||||
This component concatenates two text inputs into a single text chunk using a specified delimiter, outputting a `Message` object with the combined text.
|
||||
|
||||
</details>
|
||||
|
||||
### Create data
|
||||
|
||||
:::important
|
||||
This component is in **Legacy**, which means it is available for use but no longer in active development.
|
||||
:::
|
||||
|
||||
This component dynamically creates a [Data](/data-types#data) object with a specified number of fields.
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
<summary>Create Data</summary>
|
||||
|
||||
**Inputs**
|
||||
| Name | Display Name | Info |
|
||||
|------|--------------|------|
|
||||
| number_of_fields | Number of Fields | The number of fields to be added to the record. |
|
||||
| text_key | Text Key | Key that identifies the field to be used as the text content. |
|
||||
| text_key_validator | Text Key Validator | If enabled, checks if the given `Text Key` is present in the given `Data`. |
|
||||
Replace this legacy component with the [**Data Operations** component](#data-operations).
|
||||
|
||||
**Outputs**
|
||||
This component dynamically creates a `Data` object with a specified number of fields and a text key.
|
||||
|
||||
It accepts the following parameters:
|
||||
|
||||
| Name | Display Name | Info |
|
||||
|------|--------------|------|
|
||||
| data | Data | A [Data](/data-types#data) object created with the specified fields and text key. |
|
||||
| number_of_fields | Number of Fields | Input parameter. The number of fields to be added to the record. |
|
||||
| text_key | Text Key | Input parameter. Key that identifies the field to be used as the text content. |
|
||||
| text_key_validator | Text Key Validator | Input parameter. If enabled, checks if the given `Text Key` is present in the given `Data`. |
|
||||
|
||||
</details>
|
||||
|
||||
### Data to DataFrame
|
||||
|
||||
:::important
|
||||
This component is in **Legacy**, which means it is available for use but no longer in active development.
|
||||
:::
|
||||
This component converts one or multiple [Data](/data-types#data) objects into a [DataFrame](/data-types#dataframe). Each Data object corresponds to one row in the resulting DataFrame. Fields from the `.data` attribute become columns, and the `.text` field (if present) is placed in a 'text' column.
|
||||
|
||||
1. To use this component in a flow, connect a component that outputs [Data](/data-types#data) to the **Data to Dataframe** component's input.
|
||||
This example connects a **Webhook** component to convert `text` and `data` into a DataFrame.
|
||||
2. To view the flow's output, connect a **Chat Output** component to the **Data to Dataframe** component.
|
||||
|
||||

|
||||
|
||||
3. Send a POST request to the **Webhook** containing your JSON data.
|
||||
Replace `YOUR_FLOW_ID` with your flow ID.
|
||||
This example uses the default Langflow server address.
|
||||
```text
|
||||
curl -X POST "http://127.0.0.1:7860/api/v1/webhook/YOUR_FLOW_ID" \
|
||||
-H 'Content-Type: application/json' \
|
||||
-d '{
|
||||
"text": "Alex Cruz - Employee Profile",
|
||||
"data": {
|
||||
"Name": "Alex Cruz",
|
||||
"Role": "Developer",
|
||||
"Department": "Engineering"
|
||||
}
|
||||
}'
|
||||
```
|
||||
|
||||
4. In the **Playground**, view the output of your flow.
|
||||
The **Data to DataFrame** component converts the webhook request into a `DataFrame`, with `text` and `data` fields as columns.
|
||||
```text
|
||||
| text | data |
|
||||
|:-----------------------------|:------------------------------------------------------------------------|
|
||||
| Alex Cruz - Employee Profile | {'Name': 'Alex Cruz', 'Role': 'Developer', 'Department': 'Engineering'} |
|
||||
```
|
||||
|
||||
5. Send another employee data object.
|
||||
```text
|
||||
curl -X POST "http://127.0.0.1:7860/api/v1/webhook/YOUR_FLOW_ID" \
|
||||
-H 'Content-Type: application/json' \
|
||||
-d '{
|
||||
"text": "Kalani Smith - Employee Profile",
|
||||
"data": {
|
||||
"Name": "Kalani Smith",
|
||||
"Role": "Designer",
|
||||
"Department": "Design"
|
||||
}
|
||||
}'
|
||||
```
|
||||
|
||||
6. In the **Playground**, this request is also converted to `DataFrame`.
|
||||
```text
|
||||
| text | data |
|
||||
|:--------------------------------|:---------------------------------------------------------------------|
|
||||
| Kalani Smith - Employee Profile | {'Name': 'Kalani Smith', 'Role': 'Designer', 'Department': 'Design'} |
|
||||
```
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
<summary>Extract Key</summary>
|
||||
|
||||
**Inputs**
|
||||
Replace this legacy component with the [**Data Operations** component](#data-operations).
|
||||
|
||||
| Name | Display Name | Info |
|
||||
|------|--------------|------|
|
||||
| data_list | Data or Data List | One or multiple Data objects to transform into a DataFrame. |
|
||||
|
||||
**Outputs**
|
||||
|
||||
| Name | Display Name | Info |
|
||||
|------|--------------|------|
|
||||
| dataframe | DataFrame | A DataFrame built from each Data object's fields plus a text column. |
|
||||
This component extracts a specific key from a `Data` object and returns the value associated with that key.
|
||||
|
||||
</details>
|
||||
|
||||
### Filter data
|
||||
|
||||
:::important
|
||||
This component is in **Legacy**, which means it is available for use but no longer in active development.
|
||||
Instead, use the [Data operations](#data-operations) component.
|
||||
:::
|
||||
|
||||
This component filters a [Data](/data-types#data) object based on a list of keys.
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
<summary>Data to DataFrame/Data to Message</summary>
|
||||
|
||||
**Inputs**
|
||||
Replace these legacy components with newer processing components, such as the [**Data Operations** component](#data-operations) and [**Type Convert** component](#type-convert).
|
||||
|
||||
| Name | Display Name | Info |
|
||||
|------|--------------|------|
|
||||
| data | Data | The Data object to filter. |
|
||||
| filter_criteria | Filter Criteria | A list of keys to filter by. |
|
||||
These components converted one or more `Data` objects into a `DataFrame` or `Message` object.
|
||||
|
||||
**Outputs**
|
||||
|
||||
| Name | Display Name | Info |
|
||||
|------|--------------|------|
|
||||
| filtered_data | Filtered Data | A new Data object containing only the key-value pairs that match the filter criteria. |
|
||||
For the **Data to DataFrame** component, each `Data` object corresponds to one row in the resulting `DataFrame`.
|
||||
Fields from the `.data` attribute become columns, and the `.text` field (if present) is placed in a `text` column.
|
||||
|
||||
</details>
|
||||
|
||||
### Filter values
|
||||
<details>
|
||||
<summary>Filter Data</summary>
|
||||
|
||||
:::important
|
||||
This component is in **Legacy**, which means it is available for use but no longer in active development.
|
||||
Instead, use the [Data operations](#data-operations) component.
|
||||
:::
|
||||
Replace this legacy component with the [**Data Operations** component](#data-operations).
|
||||
|
||||
This component filters a `Data` object based on a list of keys (`filter_criteria`), returning a new `Data` object (`filtered_data`) that contains only the key-value pairs that match the filter criteria.
|
||||
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>Filter Values</summary>
|
||||
|
||||
Replace this legacy component with the [**Data Operations** component](#data-operations).
|
||||
|
||||
The Filter values component filters a list of data items based on a specified key, filter value, and comparison operator.
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
|
||||
**Inputs**
|
||||
| Name | Display Name | Info |
|
||||
|------|--------------|------|
|
||||
| input_data | Input data | The list of data items to filter. |
|
||||
| filter_key | Filter Key | The key to filter on. |
|
||||
| filter_value | Filter Value | The value to filter by. |
|
||||
| operator | Comparison Operator | The operator to apply for comparing the values. |
|
||||
|
||||
**Outputs**
|
||||
It accepts the following parameters:
|
||||
|
||||
| Name | Display Name | Info |
|
||||
|------|--------------|------|
|
||||
| filtered_data | Filtered data | The resulting list of filtered data items. |
|
||||
| input_data | Input data | Input parameter. The list of data items to filter. |
|
||||
| filter_key | Filter Key | Input parameter. The key to filter on. |
|
||||
| filter_value | Filter Value | Input parameter. The value to filter by. |
|
||||
| operator | Comparison Operator | Input parameter. The operator to apply for comparing the values. |
|
||||
| filtered_data | Filtered data | Output parameter. The resulting list of filtered data items. |
|
||||
|
||||
</details>
|
||||
|
||||
### JSON cleaner
|
||||
|
||||
:::important
|
||||
This component is in **Legacy**, which means it is available for use but no longer in active development.
|
||||
:::
|
||||
|
||||
The JSON cleaner component cleans JSON strings to ensure they are fully compliant with the JSON specification.
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
<summary>JSON Cleaner</summary>
|
||||
|
||||
**Inputs**
|
||||
Replace this legacy component with the [**Parser** component](#parser).
|
||||
|
||||
This component cleans JSON strings to ensure they are fully compliant with the JSON specification.
|
||||
|
||||
It accepts the following parameters:
|
||||
|
||||
| Name | Display Name | Info |
|
||||
|------|--------------|------|
|
||||
| json_str | JSON String | The JSON string to be cleaned. This can be a raw, potentially malformed JSON string produced by language models or other sources that may not fully comply with JSON specifications. |
|
||||
| remove_control_chars | Remove Control Characters | If set to True, this option removes control characters (ASCII characters 0-31 and 127) from the JSON string. This can help eliminate invisible characters that might cause parsing issues or make the JSON invalid. |
|
||||
| normalize_unicode | Normalize Unicode | When enabled, this option normalizes Unicode characters in the JSON string to their canonical composition form (NFC). This ensures consistent representation of Unicode characters across different systems and prevents potential issues with character encoding. |
|
||||
| validate_json | Validate JSON | If set to True, this option attempts to parse the JSON string to ensure it is well-formed before applying the final repair operation. It raises a ValueError if the JSON is invalid, allowing for early detection of major structural issues in the JSON. |
|
||||
|
||||
**Outputs**
|
||||
|
||||
| Name | Display Name | Info |
|
||||
|------|--------------|------|
|
||||
| output | Cleaned JSON String | The resulting cleaned, repaired, and validated JSON string that fully complies with the JSON specification. |
|
||||
| json_str | JSON String | Input parameter. The JSON string to be cleaned. This can be a raw, potentially malformed JSON string produced by language models or other sources that may not fully comply with JSON specifications. |
|
||||
| remove_control_chars | Remove Control Characters | Input parameter. If set to True, this option removes control characters (ASCII characters 0-31 and 127) from the JSON string. This can help eliminate invisible characters that might cause parsing issues or make the JSON invalid. |
|
||||
| normalize_unicode | Normalize Unicode | Input parameter. When enabled, this option normalizes Unicode characters in the JSON string to their canonical composition form (NFC). This ensures consistent representation of Unicode characters across different systems and prevents potential issues with character encoding. |
|
||||
| validate_json | Validate JSON | Input parameter. If set to True, this option attempts to parse the JSON string to ensure it is well-formed before applying the final repair operation. It raises a ValueError if the JSON is invalid, allowing for early detection of major structural issues in the JSON. |
|
||||
| output | Cleaned JSON String | Output parameter. The resulting cleaned, repaired, and validated JSON string that fully complies with the JSON specification. |
|
||||
|
||||
</details>
|
||||
|
||||
### Message to data
|
||||
|
||||
This component converts [Message](/data-types#message) objects to [Data](/data-types#data) objects.
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
<summary>Message to Data</summary>
|
||||
|
||||
**Inputs**
|
||||
Replace this legacy component with the [**Type Convert** component](#type-convert).
|
||||
|
||||
| Name | Display Name | Info |
|
||||
|------|--------------|------|
|
||||
| message | Message | The Message object to convert to a Data object. |
|
||||
|
||||
**Outputs**
|
||||
|
||||
| Name | Display Name | Info |
|
||||
|------|--------------|------|
|
||||
| data | Data | The converted Data object. |
|
||||
This component converts `Message` objects to `Data` objects.
|
||||
|
||||
</details>
|
||||
|
||||
### Parse DataFrame
|
||||
|
||||
:::important
|
||||
This component is in **Legacy**, which means it is available for use but no longer in active development.
|
||||
Instead, use the [Parser](#parser) component.
|
||||
:::
|
||||
|
||||
This component converts DataFrames into plain text using templates.
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
<summary>Parse DataFrame</summary>
|
||||
|
||||
**Inputs**
|
||||
Replace this legacy component with the [**DataFrame Operations** component](#dataframe-operations) or [**Parser** component](#parser).
|
||||
|
||||
This component converts `DataFrame` objects into plain text using templates.
|
||||
|
||||
It accepts the following parameters:
|
||||
|
||||
| Name | Display Name | Info |
|
||||
|------|--------------|------|
|
||||
| df | DataFrame | The DataFrame to convert to text rows. |
|
||||
| template | Template | Template for formatting (use `{column_name}` placeholders). |
|
||||
| sep | Separator | String to join rows in output. |
|
||||
|
||||
**Outputs**
|
||||
|
||||
| Name | Display Name | Info |
|
||||
|------|--------------|------|
|
||||
| text | Text | All rows combined into single text. |
|
||||
| df | DataFrame | Input parameter. The DataFrame to convert to text rows. |
|
||||
| template | Template | Input parameter. Template for formatting (use `{column_name}` placeholders). |
|
||||
| sep | Separator | Input parameter. String to join rows in output. |
|
||||
| text | Text | Output parameter. All rows combined into single text. |
|
||||
|
||||
</details>
|
||||
|
||||
### Parse JSON
|
||||
|
||||
:::important
|
||||
This component is in **Legacy**, which means it is available for use but no longer in active development.
|
||||
:::
|
||||
|
||||
This component converts and extracts JSON fields using JQ queries.
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
<summary>Parse JSON</summary>
|
||||
|
||||
**Inputs**
|
||||
Replace this legacy component with the [**Parser** component](#parser).
|
||||
|
||||
| Name | Display Name | Info |
|
||||
|------|--------------|------|
|
||||
| input_value | Input | Data object to filter ([Message](/data-types#message) or [Data](/data-types#data)). |
|
||||
| query | JQ Query | JQ Query to filter the data |
|
||||
|
||||
**Outputs**
|
||||
|
||||
| Name | Display Name | Info |
|
||||
|------|--------------|------|
|
||||
| filtered_data | Filtered Data | Filtered data as list of [Data](/data-types#data) objects. |
|
||||
This component converts and extracts JSON fields in `Message` and `Data` objects using JQ queries, then returns `filtered_data`, which is a list of `Data` objects.
|
||||
|
||||
</details>
|
||||
|
||||
### Regex extractor
|
||||
<details>
|
||||
<summary>Python REPL</summary>
|
||||
|
||||
:::important
|
||||
This component is in **Legacy**, which means it is available for use but no longer in active development.
|
||||
:::
|
||||
Replace this legacy component with the [**Python Interpreter** component](#python-interpreter) or another processing or logic component.
|
||||
|
||||
This component creates a Python REPL (Read-Eval-Print Loop) tool for executing Python code.
|
||||
|
||||
It accepts the following parameters:
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| name | String | Input parameter. The name of the tool. Default: `python_repl`. |
|
||||
| description | String | Input parameter. A description of the tool's functionality. |
|
||||
| global_imports | List[String] | Input parameter. A list of modules to import globally. Default: `math`. |
|
||||
| tool | Tool | Output parameter. A Python REPL tool for use in LangChain. |
|
||||
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>Python Code Structured</summary>
|
||||
|
||||
Replace this legacy component with the [**Python Interpreter** component](#python-interpreter) or another processing or logic component.
|
||||
|
||||
This component creates a structured tool from Python code using a dataclass.
|
||||
|
||||
The component dynamically updates its configuration based on the provided Python code, allowing for custom function arguments and descriptions.
|
||||
|
||||
It accepts the following parameters:
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| tool_code | String | Input parameter. The Python code for the tool's dataclass. |
|
||||
| tool_name | String | Input parameter. The name of the tool. |
|
||||
| tool_description | String | Input parameter. The description of the tool. |
|
||||
| return_direct | Boolean | Input parameter. Whether to return the function output directly. |
|
||||
| tool_function | String | Input parameter. The selected function for the tool. |
|
||||
| global_variables | Dict | Input parameter. Global variables or data for the tool. |
|
||||
| result_tool | Tool | Output parameter. A structured tool created from the Python code. |
|
||||
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>Regex Extractor</summary>
|
||||
|
||||
Replace this legacy component with the [**Parser** component](#parser).
|
||||
|
||||
This component extracts patterns in text using regular expressions. It can be used to find and extract specific patterns or information in text.
|
||||
|
||||
To use this component in a flow:
|
||||
|
||||
1. Connect the **Regex Extractor** to a **URL** component and a **Chat Output** component.
|
||||
|
||||
2. In the **Regex Extractor** tool, enter a pattern to extract text from the **URL** component's raw output.
|
||||
This example extracts the first paragraph from the "In the News" section of `https://en.wikipedia.org/wiki/Main_Page`:
|
||||
```
|
||||
In the news\s*\n(.*?)(?=\n\n)
|
||||
```
|
||||
|
||||
Result:
|
||||
```
|
||||
Peruvian writer and Nobel Prize in Literature laureate Mario Vargas Llosa (pictured) dies at the age of 89.
|
||||
```
|
||||
|
||||
### Select data
|
||||
|
||||
:::important
|
||||
This component is in **Legacy**, which means it is available for use but no longer in active development.
|
||||
:::
|
||||
|
||||
This component selects a single [Data](/data-types#data) item from a list.
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
<summary>Select Data</summary>
|
||||
|
||||
**Inputs**
|
||||
Replace this legacy component with the [**Data Operations** component](#data-operations).
|
||||
|
||||
This component selects a single `Data` object from a list.
|
||||
|
||||
It accepts the following parameters:
|
||||
|
||||
| Name | Display Name | Info |
|
||||
|------|--------------|------|
|
||||
| data_list | Data List | List of data to select from |
|
||||
| data_index | Data Index | Index of the data to select |
|
||||
|
||||
**Outputs**
|
||||
|
||||
| Name | Display Name | Info |
|
||||
|------|--------------|------|
|
||||
| selected_data | Selected Data | The selected [Data](/data-types#data) object. |
|
||||
| data_list | Data List | Input parameter. List of data to select from |
|
||||
| data_index | Data Index | Input parameter. Index of the data to select |
|
||||
| selected_data | Selected Data | Output parameter. The selected `Data` object. |
|
||||
|
||||
</details>
|
||||
|
||||
### Update data
|
||||
<details>
|
||||
<summary>Update Data</summary>
|
||||
|
||||
:::important
|
||||
This component is in **Legacy**, which means it is available for use but no longer in active development.
|
||||
:::
|
||||
Replace this legacy component with the [**Data Operations** component](#data-operations).
|
||||
|
||||
This component dynamically updates or appends data with specified fields.
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
|
||||
**Inputs**
|
||||
It accepts the following parameters:
|
||||
|
||||
| Name | Display Name | Info |
|
||||
|------|--------------|------|
|
||||
| old_data | Data | The records to update. |
|
||||
| number_of_fields | Number of Fields | The number of fields to add. The maximum is 15. |
|
||||
| text_key | Text Key | The key for text content. |
|
||||
| text_key_validator | Text Key Validator | Validates the text key presence. |
|
||||
|
||||
**Outputs**
|
||||
|
||||
| Name | Display Name | Info |
|
||||
|------|--------------|------|
|
||||
| data | Data | The updated Data objects. |
|
||||
|
||||
</details>
|
||||
| old_data | Data | Input parameter. The records to update. |
|
||||
| number_of_fields | Number of Fields | Input parameter. The number of fields to add. The maximum is 15. |
|
||||
| text_key | Text Key | Input parameter. The key for text content. |
|
||||
| text_key_validator | Text Key Validator | Input parameter. Validates the text key presence. |
|
||||
| data | Data | Output parameter. The updated Data objects. |
|
||||
|
||||
</details>
|
||||
|
|
@ -1,76 +1,64 @@
|
|||
---
|
||||
title: Prompts
|
||||
title: Prompt Template
|
||||
slug: /components-prompts
|
||||
---
|
||||
|
||||
# Prompt components in Langflow
|
||||
Use the **Prompt Template** core component to create a _prompt_ that supplies instructions and context to an LLM or agent, separate from other input like chat messages and file uploads.
|
||||
|
||||
A prompt is a structured input to a language model that instructs the model how to handle user inputs and variables.
|
||||
Prompts are structured input that use natural language, fixed values, and dynamic variables to provide baseline context for the LLM.
|
||||
For example:
|
||||
|
||||
Prompt components create prompt templates with custom fields and dynamic variables for providing your model structured, repeatable prompts.
|
||||
* Define a consistent structure for user queries, making it easier for the LLM to understand and respond appropriately.
|
||||
* Define a specific output format for the LLM, such as JSON or structured text.
|
||||
* Define a role for the LLM, such as `You are a helpful assistant` or `You are an expert in microbiology`.
|
||||
* Allow the LLM to reference chat memory.
|
||||
|
||||
Prompts are a combination of natural language and variables created with curly braces.
|
||||
The **Prompt Template** component can also output variable instructions to other components later in the flow.
|
||||
|
||||
## Use a prompt component in a flow
|
||||
## Prompt Template parameters
|
||||
|
||||
An example of modifying a prompt can be found in the [Basic prompting starter flow](/basic-prompting).
|
||||
| Name | Display Name | Description |
|
||||
|----------|----------------|-------------------------------------------------------------------|
|
||||
| template | Template | Input parameter. Create a prompt template with dynamic variables (`{VARIABLE_NAME}`). |
|
||||
| prompt | Prompt Message | Output parameter. The built prompt message returned by the `build_prompt` method. |
|
||||
|
||||
The default prompt in the **Prompt** component is `Answer the user as if you were a GenAI expert, enthusiastic about helping them get started building something fresh.`
|
||||
## Define variables in prompts
|
||||
|
||||
This prompt creates a "personality" for your LLM's chat interactions, but it doesn't include variables that you may find useful when templating prompts.
|
||||
Variables in a **Prompt Template** component dynamically add fields to the **Prompt Template** component so that your flow can receive definitions for those values from other components, Langflow global variables, or fixed input.
|
||||
|
||||
To modify the prompt template, in the **Prompt** component, click the **Template** field. For example, the `{context}` variable gives the LLM model access to embedded vector data to return better answers.
|
||||
For example, with the [**Message History**](/components-helpers#message-history) component, you can use a `{memory}` variable to pass chat history to the prompt.
|
||||
|
||||
```text
|
||||
Given the context
|
||||
{context}
|
||||
Answer the question
|
||||
{user_question}
|
||||
```
|
||||
The following steps demonstrate how to add variables to a **Prompt Template** component:
|
||||
|
||||
When variables are added to a prompt template, new fields are automatically created in the component. These fields can be connected to receive text input from other components to automate prompting, or to output instructions to other components.
|
||||
1. Create a flow based on the [**Basic prompting** template](/basic-prompting).
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
This template already has a **Prompt Template** component, but the template only contains natural language instructions: `Answer the user as if you were a GenAI expert, enthusiastic about helping them get started building something fresh.`
|
||||
|
||||
**Inputs**
|
||||
This prompt defines a role for the LLM's chat interactions, but it doesn't include variables that help you create prompts that adapt dynamically to changing contexts, such as different users and environments.
|
||||
|
||||
| Name | Display Name | Info |
|
||||
|----------|--------------|-------------------------------------------------------------------|
|
||||
| template | Template | Create a prompt template with dynamic variables. |
|
||||
2. Click the **Prompt Template** component, and then add some variables to the **Template** field.
|
||||
|
||||
**Outputs**
|
||||
Variables are declared by wrapping the variable name in curly braces, like `{variable_name}`.
|
||||
For example, the following template creates `context` and `user_question` variables:
|
||||
|
||||
| Name | Display Name | Info |
|
||||
|--------|----------------|--------------------------------------------------------|
|
||||
| prompt | Prompt Message | The built prompt message returned by the `build_prompt` method. |
|
||||
```text
|
||||
Given the context
|
||||
{context}
|
||||
Answer the question
|
||||
{user_question}
|
||||
```
|
||||
|
||||
</details>
|
||||
4. Click **Check & Save** to save the template.
|
||||
|
||||
## Langchain Hub Prompt Template
|
||||
After adding the variables to the template, new fields are added to the **Prompt Template** component for each variable.
|
||||
|
||||
:::important
|
||||
This component is available in the **Components** menu under **Bundles**.
|
||||
:::
|
||||
5. Provide input for the variable fields:
|
||||
|
||||
This component fetches prompts from the [Langchain Hub](https://docs.smith.langchain.com/old/category/prompt-hub).
|
||||
* Connect the fields to other components to pass the output from those components to the variables.
|
||||
* Use Langflow global variables.
|
||||
* Enter fixed values directly into the fields.
|
||||
|
||||
When a prompt is loaded, the component generates input fields for custom variables. For example, the default prompt "efriis/my-first-prompt" generates fields for `profession` and `question`.
|
||||
## See also
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
|
||||
**Inputs**
|
||||
|
||||
| Name | Display Name | Info |
|
||||
|--------------------|---------------------------|------------------------------------------|
|
||||
| langchain_api_key | Your LangChain API Key | The LangChain API Key to use. |
|
||||
| langchain_hub_prompt| LangChain Hub Prompt | The LangChain Hub prompt to use. |
|
||||
|
||||
**Outputs**
|
||||
|
||||
| Name | Display Name | Info |
|
||||
|--------|--------------|-------------------------------------------------------------------|
|
||||
| prompt | Build Prompt | The built prompt message returned by the `build_prompt` method. |
|
||||
|
||||
</details>
|
||||
* [LangChain Prompt Hub](/bundles-langchain#prompt-hub)
|
||||
* [Processing components](/components-processing)
|
||||
|
|
@ -3,603 +3,71 @@ title: Tools
|
|||
slug: /components-tools
|
||||
---
|
||||
|
||||
import Icon from "@site/src/components/icon";
|
||||
In Langflow version 1.5, the **Tools** category was deprecated.
|
||||
|
||||
The **Tools** category in Langflow is removed as of Langflow 1.5.
|
||||
|
||||
Most components from the **Tools** category have been moved to other categories or bundles.
|
||||
|
||||
* The [MCP Tools](/components-agents#mcp-connection) component is available in **Agent components**.
|
||||
* The [calculator](/components-helpers#calculator) component is available in **Helpers**.
|
||||
* The [Astra DB JSON](/components-tools#astra-db-tool) and [Astra DB CQL](#astra-db-cql-tool) tools are available in the **DataStax** bundle.
|
||||
* The [Python Interpreter](/components-processing#python-interpreter) component is available in **Processing**.
|
||||
|
||||
The remaining tools listed below are moved to a **Bundle** or in **Legacy**.
|
||||
Legacy components are available for use but are no longer supported.
|
||||
|
||||
## arXiv
|
||||
All components that were in this category were replaced by other components or moved to other categories in the **Components** menu.
|
||||
|
||||
:::important
|
||||
As of Langflow 1.5, this component is available in the **Search** bundle.
|
||||
Many components that were in the **Tools** category are legacy components.
|
||||
You can use these components in your flows, but they are no longer maintained and may be removed in a future release.
|
||||
|
||||
It is recommended that you replace all legacy components with the replacement components described on this page.
|
||||
:::
|
||||
|
||||
This component searches and retrieves papers from [arXiv.org](https://arXiv.org).
|
||||
## Calculator Tool component
|
||||
|
||||
The **Calculator Tool** component is a legacy component.
|
||||
Replace this component with the [**Calculator** component](/components-helpers#calculator) in the **Helpers** category.
|
||||
|
||||
## MCP Connection component
|
||||
|
||||
This component was moved to the **Agents** category and renamed to the [**MCP Tools** component](/components-agents#mcp-connection)
|
||||
|
||||
## Python tools
|
||||
|
||||
The **Python REPL** and **Python Code Structured** components are legacy components.
|
||||
Replace these components with the [**Python Interpreter** component](/components-processing#python-interpreter) in the **Processing** category.
|
||||
|
||||
## Search and API request tools
|
||||
|
||||
Many tool components performed basic API calls to public archives or search APIs.
|
||||
All such components in the **Tools** category are legacy components.
|
||||
|
||||
You have two options for replacing these components:
|
||||
|
||||
* Use the generic [data components](/components-data) for search and API calls, such as the [**Web Search**](/components-data#web-search) and [**News Search**](/components-data#news-search) components.
|
||||
|
||||
* Use the provider-specific search and API components in the **Bundles** category:
|
||||
* [**arXiv** bundle](/bundles-arxiv)
|
||||
* [**Bing** bundle](/bundles-bing)
|
||||
* [**DataStax** bundle](/bundles-datastax)
|
||||
* [**DuckDuckGo** bundle](/bundles-duckduckgo)
|
||||
* [**Exa** bundle](/bundles-exa)
|
||||
* [**Glean** bundle](/bundles-glean)
|
||||
* [**Google** bundle](/bundles-google)
|
||||
* [**Icosa Computing** bundle](/bundles-icosacomputing)
|
||||
* [**LangChain** bundle](/bundles-langchain)
|
||||
* [**SearchApi** bundle](/bundles-searchapi)
|
||||
* **SerpApi** bundle
|
||||
* **Tavily** bundle
|
||||
* [**Wikipedia** bundle](/bundles-wikipedia)
|
||||
* **Yahoo! Search** bundle
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
<summary>SearXNG Search Tool</summary>
|
||||
|
||||
**Inputs**
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| search_query | String | The search query for arXiv papers. For example, `quantum computing`. |
|
||||
| search_type | String | The field to search in. |
|
||||
| max_results | Integer | The maximum number of results to return. |
|
||||
|
||||
**Outputs**
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| papers | List[Data] | A list of retrieved arXiv papers. |
|
||||
|
||||
</details>
|
||||
|
||||
## Astra DB tool
|
||||
|
||||
:::important
|
||||
As of Langflow 1.5, this component is available in the **DataStax** bundle.
|
||||
:::
|
||||
|
||||
This component allows agents to query data from Astra DB collections.
|
||||
|
||||
To use this tool in a flow, connect it to an **Agent** component.
|
||||
The flow looks like this:
|
||||
|
||||

|
||||
|
||||
The **Tool Name** and **Tool Description** fields are required for the Agent to decide when to use the tool.
|
||||
**Tool Name** cannot contain spaces.
|
||||
|
||||
The values for **Collection Name**, **Astra DB Application Token**, and **Astra DB API Endpoint** are found in your Astra DB deployment. For more information, see the [DataStax documentation](https://docs.datastax.com/en/astra-db-serverless/databases/create-database.html).
|
||||
|
||||
In this example, an **OpenAI** embeddings component is connected to use the Astra DB tool component's **Semantic Search** capability.
|
||||
To use **Semantic Search**, you must have an embedding model or Astra DB Vectorize enabled.
|
||||
If you try to run the flow without an embedding model, you will get an error.
|
||||
|
||||
Open the **Playground** and ask a question about your data.
|
||||
The Agent uses the **Astra DB Tool** to return information about your collection.
|
||||
|
||||
### Define Astra DB tool parameters
|
||||
|
||||
The **Tool Parameters** configuration pane allows you to define parameters for [filter conditions](https://docs.datastax.com/en/astra-db-serverless/api-reference/document-methods/find-many.html#parameters) for the component's **Find** command.
|
||||
|
||||
These filters become available as parameters that the LLM can use when calling the tool, with a better understanding of each parameter provided by the **Description** field.
|
||||
|
||||
1. To define a parameter for your query, in the **Tool Parameters** pane, click <Icon name="Plus" aria-hidden="true"/> **Add a new row**.
|
||||
2. Complete the fields based on your data. For example, with this filter, the LLM can filter by unique `customer_id` values.
|
||||
|
||||
* Name: `customer_id`
|
||||
* Attribute Name: Leave empty if the attribute matches the field name in the database.
|
||||
* Description: `"The unique identifier of the customer to filter by"`.
|
||||
* Is Metadata: `False` unless the value stored in the metadata field.
|
||||
* Is Mandatory: `True` to require this filter.
|
||||
* Is Timestamp: `False` since the value is an ID, not a timestamp.
|
||||
* Operator: `$eq` to look for an exact match.
|
||||
|
||||
If you want to apply filters regardless of the LLM's input, use the **Static Filters** option, which is available in the component's **Controls** pane.
|
||||
|
||||
| Parameter | Description |
|
||||
|-----------|-------------|
|
||||
| Name | The name of the parameter that is exposed to the LLM. It can be the same as the underlying field name or a more descriptive label. The LLM uses this name, along with the description, to infer what value to provide during execution. |
|
||||
| Attribute Name | When the parameter name shown to the LLM differs from the actual field or property in the database, use this setting to map the user-facing name to the correct attribute. For example, to apply a range filter to the timestamp field, define two separate parameters, such as `start_date` and `end_date`, that both reference the same timestamp attribute. |
|
||||
| Description | Provides instructions to the LLM on how the parameter should be used. Clear and specific guidance helps the LLM provide valid input. For example, if a field such as `specialty` is stored in lowercase, the description should indicate that the input must be lowercase. |
|
||||
| Is Metadata | When loading data using LangChain or Langflow, additional attributes may be stored under a metadata object. If the target attribute is stored this way, enable this option. It adjusts the query by generating a filter in the format: `{"metadata.<attribute_name>": "<value>"}` |
|
||||
| Is Timestamp | For date or time-based filters, enable this option to automatically convert values to the timestamp format that the Astrapy client expects. This ensures compatibility with the underlying API without requiring manual formatting. |
|
||||
| Operator | Defines the filtering logic applied to the attribute. You can use any valid [Data API filter operator](https://docs.datastax.com/en/astra-db-serverless/api-reference/filter-operator-collections.html). For example, to filter a time range on the timestamp attribute, use two parameters: one with the `$gt` operator for "greater than", and another with the `$lt` operator for "less than". |
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
|
||||
**Inputs**
|
||||
|
||||
| Name | Type | Description |
|
||||
|-------------------|--------|----------------------------------------------------------------------------------------------------------------------------------|
|
||||
| Tool Name | String | The name used to reference the tool in the agent's prompt. |
|
||||
| Tool Description | String | A brief description of the tool. This helps the model decide when to use it. |
|
||||
| Collection Name | String | The name of the Astra DB collection to query. |
|
||||
| Token | SecretString | The authentication token for accessing Astra DB. |
|
||||
| API Endpoint | String | The Astra DB API endpoint. |
|
||||
| Projection Fields | String | The attributes to return, separated by commas. The default is `*`. |
|
||||
| Tool Parameters | Dict | Parameters the model needs to fill to execute the tool. For required parameters, use an exclamation mark, for example `!customer_id`. |
|
||||
| Static Filters | Dict | Attribute-value pairs used to filter query results. |
|
||||
| Limit | String | The number of documents to return. |
|
||||
|
||||
|
||||
**Outputs**
|
||||
|
||||
The **Data** output is used when directly querying Astra DB, while the **Tool** output is used when integrating with agents.
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| Data | List[Data] | A list of [Data](/data-types#data) objects containing the query results from Astra DB. Each `Data` object contains the document fields specified by the projection attributes. Limited by the `number_of_results` parameter. |
|
||||
| Tool | StructuredTool | A LangChain `StructuredTool` object that can be used in agent workflows. Contains the tool name, description, argument schema based on tool parameters, and the query function. |
|
||||
|
||||
</details>
|
||||
|
||||
## Astra DB CQL Tool
|
||||
|
||||
:::important
|
||||
As of Langflow 1.5, this component is available in the **DataStax** bundle.
|
||||
:::
|
||||
|
||||
The `Astra DB CQL Tool` allows agents to query data from CQL tables in Astra DB.
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
|
||||
**Inputs**
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| Tool Name | String | The name used to reference the tool in the agent's prompt. |
|
||||
| Tool Description | String | A brief description of the tool to guide the model in using it. |
|
||||
| Keyspace | String | The name of the keyspace. |
|
||||
| Table Name | String | The name of the Astra DB CQL table to query. |
|
||||
| Token | SecretString | The authentication token for Astra DB. |
|
||||
| API Endpoint | String | The Astra DB API endpoint. |
|
||||
| Projection Fields | String | The attributes to return, separated by commas. Default: "*". |
|
||||
| Partition Keys | Dict | Required parameters that the model must fill to query the tool. |
|
||||
| Clustering Keys | Dict | Optional parameters the model can fill to refine the query. Required parameters should be marked with an exclamation mark, for example, `!customer_id`. |
|
||||
| Static Filters | Dict | Attribute-value pairs used to filter query results. |
|
||||
| Limit | String | The number of records to return. |
|
||||
|
||||
**Outputs**
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| Data | List[Data] | A list of [Data](/data-types#data) objects containing the query results from the Astra DB CQL table. Each Data object contains the document fields specified by the projection fields. Limited by the `number_of_results` parameter. |
|
||||
| Tool | StructuredTool | A LangChain StructuredTool object that can be used in agent workflows. Contains the tool name, description, argument schema based on partition and clustering keys, and the query function. |
|
||||
|
||||
</details>
|
||||
|
||||
## Bing Search API
|
||||
|
||||
:::important
|
||||
As of Langflow 1.5, this component is available in the **Search** bundle.
|
||||
:::
|
||||
|
||||
This component allows you to call the Bing Search API.
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
|
||||
**Inputs**
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| bing_subscription_key | SecretString | A Bing API subscription key. |
|
||||
| input_value | String | The search query input. |
|
||||
| bing_search_url | String | A custom Bing Search URL. |
|
||||
| k | Integer | The number of search results to return. |
|
||||
|
||||
**Outputs**
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| results | List[Data] | A list of search results. |
|
||||
| tool | Tool | A Bing Search tool for use in LangChain. |
|
||||
|
||||
</details>
|
||||
|
||||
## Combinatorial Reasoner
|
||||
|
||||
:::important
|
||||
This component is available in the **Components** menu under **Bundles**.
|
||||
:::
|
||||
|
||||
This component runs Icosa's Combinatorial Reasoning (CR) pipeline on an input to create an optimized prompt with embedded reasons. For more information, see [Icosa computing](https://www.icosacomputing.com/).
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
|
||||
**Inputs**
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| prompt | String | The input to run CR on. |
|
||||
| openai_api_key | SecretString | An OpenAI API key for authentication. |
|
||||
| username | String | A username for Icosa API authentication. |
|
||||
| password | SecretString | A password for Icosa API authentication. |
|
||||
| model_name | String | The OpenAI LLM to use for reason generation. |
|
||||
|
||||
**Outputs**
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| optimized_prompt | Message | A message object containing the optimized prompt. |
|
||||
| reasons | List[String] | A list of the selected reasons that are embedded in the optimized prompt. |
|
||||
|
||||
</details>
|
||||
|
||||
## DuckDuckGo search
|
||||
|
||||
:::important
|
||||
As of Langflow 1.5, this component is available in the **Search** bundle.
|
||||
:::
|
||||
|
||||
This component performs web searches using the [DuckDuckGo](https://www.duckduckgo.com) search engine with result-limiting capabilities.
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
|
||||
**Inputs**
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| input_value | String | The search query to execute with DuckDuckGo. |
|
||||
| max_results | Integer | The maximum number of search results to return. Default: 5. |
|
||||
| max_snippet_length | Integer | The maximum length of each result snippet. Default: 100. |
|
||||
|
||||
**Outputs**
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| data | List[Data] | A list of search results as Data objects containing snippets and full content. |
|
||||
| text | String | The search results formatted as a single text string. |
|
||||
|
||||
</details>
|
||||
|
||||
## Exa Search
|
||||
|
||||
:::important
|
||||
As of Langflow 1.5, this component is available in the **Search** bundle.
|
||||
:::
|
||||
|
||||
This component provides an [Exa Search](https://exa.ai/) toolkit for search and content retrieval.
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
|
||||
**Inputs**
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| metaphor_api_key | SecretString | An API key for Exa Search. |
|
||||
| use_autoprompt | Boolean | Whether to use the autoprompt feature. Default: true. |
|
||||
| search_num_results | Integer | The number of results to return for search. Default: 5. |
|
||||
| similar_num_results | Integer | The number of similar results to return. Default: 5. |
|
||||
|
||||
**Outputs**
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| tools | List[Tool] | A list of search tools provided by the toolkit. |
|
||||
|
||||
</details>
|
||||
|
||||
## Glean Search API
|
||||
|
||||
:::important
|
||||
As of Langflow 1.5, this component is available in the **Search** bundle.
|
||||
:::
|
||||
|
||||
This component allows you to call the Glean Search API.
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
|
||||
**Inputs**
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| glean_api_url | String | The URL of the Glean API. |
|
||||
| glean_access_token | SecretString | An access token for Glean API authentication. |
|
||||
| query | String | The search query input. |
|
||||
| page_size | Integer | The number of results per page. Default: 10. |
|
||||
| request_options | Dict | Additional options for the API request. |
|
||||
|
||||
**Outputs**
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| results | List[Data] | A list of search results. |
|
||||
| tool | Tool | A Glean Search tool for use in LangChain. |
|
||||
|
||||
</details>
|
||||
|
||||
### Google Search API
|
||||
|
||||
:::important
|
||||
As of Langflow 1.5, this component is available in the **Search** bundle.
|
||||
:::
|
||||
|
||||
This component allows you to call the Google Search API.
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
|
||||
**Inputs**
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| google_api_key | SecretString | A Google API key for authentication. |
|
||||
| google_cse_id | SecretString | A Google Custom Search Engine ID. |
|
||||
| input_value | String | The search query input. |
|
||||
| k | Integer | The number of search results to return. |
|
||||
|
||||
**Outputs**
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| results | List[Data] | A list of search results. |
|
||||
| tool | Tool | A Google Search tool for use in LangChain. |
|
||||
|
||||
</details>
|
||||
|
||||
## Google Serper API
|
||||
|
||||
:::important
|
||||
As of Langflow 1.5, this component is available in the **Search** bundle.
|
||||
:::
|
||||
|
||||
This component allows you to call the Serper.dev Google Search API.
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
|
||||
**Inputs**
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| serper_api_key | SecretString | An API key for Serper.dev authentication. |
|
||||
| input_value | String | The search query input. |
|
||||
| k | Integer | The number of search results to return. |
|
||||
|
||||
**Outputs**
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| results | List[Data] | A list of search results. |
|
||||
| tool | Tool | A Google Serper search tool for use in LangChain. |
|
||||
|
||||
</details>
|
||||
|
||||
## MCP connection
|
||||
|
||||
:::important
|
||||
As of Langflow 1.5, this component is called the **MCP Tools** component.
|
||||
:::
|
||||
|
||||
The **MCP tools** component exposes Model Context Protocol (MCP) servers, including your other flows, as tools for Langflow agents. For information about this component, see [Use Langflow as an MCP client](/mcp-client).
|
||||
|
||||
### MCP Tools (deprecated)
|
||||
|
||||
The **MCP Tools (stdio)** and **MCP Tools (SSE)** components are deprecated as of Langflow version 1.3.
|
||||
They are replaced by a single [MCP tools](/mcp-client) component.
|
||||
|
||||
## Search API
|
||||
|
||||
:::important
|
||||
As of Langflow 1.5, this component is available in the **Search** bundle.
|
||||
:::
|
||||
|
||||
This component calls the `searchapi.io` API. It can be used to search the web for information.
|
||||
|
||||
For more information, see the [SearchAPI documentation](https://www.searchapi.io/docs/google).
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
|
||||
**Inputs**
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| engine | String | The search engine to use. Default: `google`. |
|
||||
| api_key | SecretString | The API key for authenticating with SearchAPI. |
|
||||
| input_value | String | The search query or input for the API call. |
|
||||
| search_params | Dict | Additional parameters for customizing the search. |
|
||||
|
||||
**Outputs**
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| data | List[Data] | A list of Data objects containing search results. |
|
||||
| tool | Tool | A Tool object for use in LangChain workflows. |
|
||||
|
||||
</details>
|
||||
|
||||
## SearXNG Search Tool
|
||||
|
||||
:::important
|
||||
As of Langflow 1.5, this component is available in the **Search** bundle.
|
||||
:::
|
||||
The **SearXNG Search Tool** component is a legacy component.
|
||||
Replace this component with a [data component](/components-data) or another metasearch provider's [bundle](/components-bundle-components).
|
||||
|
||||
This component creates a tool for searching using SearXNG, a metasearch engine.
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
|
||||
**Inputs**
|
||||
It accepts the following parameters:
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| url | String | The URL of the SearXNG instance. |
|
||||
| max_results | Integer | The maximum number of results to return. |
|
||||
| categories | List[String] | The categories to search in. |
|
||||
| language | String | The language for the search results. |
|
||||
|
||||
**Outputs**
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| result_tool | Tool | A SearXNG search tool for use in LangChain. |
|
||||
|
||||
</details>
|
||||
|
||||
## Wikidata
|
||||
|
||||
:::important
|
||||
As of Langflow 1.5, this component is available in the **Search** bundle.
|
||||
:::
|
||||
|
||||
This component performs a search using the Wikidata API.
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
|
||||
**Inputs**
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| query | String | The text query for similarity search on Wikidata. |
|
||||
|
||||
**Outputs**
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| data | List[Data] | The search results from Wikidata API as a list of Data objects. |
|
||||
| text | Message | The search results formatted as a text message. |
|
||||
|
||||
</details>
|
||||
|
||||
## Wikipedia API
|
||||
|
||||
:::important
|
||||
As of Langflow 1.5, this component is available in the **Search** bundle.
|
||||
:::
|
||||
|
||||
This component creates a tool for searching and retrieving information from Wikipedia.
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
|
||||
**Inputs**
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| input_value | String | The search query input. |
|
||||
| lang | String | The language code for Wikipedia. Default: `en`. |
|
||||
| k | Integer | The number of results to return. |
|
||||
| load_all_available_meta | Boolean | Whether to load all available metadata. |
|
||||
| doc_content_chars_max | Integer | The maximum number of characters for document content. |
|
||||
|
||||
**Outputs**
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| results | List[Data] | A list of Wikipedia search results. |
|
||||
| tool | Tool | A Wikipedia search tool for use in LangChain. |
|
||||
|
||||
</details>
|
||||
|
||||
## Legacy components
|
||||
|
||||
Legacy components are available for use but are no longer supported.
|
||||
|
||||
### Calculator Tool
|
||||
|
||||
:::important
|
||||
This component is now available in [Helper components](/components-helpers#calculator).
|
||||
:::
|
||||
|
||||
This component allows you to evaluate basic arithmetic expressions. It supports addition, subtraction, multiplication, division, and exponentiation.
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
|
||||
**Inputs**
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| expression | String | The arithmetic expression to evaluate. For example, `4*4*(33/22)+12-20`. |
|
||||
|
||||
**Outputs**
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| result | Tool | A calculator tool for use in LangChain. |
|
||||
|
||||
</details>
|
||||
|
||||
### Python Code Structured Tool
|
||||
|
||||
:::important
|
||||
This component is in **Legacy**, which means it is available for use but no longer in active development.
|
||||
Instead, use the [Python Interpreter](/components-processing#python-interpreter).
|
||||
:::
|
||||
|
||||
This component creates a structured tool from Python code using a dataclass.
|
||||
|
||||
The component dynamically updates its configuration based on the provided Python code, allowing for custom function arguments and descriptions.
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
|
||||
**Inputs**
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| tool_code | String | The Python code for the tool's dataclass. |
|
||||
| tool_name | String | The name of the tool. |
|
||||
| tool_description | String | The description of the tool. |
|
||||
| return_direct | Boolean | Whether to return the function output directly. |
|
||||
| tool_function | String | The selected function for the tool. |
|
||||
| global_variables | Dict | Global variables or data for the tool. |
|
||||
|
||||
**Outputs**
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| result_tool | Tool | A structured tool created from the Python code. |
|
||||
|
||||
</details>
|
||||
|
||||
### Python REPL Tool
|
||||
|
||||
:::important
|
||||
The Python REPL tool is available in **Processing** and re-named the [Python Interpreter](/components-processing#python-interpreter)
|
||||
:::
|
||||
|
||||
This component creates a Python REPL (Read-Eval-Print Loop) tool for executing Python code.
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
|
||||
**Inputs**
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| name | String | The name of the tool. Default: `python_repl`. |
|
||||
| description | String | A description of the tool's functionality. |
|
||||
| global_imports | List[String] | A list of modules to import globally. Default: `math`. |
|
||||
|
||||
**Outputs**
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| tool | Tool | A Python REPL tool for use in LangChain. |
|
||||
|
||||
</details>
|
||||
|
||||
### Retriever Tool
|
||||
|
||||
This component creates a tool for interacting with a retriever in LangChain.
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
|
||||
**Inputs**
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| retriever | BaseRetriever | The retriever to interact with. |
|
||||
| name | String | The name of the tool. |
|
||||
| description | String | A description of the tool's functionality. |
|
||||
|
||||
**Outputs**
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| tool | Tool | A retriever tool for use in LangChain. |
|
||||
| url | String | Input parameter. The URL of the SearXNG instance. |
|
||||
| max_results | Integer | Input parameter. The maximum number of results to return. |
|
||||
| categories | List[String] | Input parameter. The categories to search in. |
|
||||
| language | String | Input parameter. The language for the search results. |
|
||||
| result_tool | Tool | Output parameter. A SearXNG search tool for use in LangChain. |
|
||||
|
||||
</details>
|
||||
|
|
@ -1,20 +1,22 @@
|
|||
---
|
||||
title: Vector stores
|
||||
title: Vector Stores
|
||||
slug: /components-vector-stores
|
||||
---
|
||||
|
||||
import Icon from "@site/src/components/icon";
|
||||
|
||||
# Vector store components in Langflow
|
||||
Langflow's vector store components connect to your vector databases or create in-memory vector stores for storing and retrieving vector data in flows.
|
||||
|
||||
Vector databases store vector data, which backs AI workloads like chatbots and Retrieval Augmented Generation.
|
||||
Vector databases and vector store components are specifically designed for storing and retrieving vector data, such as embeddings generated by language models. They are used to perform similarity searches, enabling applications like chatbots to retrieve relevant context from large datasets.
|
||||
|
||||
Vector database components establish connections to existing vector databases or create in-memory vector stores for storing and retrieving vector data.
|
||||
|
||||
Vector database components are distinct from [memory components](/components-memories), which are built specifically for storing and retrieving chat messages from internal Langflow memory or external databases. For more information, see [Memory management options](/memory).
|
||||
Other types of storage, like traditional structured databases and chat memory, are handled through other components like the [**SQL Database** component](/components-data#sql-database) or the [**Message History** component](/components-helpers#message-history).
|
||||
|
||||
## Use a vector store component in a flow
|
||||
|
||||
:::tip
|
||||
For examples of vector store components in flows, see [Create a vector RAG chatbot](/chat-with-rag) and [Embedding Model components](/components-embedding-models).
|
||||
:::
|
||||
|
||||
This example uses the **Chroma DB** vector store component. Your vector store component's parameters and authentication may be different, but the document ingestion workflow is the same. A document is loaded from a local machine and chunked. The vector store component generates embeddings with the connected [model](/components-models) component, and stores them in the connected vector database.
|
||||
|
||||
This vector data can then be retrieved for workloads like Retrieval Augmented Generation.
|
||||
|
|
@ -22,16 +24,24 @@ This vector data can then be retrieved for workloads like Retrieval Augmented Ge
|
|||

|
||||
|
||||
The user's chat input is embedded and compared to the vectors embedded during document ingestion for a similarity search.
|
||||
The results are output from the vector database component as a [Data](/data-types#data) object and parsed into text.
|
||||
This text fills the `{context}` variable in the **Prompt** component, which informs the **Open AI model** component's responses.
|
||||
The results are output from the vector database component as a [`Data`](/data-types#data) object and parsed into text.
|
||||
This text fills the `{context}` variable in the **Prompt Template** component, which informs the **OpenAI model** component's responses.
|
||||
|
||||

|
||||
|
||||
## Astra DB Vector Store
|
||||
### Configure vector store parameters
|
||||
|
||||
This component implements a Vector Store using Astra DB with search capabilities.
|
||||
Most vector store components have the same utility within a flow, but each provider can offer different parameters and functionality.
|
||||
Inspect a component's parameters to learn more about the inputs it accepts and how to configure it.
|
||||
|
||||
For more information, see the [DataStax documentation](https://docs.datastax.com/en/astra-db-serverless/databases/create-database.html).
|
||||
Many input parameters for vector store components are hidden by default in the visual editor.
|
||||
You can toggle parameters through the <Icon name="SlidersHorizontal" aria-hidden="true"/> **Controls** in each [component's header menu](/concepts-components#component-menus).
|
||||
|
||||
For details about a specific provider's parameters, see the provider's documentation.
|
||||
|
||||
## Astra DB
|
||||
|
||||
This component implements an [Astra DB Serverless vector store](https://docs.datastax.com/en/astra-db-serverless/databases/create-database.html) with search capabilities.
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
|
|
@ -69,39 +79,37 @@ For more information, see the [DataStax documentation](https://docs.datastax.com
|
|||
|
||||
### Generate embeddings
|
||||
|
||||
The **Astra DB Vector Store** component offers two methods for generating embeddings.
|
||||
The **Astra DB** component offers two methods for generating embeddings.
|
||||
|
||||
1. **Embedding Model**: Use your own embedding model by connecting an [Embeddings](/components-embedding-models) component in Langflow.
|
||||
|
||||
2. **Astra Vectorize**: Use Astra DB's built-in embedding generation service. When creating a new collection, choose the embeddings provider and models, including NVIDIA's `NV-Embed-QA` model hosted by Datastax.
|
||||
|
||||
:::important
|
||||
The embedding model selection is made when creating a new collection and cannot be changed later.
|
||||
:::
|
||||
|
||||
For an example of using the **Astra DB Vector Store** component with an embedding model, see the [Vector Store RAG starter project](/vector-store-rag).
|
||||
* ***Embedding Model**: Use your own embedding model by connecting an [**Embedding Model** component](/components-embedding-models) in Langflow.
|
||||
|
||||
* **Astra Vectorize**: Use Astra DB's built-in embedding generation service. When creating a new collection, choose the embeddings provider and models, including NVIDIA's `NV-Embed-QA` model hosted by DataStax.
|
||||
For more information, see the [Astra DB Serverless documentation](https://docs.datastax.com/en/astra-db-serverless/databases/embedding-generation.html).
|
||||
|
||||
:::important
|
||||
With vectorize, the embedding model you choose when you create a collection cannot be changed later.
|
||||
:::
|
||||
|
||||
For an example of using the **Astra DB** component with an embedding model, see the [**Vector Store RAG** template](/vector-store-rag).
|
||||
|
||||
### Hybrid search
|
||||
|
||||
The **Astra DB** component includes **hybrid search**, which is enabled by default.
|
||||
The **Astra DB** component includes Astra DB's [hybrid search](https://docs.datastax.com/en/astra-db-serverless/databases/hybrid-search.html) feature through the Astra DB Data API.
|
||||
|
||||
The component fields related to hybrid search are **Search Query**, **Lexical Terms**, and **Reranker**.
|
||||
Hybrid search performs a vector similarity search and a lexical search, compares the results of both searches, and then returns the most relevant results overall.
|
||||
|
||||
* **Search Query** finds results by vector similarity.
|
||||
* **Lexical Terms** is a comma-separated string of keywords, like `features, data, attributes, characteristics`.
|
||||
* **Reranker** is the re-ranker model used in the hybrid search.
|
||||
The re-ranker model is `nvidia/llama-3.2-nv.reranker`.
|
||||
To use hybrid search through the **Astra DB** component, you must [create a collection with that supports hybrid search](https://docs.datastax.com/en/astra-db-serverless/api-reference/collection-methods/create-collection.html#example-hybrid).
|
||||
|
||||
[Hybrid search](https://docs.datastax.com/en/astra-db-serverless/databases/hybrid-search.html) performs a vector similarity search and a lexical search, compares the results of both searches, and then returns the most relevant results overall.
|
||||
The following **Astra DB** component parameters are used for hybrid search:
|
||||
|
||||
:::important
|
||||
To use hybrid search, your collection must be created with vector, lexical, and rerank capabilities enabled. These capabilities are enabled by default when you create a collection in a database in the AWS us-east-2 region.
|
||||
For more information, see the [DataStax documentation](https://docs.datastax.com/en/astra-db-serverless/api-reference/collection-methods/create-collection.html#example-hybrid).
|
||||
:::
|
||||
* **Search Query**: The query to use for vector search.
|
||||
* **Lexical Terms**: A comma-separated string of keywords, like `features, data, attributes, characteristics`.
|
||||
* **Reranker**: The re-ranker model to use for hybrid search, such as `nvidia/llama-3.2-nv.reranker`.
|
||||
|
||||
To use **Hybrid search** in the **Astra DB** component, do the following:
|
||||
<details>
|
||||
<summary>Hybrid search example</summary>
|
||||
|
||||
To use hybrid search through the **Astra DB** component, do the following:
|
||||
|
||||
1. Click **New Flow** > **RAG** > **Hybrid Search RAG**.
|
||||
2. In the **OpenAI** model component, add your **OpenAI API key**.
|
||||
|
|
@ -109,22 +117,28 @@ To use **Hybrid search** in the **Astra DB** component, do the following:
|
|||
4. In the **Database** field, select your database.
|
||||
5. In the **Collection** field, select or create a collection with hybrid search capabilities enabled.
|
||||
6. In the **Playground**, enter a question about your data, such as `What are the features of my data?`
|
||||
Your query is sent to two components: an **OpenAI** model component and the **Astra DB** vector database component.
|
||||
The **OpenAI** component contains a prompt for creating the lexical query from your input:
|
||||
```text
|
||||
You are a database query planner that takes a user's requests, and then converts to a search against the subject matter in question.
|
||||
You should convert the query into:
|
||||
1. A list of keywords to use against a Lucene text analyzer index, no more than 4. Strictly unigrams.
|
||||
2. A question to use as the basis for a QA embedding engine.
|
||||
Avoid common keywords associated with the user's subject matter.
|
||||
```
|
||||
|
||||
Your query is sent to two components: an **OpenAI** model component and the **Astra DB** vector database component.
|
||||
The **OpenAI** component contains a prompt for creating the lexical query from your input:
|
||||
|
||||
```text
|
||||
You are a database query planner that takes a user's requests, and then converts to a search against the subject matter in question.
|
||||
You should convert the query into:
|
||||
1. A list of keywords to use against a Lucene text analyzer index, no more than 4. Strictly unigrams.
|
||||
2. A question to use as the basis for a QA embedding engine.
|
||||
Avoid common keywords associated with the user's subject matter.
|
||||
```
|
||||
|
||||
7. To view the keywords and questions the **OpenAI** component generates from your collection, in the **OpenAI** component, click <Icon name="TextSearch" aria-hidden="true"/> **Inspect output**.
|
||||
```
|
||||
1. Keywords: features, data, attributes, characteristics
|
||||
2. Question: What characteristics can be identified in my data?
|
||||
```
|
||||
|
||||
```
|
||||
1. Keywords: features, data, attributes, characteristics
|
||||
2. Question: What characteristics can be identified in my data?
|
||||
```
|
||||
|
||||
8. To view the [DataFrame](/data-types#dataframe) generated from the **OpenAI** component's response, in the **Structured Output** component, click <Icon name="TextSearch" aria-hidden="true"/> **Inspect output**.
|
||||
The DataFrame is passed to a **Parser** component, which parses the contents of the **Keywords** column into a string.
|
||||
|
||||
The DataFrame is passed to a **Parser** component, which parses the contents of the **Keywords** column into a string.
|
||||
|
||||
This string of comma-separated words is passed to the **Lexical Terms** port of the **Astra DB** component.
|
||||
Note that the **Search Query** port of the Astra DB port is connected to the **Chat Input** component from step 6.
|
||||
|
|
@ -133,11 +147,11 @@ The DataFrame is passed to a **Parser** component, which parses the contents of
|
|||
The reranker compares the vector search results against the string of terms from the lexical search.
|
||||
The highest-ranked results of your hybrid search are returned to the **Playground**.
|
||||
|
||||
For more information, see the [DataStax documentation](https://docs.datastax.com/en/astra-db-serverless/databases/hybrid-search.html).
|
||||
</details>
|
||||
|
||||
## AstraDB Graph vector store
|
||||
## Astra DB Graph
|
||||
|
||||
This component implements a Vector Store using AstraDB with graph capabilities.
|
||||
This component implements a vector store using Astra DB with graph capabilities.
|
||||
For more information, see the [Astra DB Serverless documentation](https://docs.datastax.com/en/astra-db-serverless/tutorials/graph-rag.html).
|
||||
|
||||
<details>
|
||||
|
|
@ -147,12 +161,12 @@ For more information, see the [Astra DB Serverless documentation](https://docs.d
|
|||
|
||||
| Name | Display Name | Info |
|
||||
|------|--------------|------|
|
||||
| collection_name | Collection Name | The name of the collection within AstraDB where the vectors are stored. Required. |
|
||||
| token | Astra DB Application Token | Authentication token for accessing AstraDB. Required. |
|
||||
| api_endpoint | API Endpoint | API endpoint URL for the AstraDB service. Required. |
|
||||
| collection_name | Collection Name | The name of the collection within Astra DB where the vectors are stored. Required. |
|
||||
| token | Astra DB Application Token | Authentication token for accessing Astra DB. Required. |
|
||||
| api_endpoint | API Endpoint | API endpoint URL for the Astra DB service. Required. |
|
||||
| search_input | Search Input | Query string for similarity search. |
|
||||
| ingest_data | Ingest Data | Data to be ingested into the vector store. |
|
||||
| namespace | Namespace | Optional namespace within AstraDB to use for the collection. |
|
||||
| keyspace | Keyspace | Optional keyspace within Astra DB to use for the collection. |
|
||||
| embedding | Embedding Model | Embedding model to use. |
|
||||
| metric | Metric | Distance metric for vector comparisons. The options are "cosine", "euclidean", "dot_product". |
|
||||
| setup_mode | Setup Mode | Configuration mode for setting up the vector store. The options are "Sync", "Async", "Off". |
|
||||
|
|
@ -174,7 +188,7 @@ For more information, see the [Astra DB Serverless documentation](https://docs.d
|
|||
|
||||
## Cassandra
|
||||
|
||||
This component creates a Cassandra Vector Store with search capabilities.
|
||||
This component creates a Cassandra vector store with search capabilities.
|
||||
For more information, see the [Cassandra documentation](https://cassandra.apache.org/doc/latest/cassandra/vector-search/overview.html).
|
||||
|
||||
<details>
|
||||
|
|
@ -184,11 +198,11 @@ For more information, see the [Cassandra documentation](https://cassandra.apache
|
|||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| database_ref | String | Contact points for the database or AstraDB database ID. |
|
||||
| username | String | Username for the database (leave empty for AstraDB). |
|
||||
| token | SecretString | User password for the database or AstraDB token. |
|
||||
| keyspace | String | Table Keyspace or AstraDB namespace. |
|
||||
| table_name | String | Name of the table or AstraDB collection. |
|
||||
| database_ref | String | Contact points for the database or Astra DB database ID. |
|
||||
| username | String | Username for the database (leave empty for Astra DB). |
|
||||
| token | SecretString | User password for the database or Astra DB token. |
|
||||
| keyspace | String | Table or keyspace. |
|
||||
| table_name | String | Name of the table or Astra DB collection. |
|
||||
| ttl_seconds | Integer | Time-to-live for added texts. |
|
||||
| batch_size | Integer | Number of data to process in a single batch. |
|
||||
| setup_mode | String | Configuration mode for setting up the Cassandra table. |
|
||||
|
|
@ -212,9 +226,9 @@ For more information, see the [Cassandra documentation](https://cassandra.apache
|
|||
|
||||
</details>
|
||||
|
||||
## Cassandra Graph Vector Store
|
||||
## Cassandra Graph
|
||||
|
||||
This component implements a Cassandra Graph Vector Store with search capabilities.
|
||||
This component implements a Cassandra Graph vector store with search capabilities.
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
|
|
@ -223,11 +237,11 @@ This component implements a Cassandra Graph Vector Store with search capabilitie
|
|||
|
||||
| Name | Display Name | Info |
|
||||
|------|--------------|------|
|
||||
| database_ref | Contact Points / Astra Database ID | The contact points for the database or AstraDB database ID. Required. |
|
||||
| username | Username | The username for the database. Leave this field empty for AstraDB. |
|
||||
| token | Password / AstraDB Token | The user password for the database or AstraDB token. Required. |
|
||||
| keyspace | Keyspace | The table Keyspace or AstraDB namespace. Required. |
|
||||
| table_name | Table Name | The name of the table or AstraDB collection where vectors are stored. Required. |
|
||||
| database_ref | Contact Points / Astra Database ID | The contact points for the database or Astra DB database ID. Required. |
|
||||
| username | Username | The username for the database. Leave this field empty for Astra DB. |
|
||||
| token | Password / Astra DB Token | The user password for the database or Astra DB token. Required. |
|
||||
| keyspace | Keyspace | The table or keyspace. Required. |
|
||||
| table_name | Table Name | The name of the table or Astra DB collection where vectors are stored. Required. |
|
||||
| setup_mode | Setup Mode | The configuration mode for setting up the Cassandra table. The options are "Sync" or "Off". Default: "Sync". |
|
||||
| cluster_kwargs | Cluster arguments | An optional dictionary of additional keyword arguments for the Cassandra cluster. |
|
||||
| search_query | Search Query | The query string for similarity search. |
|
||||
|
|
@ -250,9 +264,11 @@ This component implements a Cassandra Graph Vector Store with search capabilitie
|
|||
|
||||
## Chroma DB
|
||||
|
||||
This component creates a Chroma Vector Store with search capabilities.
|
||||
The **Chroma DB** component creates an ephemeral, Chroma vector database with search capabilities that you can use for experimentation and vector storage.
|
||||
For more information, see the [Chroma documentation](https://docs.trychroma.com/).
|
||||
|
||||
The Chroma DB component creates an ephemeral vector database for experimentation and vector storage.
|
||||
<details>
|
||||
<summary>Chroma DB sample flow</summary>
|
||||
|
||||
1. To use this component in a flow, connect it to a component that outputs **Data** or **DataFrame**.
|
||||
This example splits text from a [URL](/components-data#url) component, and computes embeddings with the connected **OpenAI Embeddings** component. Chroma DB computes embeddings by default, but you can connect your own embeddings model, as seen in this example.
|
||||
|
|
@ -270,7 +286,7 @@ When loading duplicate documents, enable the **Allow Duplicates** option in Chro
|
|||
6. To query your loaded data, open the **Playground** and query your database.
|
||||
Your input is converted to vector data and compared to the stored vectors in a vector similarity search.
|
||||
|
||||
For more information, see the [Chroma documentation](https://docs.trychroma.com/).
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
|
|
@ -305,7 +321,7 @@ For more information, see the [Chroma documentation](https://docs.trychroma.com/
|
|||
|
||||
## Clickhouse
|
||||
|
||||
This component implements a Clickhouse Vector Store with search capabilities.
|
||||
This component implements a Clickhouse vector store with search capabilities.
|
||||
For more information, see the [Clickhouse Documentation](https://clickhouse.com/docs/en/intro).
|
||||
|
||||
<details>
|
||||
|
|
@ -343,7 +359,7 @@ For more information, see the [Clickhouse Documentation](https://clickhouse.com/
|
|||
|
||||
## Couchbase
|
||||
|
||||
This component creates a Couchbase Vector Store with search capabilities.
|
||||
This component creates a Couchbase vector store with search capabilities.
|
||||
For more information, see the [Couchbase documentation](https://docs.couchbase.com/home/index.html).
|
||||
|
||||
<details>
|
||||
|
|
@ -373,52 +389,9 @@ For more information, see the [Couchbase documentation](https://docs.couchbase.c
|
|||
|
||||
</details>
|
||||
|
||||
## Local DB
|
||||
|
||||
The **Local DB** component is Langflow's enhanced version of Chroma DB.
|
||||
|
||||
The component adds a user-friendly interface with two modes (Ingest and Retrieve), automatic collection management, and built-in persistence in Langflow's cache directory.
|
||||
|
||||
Local DB includes **Ingest** and **Retrieve** modes.
|
||||
|
||||
The **Ingest** mode works similarly to [ChromaDB](#chroma-db), and persists your database to the Langflow cache directory. The Langflow cache directory location is specified in `LANGFLOW_CONFIG_DIR`. For more information, see [Environment variables](/environment-variables).
|
||||
|
||||
The **Retrieve** mode can query your **Chroma DB** collections.
|
||||
|
||||

|
||||
|
||||
For more information, see the [Chroma documentation](https://docs.trychroma.com/).
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
|
||||
**Inputs**
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| collection_name | String | The name of the Chroma collection. Default: "langflow". |
|
||||
| persist_directory | String | Custom base directory to save the vector store. Collections are stored under `$DIRECTORY/vector_stores/$COLLECTION_NAME`. If not specified, it uses your system's cache folder. |
|
||||
| existing_collections | String | Select a previously created collection to search through its stored data. |
|
||||
| embedding | Embeddings | The embedding function to use for the vector store. |
|
||||
| allow_duplicates | Boolean | If false, will not add documents that are already in the Vector Store. |
|
||||
| search_type | String | Type of search to perform: "Similarity" or "MMR". |
|
||||
| ingest_data | Data/DataFrame | Data to store. It is embedded and indexed for semantic search. |
|
||||
| search_query | String | Enter text to search for similar content in the selected collection. |
|
||||
| number_of_results | Integer | Number of results to return. Default: 10. |
|
||||
| limit | Integer | Limit the number of records to compare when Allow Duplicates is False. |
|
||||
|
||||
**Outputs**
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| vector_store | Chroma | A local Chroma vector store instance configured with the specified parameters. |
|
||||
| search_results | List[Data](/data-types#data) | The results of the similarity search as a list of [Data](/data-types#data) objects. |
|
||||
|
||||
</details>
|
||||
|
||||
## Elasticsearch
|
||||
|
||||
This component creates an Elasticsearch Vector Store with search capabilities.
|
||||
This component creates an Elasticsearch vector store with search capabilities.
|
||||
For more information, see the [Elasticsearch documentation](https://www.elastic.co/guide/en/elasticsearch/reference/current/dense-vector.html).
|
||||
|
||||
<details>
|
||||
|
|
@ -450,7 +423,7 @@ For more information, see the [Elasticsearch documentation](https://www.elastic.
|
|||
|
||||
## FAISS
|
||||
|
||||
This component creates a FAISS Vector Store with search capabilities.
|
||||
This component creates a FAISS vector store with search capabilities.
|
||||
For more information, see the [FAISS documentation](https://faiss.ai/index.html).
|
||||
|
||||
<details>
|
||||
|
|
@ -477,12 +450,13 @@ For more information, see the [FAISS documentation](https://faiss.ai/index.html)
|
|||
|
||||
</details>
|
||||
|
||||
|
||||
## Graph RAG
|
||||
|
||||
This component performs Graph RAG (Retrieval Augmented Generation) traversal in a vector store, enabling graph-based document retrieval.
|
||||
This component performs Graph RAG traversal in a vector store, enabling graph-based document retrieval.
|
||||
For more information, see the [Graph RAG documentation](https://datastax.github.io/graph-rag/).
|
||||
|
||||
For an example flow, see the **Graph RAG** template.
|
||||
For an example flow, see the **Graph RAG** template in Langflow.
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
|
|
@ -508,14 +482,14 @@ For an example flow, see the **Graph RAG** template.
|
|||
|
||||
## Hyper-Converged Database (HCD)
|
||||
|
||||
This component implements a Vector Store using HCD.
|
||||
This component implements a vector store using HCD.
|
||||
|
||||
To use the HCD vector store, add your deployment's collection name, username, password, and HCD Data API endpoint.
|
||||
The endpoint must be formatted like `http[s]://**DOMAIN_NAME** or **IP_ADDRESS**[:port]`, for example, `http://192.0.2.250:8181`.
|
||||
|
||||
Replace **DOMAIN_NAME** or **IP_ADDRESS** with the domain name or IP address of your HCD Data API connection.
|
||||
|
||||
To use the HCD vector store for embeddings ingestion, connect it to an embeddings model and a file loader:
|
||||
To use the HCD vector store for embeddings ingestion, connect it to an embeddings model and a file loader.
|
||||
|
||||

|
||||
|
||||
|
|
@ -559,9 +533,58 @@ To use the HCD vector store for embeddings ingestion, connect it to an embedding
|
|||
|
||||
</details>
|
||||
|
||||
## Local DB
|
||||
|
||||
The **Local DB** component is Langflow's enhanced version of Chroma DB.
|
||||
|
||||
The component adds a user-friendly interface with two modes (Ingest and Retrieve), automatic collection management, and built-in persistence in Langflow's cache directory.
|
||||
|
||||
Local DB includes **Ingest** and **Retrieve** modes.
|
||||
|
||||
The **Ingest** mode works similarly to [ChromaDB](#chroma-db), and persists your database to the Langflow cache directory. The Langflow cache directory location is specified in `LANGFLOW_CONFIG_DIR`. For more information, see [Environment variables](/environment-variables).
|
||||
|
||||
The **Retrieve** mode can query your **Chroma DB** collections.
|
||||
|
||||

|
||||
|
||||
For more information, see the [Chroma documentation](https://docs.trychroma.com/).
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
|
||||
**Inputs**
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| collection_name | String | The name of the Chroma collection. Default: "langflow". |
|
||||
| persist_directory | String | Custom base directory to save the vector store. Collections are stored under `$DIRECTORY/vector_stores/$COLLECTION_NAME`. If not specified, it uses your system's cache folder. |
|
||||
| existing_collections | String | Select a previously created collection to search through its stored data. |
|
||||
| embedding | Embeddings | The embedding function to use for the vector store. |
|
||||
| allow_duplicates | Boolean | If false, will not add documents that are already in the vector store. |
|
||||
| search_type | String | Type of search to perform: "Similarity" or "MMR". |
|
||||
| ingest_data | Data/DataFrame | Data to store. It is embedded and indexed for semantic search. |
|
||||
| search_query | String | Enter text to search for similar content in the selected collection. |
|
||||
| number_of_results | Integer | Number of results to return. Default: 10. |
|
||||
| limit | Integer | Limit the number of records to compare when Allow Duplicates is False. |
|
||||
|
||||
**Outputs**
|
||||
|
||||
| Name | Type | Description |
|
||||
|------|------|-------------|
|
||||
| vector_store | Chroma | A local Chroma vector store instance configured with the specified parameters. |
|
||||
| search_results | List[Data](/data-types#data) | The results of the similarity search as a list of [Data](/data-types#data) objects. |
|
||||
|
||||
</details>
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## Milvus
|
||||
|
||||
This component creates a Milvus Vector Store with search capabilities.
|
||||
This component creates a Milvus vector store with search capabilities.
|
||||
For more information, see the [Milvus documentation](https://milvus.io/docs).
|
||||
|
||||
<details>
|
||||
|
|
@ -598,7 +621,7 @@ For more information, see the [Milvus documentation](https://milvus.io/docs).
|
|||
|
||||
## MongoDB Atlas
|
||||
|
||||
This component creates a MongoDB Atlas Vector Store with search capabilities.
|
||||
This component creates a MongoDB Atlas vector store with search capabilities.
|
||||
For more information, see the [MongoDB Atlas documentation](https://www.mongodb.com/docs/atlas/atlas-vector-search/tutorials/vector-search-quick-start/).
|
||||
|
||||
<details>
|
||||
|
|
@ -631,10 +654,10 @@ For more information, see the [MongoDB Atlas documentation](https://www.mongodb.
|
|||
|
||||
</details>
|
||||
|
||||
## Opensearch
|
||||
## OpenSearch
|
||||
|
||||
This component creates an Opensearch vector store with search capabilities
|
||||
For more information, see [Opensearch documentation](https://opensearch.org/platform/search/vector-database.html).
|
||||
This component creates an OpenSearch vector store with search capabilities
|
||||
For more information, see [OpenSearch documentation](https://opensearch.org/platform/search/vector-database.html).
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
|
|
@ -667,7 +690,7 @@ For more information, see [Opensearch documentation](https://opensearch.org/plat
|
|||
|
||||
## PGVector
|
||||
|
||||
This component creates a PGVector Vector Store with search capabilities.
|
||||
This component creates a PGVector vector store with search capabilities.
|
||||
For more information, see the [PGVector documentation](https://github.com/pgvector/pgvector).
|
||||
|
||||
<details>
|
||||
|
|
@ -695,7 +718,7 @@ For more information, see the [PGVector documentation](https://github.com/pgvect
|
|||
|
||||
## Pinecone
|
||||
|
||||
This component creates a Pinecone Vector Store with search capabilities.
|
||||
This component creates a Pinecone vector store with search capabilities.
|
||||
For more information, see the [Pinecone documentation](https://docs.pinecone.io/home).
|
||||
|
||||
<details>
|
||||
|
|
@ -726,7 +749,7 @@ For more information, see the [Pinecone documentation](https://docs.pinecone.io/
|
|||
|
||||
## Qdrant
|
||||
|
||||
This component creates a Qdrant Vector Store with search capabilities.
|
||||
This component creates a Qdrant vector store with search capabilities.
|
||||
For more information, see the [Qdrant documentation](https://qdrant.tech/documentation/).
|
||||
|
||||
<details>
|
||||
|
|
@ -764,7 +787,7 @@ For more information, see the [Qdrant documentation](https://qdrant.tech/documen
|
|||
|
||||
## Redis
|
||||
|
||||
This component creates a Redis Vector Store with search capabilities.
|
||||
This component creates a Redis vector store with search capabilities.
|
||||
For more information, see the [Redis documentation](https://redis.io/docs/latest/develop/interact/search-and-query/advanced-concepts/vectors/).
|
||||
|
||||
<details>
|
||||
|
|
@ -794,7 +817,7 @@ For more information, see the [Redis documentation](https://redis.io/docs/latest
|
|||
|
||||
## Supabase
|
||||
|
||||
This component creates a connection to a Supabase Vector Store with search capabilities.
|
||||
This component creates a connection to a Supabase vector store with search capabilities.
|
||||
For more information, see the [Supabase documentation](https://supabase.com/docs/guides/ai).
|
||||
|
||||
<details>
|
||||
|
|
@ -824,7 +847,7 @@ For more information, see the [Supabase documentation](https://supabase.com/docs
|
|||
|
||||
## Upstash
|
||||
|
||||
This component creates an Upstash Vector Store with search capabilities.
|
||||
This component creates an Upstash vector store with search capabilities.
|
||||
For more information, see the [Upstash documentation](https://upstash.com/docs/introduction).
|
||||
|
||||
<details>
|
||||
|
|
@ -855,7 +878,7 @@ For more information, see the [Upstash documentation](https://upstash.com/docs/i
|
|||
|
||||
## Vectara
|
||||
|
||||
This component creates a Vectara Vector Store with search capabilities.
|
||||
This component creates a Vectara vector store with search capabilities.
|
||||
For more information, see the [Vectara documentation](https://docs.vectara.com/docs/).
|
||||
|
||||
<details>
|
||||
|
|
@ -882,36 +905,14 @@ For more information, see the [Vectara documentation](https://docs.vectara.com/d
|
|||
|
||||
</details>
|
||||
|
||||
## Vectara Search
|
||||
## Vectara RAG
|
||||
|
||||
This component searches a Vectara Vector Store for documents based on the provided input.
|
||||
This component enabled Vectara's full end-to-end RAG capabilities with reranking options.
|
||||
For more information, see the [Vectara documentation](https://docs.vectara.com/docs/).
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
|
||||
**Inputs**
|
||||
|
||||
| Name | Type | Description |
|
||||
|---------------------|--------------|-------------------------------------------|
|
||||
| search_type | String | The type of search, such as "Similarity" or "MMR". |
|
||||
| input_value | String | The search query. |
|
||||
| vectara_customer_id | String | The Vectara customer ID. |
|
||||
| vectara_corpus_id | String | The Vectara corpus ID. |
|
||||
| vectara_api_key | SecretString | The Vectara API key. |
|
||||
| files_url | List[String] | Optional URLs for file initialization. |
|
||||
|
||||
**Outputs**
|
||||
|
||||
| Name | Type | Description |
|
||||
|----------------|------------|----------------------------|
|
||||
| search_results | List[Data] | The results of the similarity search as a list of [Data](/data-types#data) objects. |
|
||||
|
||||
</details>
|
||||
|
||||
## Weaviate
|
||||
|
||||
This component facilitates a Weaviate Vector Store setup, optimizing text and document indexing and retrieval.
|
||||
This component facilitates a Weaviate vector store setup, optimizing text and document indexing and retrieval.
|
||||
For more information, see the [Weaviate Documentation](https://weaviate.io/developers/weaviate).
|
||||
|
||||
<details>
|
||||
|
|
@ -936,34 +937,4 @@ For more information, see the [Weaviate Documentation](https://weaviate.io/devel
|
|||
|--------------|------------------|-------------------------------|
|
||||
| vector_store | WeaviateVectorStore | The Weaviate vector store instance. |
|
||||
|
||||
</details>
|
||||
|
||||
## Weaviate Search
|
||||
|
||||
This component searches a Weaviate Vector Store for documents similar to the input.
|
||||
For more information, see the [Weaviate Documentation](https://weaviate.io/developers/weaviate).
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
|
||||
**Inputs**
|
||||
|
||||
| Name | Type | Description |
|
||||
|---------------|--------------|-------------------------------------------|
|
||||
| search_type | String | The type of search, such as "Similarity" or "MMR" |
|
||||
| input_value | String | The search query. |
|
||||
| weaviate_url | String | The default instance URL. |
|
||||
| search_by_text| Boolean | A boolean value that indicates whether to search by text. |
|
||||
| api_key | SecretString | The optional API key for authentication. |
|
||||
| index_name | String | The optional index name. |
|
||||
| text_key | String | The default text extraction key. |
|
||||
| embedding | Embeddings | The embeddings model used. |
|
||||
| attributes | List[String] | Optional additional attributes. |
|
||||
|
||||
**Outputs**
|
||||
|
||||
| Name | Type | Description |
|
||||
|----------------|------------|----------------------------|
|
||||
| search_results | List[Data] | The results of the similarity search as a list of [Data](/data-types#data) objects. |
|
||||
|
||||
</details>
|
||||
|
|
@ -5,74 +5,98 @@ slug: /concepts-file-management
|
|||
|
||||
import Icon from "@site/src/components/icon";
|
||||
|
||||
Upload, store, and manage files in Langflow's **File management** system.
|
||||
Each Langflow server has a file management system where you can store files that you want to use in your flows.
|
||||
|
||||
Uploading files to the **File management** system keeps your files in a central location, and allows you to re-use files across flows without repeated manual uploads.
|
||||
Files uploaded to Langflow file management are stored locally to your Langflow server, and they are available to all of your flows.
|
||||
|
||||
## Upload a file
|
||||
Uploading files to Langflow file management keeps your files in a central location, and allows you to reuse files across flows without repeated manual uploads.
|
||||
|
||||
The **File management** system is available at the `/files` URL. For example, if you're running Langflow at the default `http://localhost:7860` address, the **File management** system is located at `http://localhost:7860/files`.
|
||||
## Use the file management UI
|
||||
|
||||
To upload a file from your local machine:
|
||||
You can use the file management UI to upload files from your local machine to your own Langflow server.
|
||||
You can also manage all files that have been uploaded to your Langflow server.
|
||||
|
||||
1. From the **My Files** window at `http://localhost:7860/files`, click **Upload**.
|
||||
2. Select the file to upload.
|
||||
The file is uploaded to Langflow.
|
||||
1. Navigate to Langflow file management:
|
||||
|
||||
You can upload multiple files in a single action.
|
||||
Files are available to flows stored in different projects.
|
||||
* In the Langflow UI, on the [**Projects** page](#projects) page, click **My Files** below the list of projects.
|
||||
* From a browser, navigate to your Langflow server's `/files` endpoint, such as `http://localhost:7860/files`. Modify the base URL as needed for your Langflow server.
|
||||
* For programmatic file management, use the [Langflow API files endpoints](/api-files). However, the following steps assume you're using the file management UI.
|
||||
|
||||
Files stored in **My Files** can be renamed, downloaded, duplicated, or deleted.
|
||||
2. On the **My Files** page, click **Upload**.
|
||||
|
||||
To delete a file from your project, hover over a file's icon to click and select it, and then click <Icon name="Trash2" aria-hidden="true"/> **Delete**.
|
||||
3. Select one or more files to upload.
|
||||
|
||||
After uploading files, you can rename, download, copy, or delete files within the file management UI:
|
||||
|
||||
* To delete a file, hover over a file's icon, select it, and then click <Icon name="Trash2" aria-hidden="true"/> **Delete**.
|
||||
You can delete multiple files in a single action.
|
||||
|
||||
To download a file from your project, hover over a file's icon to click and select it, and then click <Icon name="Download" aria-hidden="true"/> **Download**.
|
||||
You can download multiple files in a single action, but they will be saved together in a .ZIP file.
|
||||
* To download a file, hover over a file's icon, select it, and then click <Icon name="Download" aria-hidden="true"/> **Download**.
|
||||
If you download multiple files in a single action, they are saved together in a zip file.
|
||||
|
||||
## Use uploaded files in a flow
|
||||
## Upload and manage files with the Langflow API
|
||||
|
||||
To use your uploaded files in flows:
|
||||
With the Langflow API, you can upload and manage files in Langflow file management, and you can send files to flows programmatically at runtime.
|
||||
|
||||
1. Include the [File](/components-data#file) component in a flow.
|
||||
2. To select a document to load, in the **File** component, click the **Select files** button.
|
||||
3. Select a file to upload, and then click **Select file**. The loaded file name appears in the component.
|
||||
For more information and examples, see [Files endpoints](/api-files) and [Create a chatbot that can ingest files](/chat-with-files).
|
||||
|
||||
For an example of using the **File** component in a flow, see the [Document QA tutorial project](/document-qa).
|
||||
## Use files in a flow
|
||||
|
||||
:::note
|
||||
If you prefer a one-time upload, the [File](/components-data#file) component still allows one-time uploads directly from your local machine.
|
||||
:::
|
||||
To use files in your Langflow file management system in a flow, add a component that accepts file input to your flow, such as the **File** component.
|
||||
|
||||
## Send files to a flow with the Langflow API
|
||||
For example, add a **File** component to your flow, click **Select files**, and then select files from the **My Files** list.
|
||||
|
||||
For information on file management with the Langflow API, see [Files endpoints](/api-files).
|
||||
This list includes all files in your server's file management system, but you can only select [file types that are supported by the **File** component](/components-data#file).
|
||||
If you need another file type, you must use a different component that supports that file type, or you need to convert it to a supported type before uploading it.
|
||||
|
||||
## Supported file types
|
||||
For more information about the **File** component and other data loading components, see [Data components](/components-data).
|
||||
|
||||
The maximum supported file size is 100 MB.
|
||||
### Load files at runtime
|
||||
|
||||
Text files:
|
||||
You can use preloaded files in your flows, and you can load files at runtime, if your flow accepts file input.
|
||||
For an example, see [Create a chatbot that can ingest files](/chat-with-files).
|
||||
|
||||
- `.txt` - Text files
|
||||
- `.md`, `.mdx` - Markdown files
|
||||
- `.csv` - CSV files
|
||||
- `.json` - JSON files
|
||||
- `.yaml`, `.yml` - YAML files
|
||||
- `.xml` - XML files
|
||||
- `.html`, `.htm` - HTML files
|
||||
- `.pdf` - PDF files
|
||||
- `.docx` - Word documents
|
||||
- `.py` - Python files
|
||||
- `.sh` - Shell scripts
|
||||
- `.sql` - SQL files
|
||||
- `.js` - JavaScript files
|
||||
- `.ts`, `.tsx` - TypeScript files
|
||||
## Upload images
|
||||
|
||||
Archive formats (for bundling multiple files):
|
||||
Langflow supports base64 images in the following formats:
|
||||
|
||||
- `.zip` - ZIP archives
|
||||
- `.tar` - TAR archives
|
||||
- `.tgz` - Gzipped TAR archives
|
||||
- `.bz2` - Bzip2 compressed files
|
||||
- `.gz` - Gzip compressed files
|
||||
* PNG
|
||||
* JPG/JPEG
|
||||
* GIF
|
||||
* BMP
|
||||
* WebP
|
||||
|
||||
You can upload images to the **Playground** chat interface and as runtime input with the Langflow API.
|
||||
|
||||
* In the **Playground**, you can drag-and-drop images into the chat input area, or you can click the **Attach image** icon to select an image to upload.
|
||||
|
||||
* When you trigger a flow with the `/api/v1/run/$FLOW_ID` endpoint, you can use the `files` parameter to attach the base64-encoded image data to the request payload:
|
||||
|
||||
```bash
|
||||
curl -X POST "http://$LANGFLOW_SERVER_ADDRESS/api/v1/run/$FLOW_ID" \
|
||||
-H "Content-Type: application/json" \
|
||||
-H "x-api-key: $LANGFLOW_API_KEY" \
|
||||
-d '{
|
||||
"session_id": "custom_session_123",
|
||||
"input_value": "What is in this image?",
|
||||
"input_type": "chat",
|
||||
"output_type": "chat",
|
||||
"files": ["data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAA..."]
|
||||
}'
|
||||
```
|
||||
|
||||
For more specialized image processing, browse third-party [bundles](/components-bundle-components) or [create your own components](/components-custom-components).
|
||||
|
||||
## Work with video files
|
||||
|
||||
For videos, see the **Twelve Labs** and **YouTube** [bundles](/components-bundle-components) in the Langflow **Components** menu.
|
||||
|
||||
## Set the maximum file size
|
||||
|
||||
By default, the maximum file size is 100 MB.
|
||||
To modify this value, change the [`--max-file-size-upload` environment variable](/environment-variables#LANGFLOW_MAX_FILE_SIZE_UPLOAD).
|
||||
|
||||
## See also
|
||||
|
||||
* [Data components](/components-data)
|
||||
* [Processing components](/components-processing)
|
||||
|
|
@ -48,10 +48,10 @@ For more information about component configuration, including port types and und
|
|||
|
||||
### Run a flow
|
||||
|
||||
After you build a flow, you can test it in the [**Playground**](/concepts-playground), and then [publish your flow](/concepts-publish) to embed or share your flow.
|
||||
For more information about application development with Langflow, see [Develop an application with Langflow](/develop-application).
|
||||
After you build a prototype flow, you can test it in the [**Playground**](/concepts-playground).
|
||||
When you're ready to use Langflow for application development, learn how to [trigger flows with the Langflow API](/concepts-publish), explore more advanced configuration options like [custom dependencies](/install-custom-dependencies), and, eventually, [containerize your Langflow application](/develop-application).
|
||||
|
||||
If you need to build Langflow as a dependency of an application or deploy a Langflow server for API access over the public internet, see [Langflow deployment overview](/deployment-overview).
|
||||
When you're ready to go to production or deploy a Langflow MCP server for access over the public internet, see [Langflow deployment overview](/deployment-overview).
|
||||
|
||||
#### Flow graphs
|
||||
|
||||
|
|
@ -79,35 +79,19 @@ From the **Projects** page, you can manage flows within each of your projects:
|
|||
* **Delete a flow**: Locate the flow you want to delete, click <Icon name="Ellipsis" aria-hidden="true" /> **More**, and then select **Delete**.
|
||||
* **Serve flows as MCP tools**: See [Use Langflow as an MCP server](/mcp-server).
|
||||
|
||||
## Flow storage
|
||||
## Flow storage and logs
|
||||
|
||||
Flows and [flow logs](#flow-logs) are stored on local disk at the following default locations:
|
||||
By default, flows and [flow logs](/logging) are stored on local disk at the following default locations:
|
||||
|
||||
- **macOS Desktop**: `/Users/<username>/.langflow/cache`
|
||||
- **Windows Desktop**: `C:\Users\<username>\AppData\Roaming\com.Langflow\cache`
|
||||
- **OSS macOS/Windows/Linux/WSL (uv pip install)**: `<path_to_venv>/lib/python3.12/site-packages/langflow/cache`
|
||||
- **OSS macOS/Windows/Linux/WSL (git clone)**: `<path_to_clone>/src/backend/base/langflow/cache`
|
||||
|
||||
The flow storage location can be customized with the [`LANGFLOW_CONFIG_DIR`](/environment-variables#LANGFLOW_CONFIG_DIR) environment variable.
|
||||
|
||||
## Flow logs
|
||||
|
||||
When viewing a flow in the **Workspace**, click **Logs** to examine logs for that flow and its components.
|
||||
|
||||

|
||||
|
||||
Langflow logs are stored in `.log` files in the same place as your flows.
|
||||
For filepaths, see [Flow storage](/concepts-flows#flow-storage).
|
||||
|
||||
The flow storage location can be customized with the [`LANGFLOW_CONFIG_DIR`](/environment-variables#LANGFLOW_CONFIG_DIR) environment variable:
|
||||
|
||||
1. Add `LANGFLOW_LOG_FILE=path/to/logfile.log` in your `.env` file.
|
||||
|
||||
An example `.env` file is available in the [Langflow repository](https://github.com/langflow-ai/langflow/blob/main/.env.example).
|
||||
|
||||
2. Start Langflow with the values from your `.env` file by running `uv run langflow run --env-file .env`.
|
||||
The flow storage location can be customized with the [`LANGFLOW_CONFIG_DIR`](/environment-variables#LANGFLOW_CONFIG_DIR) environment variable, and the flow log storage location can be customized with the [`LANGFLOW_LOG_FILE`](/environment-variables#LANGFLOW_LOG_FILE) environment variable.
|
||||
|
||||
## See also
|
||||
|
||||
* [Share and embed flows](/concepts-publish)
|
||||
* [Import and export flows](/concepts-flows-import)
|
||||
* [Import and export flows](/concepts-flows-import)
|
||||
* [Langflow environment variables](/environment-variables)
|
||||
|
|
@ -1,23 +1,44 @@
|
|||
---
|
||||
title: Use the Playground
|
||||
title: Test flows in the Playground
|
||||
slug: /concepts-playground
|
||||
---
|
||||
|
||||
import Tabs from '@theme/Tabs';
|
||||
import TabItem from '@theme/TabItem';
|
||||
import Icon from "@site/src/components/icon";
|
||||
|
||||
<!-- TODO: Align and minimize duplications of playground content on the /concepts-overview, /about-langflow, and other pages -->
|
||||
Langflow's **Playground** is a dynamic interface you can use to test your LLM-based flows in real-time.
|
||||
|
||||
The **Playground** is a dynamic interface designed for real-time interaction with LLMs, allowing users to chat, access memories, and monitor inputs and outputs. Here, users can directly prototype their models, making adjustments and observing different outcomes.
|
||||
You can test how a flow responds to different inputs, review and modify memories, and monitor flow output and logic.
|
||||
For example, you can make sure agentic flows use the appropriate tools to respond to different inputs.
|
||||
|
||||
As long as you have a [Chat Input](/components-io) component in your flow, you can run the flow in the **Playground** test environment.
|
||||
The **Playground** allows you to quickly iterate over your flow's logic and behavior, making it easier to prototype and refine your applications.
|
||||
|
||||
## Run a flow in the Playground
|
||||
|
||||
To run a flow in the **Playground**, open the flow, and then click **Playground**.
|
||||
To run a flow in the **Playground**, open the flow, and then click <Icon name="Play" aria-hidden="true"/> **Playground**.
|
||||
Then, if your flow has a [**Chat Input** component](/components-io), enter a prompt or [use voice mode](/concepts-voice-mode) to trigger the flow and start a chat session.
|
||||
|
||||
:::tip
|
||||
If there is no message input field in the **Playground**, make sure your flow has a **Chat Input** component that is connected, directly or indirectly, to the **Input** port of a **Language Model** or **Agent** component.
|
||||
|
||||
Because the **Playground** is designed for flows that use an LLM in a query-and-response format, such as chatbots and agents, a flow must have **Chat Input**, **Language Model**/**Agent**, and **Chat Output** components to be fully supported by the **Playground**'s chat interface
|
||||
|
||||
For flows that require another type of input, such as a webhook event, file upload, or text input, you can [use the Langflow API to trigger the flow](/api-flows-run), and then open the **Playground** to review the LLM activity for the flow run, if applicable.
|
||||
:::
|
||||
|
||||

|
||||
|
||||
If your flow has **Chat Input**, **Language Model**, and **Chat Output** components, you can chat with the LLM in the **Playground**.
|
||||
<details>
|
||||
<summary>Playground mechanics</summary>
|
||||
|
||||
When you run a flow in the **Playground**, Langflow calls the `/build/$FLOW_ID/flow` endpoint in [chat.py](https://github.com/langflow-ai/langflow/blob/main/src/backend/base/langflow/api/v1/chat.py#L143). This call retrieves the flow data, builds a graph, and executes the graph. As each component (or node) is executed, the `build_vertex` function calls `build_and_run`, which may call the individual components' `def_build` method, if it exists. If a component doesn't have a `def_build` function, the build still returns a component.
|
||||
|
||||
The `build` function allows components to execute logic at runtime. For example, the [**Recursive Character Text Splitter** component](https://github.com/langflow-ai/langflow/blob/main/src/backend/base/langflow/components/langchain_utilities/recursive_character.py) is a child of the `LCTextSplitterComponent` class. When text needs to be processed, the parent class's `build` method is called, which creates a `RecursiveCharacterTextSplitter` object and uses it to split the text according to the defined parameters. The split text is then passed on to the next component. This all occurs when the component is built.
|
||||
|
||||
</details>
|
||||
|
||||
### Review Agent logic
|
||||
|
||||
If your flow has an **Agent** component, the **Playground** prints the tools used by the agent and the output from each tool.
|
||||
This helps you monitor the agent's tool use and understand the logic behind the agent's responses.
|
||||
|
|
@ -25,93 +46,100 @@ For example, the following agent used a connected `fetch_content` tool to perfor
|
|||
|
||||

|
||||
|
||||
When you run a flow in the **Playground**, Langflow calls the `/build/{flow_id}/flow` endpoint in [chat.py](https://github.com/langflow-ai/langflow/blob/main/src/backend/base/langflow/api/v1/chat.py#L143). This call retrieves the flow data, builds a graph, and executes the graph. As each component (or node) is executed, the `build_vertex` function calls `build_and_run`, which may call the individual components' `def_build` method, if it exists. If a component doesn't have a `def_build` function, the build still returns a component.
|
||||
### View chat history {#view-chat-history}
|
||||
|
||||
The `build` function allows components to execute logic at runtime. For example, the [Recursive character text splitter](https://github.com/langflow-ai/langflow/blob/main/src/backend/base/langflow/components/langchain_utilities/recursive_character.py) is a child of the `LCTextSplitterComponent` class. When text needs to be processed, the parent class's `build` method is called, which creates a `RecursiveCharacterTextSplitter` object and uses it to split the text according to the defined parameters. The split text is then passed on to the next component. This all occurs when the component is built.
|
||||
In the **Playground**, you can view message logs for each of your flow's chat sessions, including timestamps, content, and senders.
|
||||
|
||||
## View Playground messages by session ID
|
||||
|
||||
When you send a message from the **Playground** interface, the interactions are stored in the **Message Logs** by `session_id`.
|
||||
A single flow can have multiple chats, and different flows can share the same chat. Each chat session has a different `session_id`.
|
||||
|
||||
To view messages by `session_id` within the Playground, click the <Icon name="Ellipsis" aria-hidden="true"/> **Options** menu of any chat session, and then select **Message Logs**.
|
||||
In the **Playground** sidebar, find the chat session you want to review, click <Icon name="Ellipsis" aria-hidden="true"/> **Options**, and then select **Message Logs**.
|
||||
|
||||

|
||||
|
||||
Individual messages in chat memory can be edited or deleted. Modifying these memories influences the behavior of the chatbot responses.
|
||||
Message logs break apart the [`Message` data](/data-types#message) for each chat message.
|
||||
Click any cell in the message logs to view the full contents of that cell.
|
||||
|
||||
To learn more about managing sessions in Langflow, see [Session ID](/session-id).
|
||||
### Modify memories in the Playground
|
||||
|
||||
To learn more about how chat memory is stored in Langflow, see [Memory components](/memory).
|
||||
To help debug and test your flows, you can edit or delete individual messages in [message logs](#view-chat-history).
|
||||
For example, you might want to delete messages that you sent while testing a component that is no longer part of your flow.
|
||||
|
||||
## Use custom session IDs for multiple user interactions
|
||||
You can also delete entire chat sessions from the sidebar: click <Icon name="Ellipsis" aria-hidden="true"/> **Options**, and then select **Delete**.
|
||||
|
||||
`session_id` values are used to track user interactions in a flow.
|
||||
By default, if the `session_id` value is empty, it is set to the same value as the `flow_id`. In this case, every chat call uses the same `session_id`, and you effectively have one chat session.
|
||||
Modifying memories influences the behavior of the chatbot responses if you continue the chat session or if you preserve memories over multiple chat sessions.
|
||||
|
||||
The `session_id` value can be configured in the **Controls** of the **Chat Input** and **Chat Output** components.
|
||||
**Editing message logs edits Langflow's internal `messages` table, which is the default chat memory storage.**
|
||||
For more information about managing sessions and chat memory in Langflow, see [Use custom session IDs](#session-ids) and [Memory management options](/memory).
|
||||
|
||||
To have more than one session in a single flow, pass a specific session ID to a flow with the `session_id` parameter in the URL. All the components in the flow will automatically use this `session_id` value.
|
||||
## Set custom session IDs {#session-ids}
|
||||
|
||||
Chat sessions are identified by session ID (`session_id`).
|
||||
|
||||
To post a message to a flow with a specific Session ID with curl, enter the following command.
|
||||
Replace `LANGFLOW_SERVER_ADDRESS`, `FLOW_ID`, and `LANGFLOW_API_KEY` with the values from your Langflow deployment.
|
||||
The default session ID is the flow ID, which means that all chat messages for a flow are stored under the same session ID as one enormous chat session.
|
||||
|
||||
If you need to preserve chat context over multiple flow runs or differentiate chat sessions when debugging flows, you can set a custom `session_id`.
|
||||
|
||||
Custom session IDs are helpful for multiple reasons:
|
||||
|
||||
* Separate chat sessions in situations where one flow has multiple chat sessions, such as a chatbot that can have multiple simultaneous user interactions.
|
||||
* Preserve memory when continuing a chat session across multiple flow runs or when passing context from one flow to another.
|
||||
* Differentiate activity from multiple users within the same flow.
|
||||
* Identify your own chat sessions when debugging and testing flows.
|
||||
|
||||
You can set custom session IDs in the visual editor and programmatically.
|
||||
|
||||
<Tabs>
|
||||
<TabItem value="visual" label="Visual editor" default>
|
||||
|
||||
In your [input and output components](/components-io), use the **Session ID** field:
|
||||
|
||||
1. Click the component where you want to set a custom session ID.
|
||||
2. In the [component's header menu](/concepts-components#component-menus), click <Icon name="SlidersHorizontal" aria-hidden="true"/> **Controls**.
|
||||
3. Enable **Session ID**.
|
||||
4. Click **Close**.
|
||||
5. Enter a custom session ID.
|
||||
If the field is empty, the flow uses the default session ID.
|
||||
6. Open the **Playground** to start a chat under your custom session ID.
|
||||
|
||||
Make sure to change the **Session ID** when you want to start a new chat session or continue an earlier chat session with a different session ID.
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="api" label="Langflow API">
|
||||
|
||||
When you trigger a flow with the Langflow API, include the `session_id` parameter in the request payload.
|
||||
For example:
|
||||
|
||||
```bash
|
||||
curl -X POST "http://LANGFLOW_SERVER_ADDRESS/api/v1/run/FLOW_ID" \
|
||||
-H "Content-Type: application/json" \
|
||||
-H "x-api-key: LANGFLOW_API_KEY" \
|
||||
-d '{
|
||||
"session_id": "CUSTOM_SESSION_VALUE",
|
||||
"input_value": "message",
|
||||
"input_type": "chat",
|
||||
"output_type": "chat"
|
||||
}'
|
||||
```
|
||||
|
||||
Check your flow's **Playground**. In addition to the messages stored for the default session, a new session is started with your custom session ID.
|
||||
|
||||
## Work with images in the Playground
|
||||
|
||||
The Playground supports handling images in base64 format, allowing you to work with image data directly in your flows.
|
||||
|
||||
The Playground accepts the following image formats:
|
||||
|
||||
* PNG
|
||||
* JPG/JPEG
|
||||
* GIF
|
||||
* BMP
|
||||
* WebP
|
||||
|
||||
You can work with base64 images in the Playground in several ways:
|
||||
|
||||
* **Direct Upload**: Use the image upload button in the chat interface to upload images directly.
|
||||
* **Drag and Drop**: Drag and drop image files into the chat interface.
|
||||
* **Programmatic Input**: Send base64-encoded images through the API.
|
||||
|
||||
This example sends a base64-encoded image to the Playground using curl:
|
||||
Replace `LANGFLOW_SERVER_ADDRESS`, `FLOW_ID`, and `LANGFLOW_API_KEY` with the values from your Langflow deployment.
|
||||
```bash
|
||||
curl -X POST "http://localhost:7860/api/v1/run/FLOW_ID" \
|
||||
curl -X POST "http://$LANGFLOW_SERVER_ADDRESS/api/v1/run/$FLOW_ID" \
|
||||
-H "Content-Type: application/json" \
|
||||
-H "x-api-key: LANGFLOW_API_KEY" \
|
||||
-H "x-api-key: $LANGFLOW_API_KEY" \
|
||||
-d '{
|
||||
"session_id": "custom_session_123",
|
||||
"input_value": "What is in this image?",
|
||||
"session_id": "CUSTOM_SESSION_ID",
|
||||
"input_value": "message",
|
||||
"input_type": "chat",
|
||||
"output_type": "chat",
|
||||
"files": ["data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAA..."]
|
||||
"output_type": "chat"
|
||||
}'
|
||||
```
|
||||
|
||||
The image is displayed in the chat interface and can be processed by your flow components.
|
||||
This command starts a new chat sessions with the specified `session_id` or it retrieves an existing session with that ID, if one exists.
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
:::tip
|
||||
In a production environment, consider using a variable for the session ID rather than a hardcoded value.
|
||||
|
||||
For example, if you want to preserve context for authenticated users, user ID could be a useful variable for the session ID.
|
||||
Alternatively, if you want every chat to be unique, you might want to automatically generate a UUID for each session ID.
|
||||
:::
|
||||
|
||||
For more information, see [Use session ID to manage communication between components](/session-id).
|
||||
|
||||
## Share a flow's Playground
|
||||
|
||||
:::important
|
||||
The **Shareable Playground** is for testing purposes only, and it isn't available for Langflow Desktop.
|
||||
The **Shareable Playground** is for testing purposes only.
|
||||
The **Playground** isn't meant for embedding flows in applications. For information about running flows in applications or websites, see [Trigger flows with the Langflow API](/concepts-publish).
|
||||
|
||||
The **Playground** isn't meant for embedding flows in applications. For information about running flows in applications or websites, see [Run flows](/concepts-publish).
|
||||
The **Shareable Playground** isn't available in Langflow Desktop.
|
||||
:::
|
||||
|
||||
The **Shareable Playground** option exposes the **Playground** for a single flow at the `/public_flow/$FLOW_ID` endpoint.
|
||||
|
|
@ -129,5 +157,7 @@ This window's URL is the flow's **Shareable Playground** address, such as `https
|
|||
|
||||
## See also
|
||||
|
||||
- [Run flows](/concepts-publish)
|
||||
- [Upload images](/concepts-file-management#upload-images)
|
||||
- [Use voice mode](/concepts-voice-mode)
|
||||
- [Trigger flows with the Langflow API](/concepts-publish)
|
||||
- [Session ID](/session-id)
|
||||
|
|
@ -1,5 +1,5 @@
|
|||
---
|
||||
title: Run flows
|
||||
title: Trigger flows with the Langflow API
|
||||
slug: /concepts-publish
|
||||
---
|
||||
|
||||
|
|
@ -14,8 +14,7 @@ Langflow provides several ways to run flows from external applications:
|
|||
* [Add an embedded chat widget to a website](#embedded-chat-widget)
|
||||
* [Serve flows through a Langflow MCP server](#serve-flows-through-a-langflow-mcp-server)
|
||||
|
||||
Although you can use these options with an isolated, local Langflow instance, they are typically more valuable when you have [deployed a Langflow server](/deployment-overview) or packaged Langflow as a dependency of an application.
|
||||
For package dependencies, see [Develop an application with Langflow](/develop-application) and [Package a flow as a Docker image](/deployment-docker#package-your-flow-as-a-docker-image).
|
||||
Although you can use these options with an isolated, local Langflow instance, they are typically more valuable when you have [deployed a Langflow server](/deployment-overview) or [packaged Langflow as a dependency of an application](/develop-application).
|
||||
|
||||
## Use the Langflow API to run flows {#api-access}
|
||||
|
||||
|
|
@ -531,8 +530,6 @@ For more information, see [Use Langflow as an MCP server](/mcp-server) and [Use
|
|||
|
||||
## See also
|
||||
|
||||
* [Develop an application with Langflow](/develop-application)
|
||||
* [Langflow deployment overview](/deployment-overview)
|
||||
* [Import and export flows](/concepts-flows-import)
|
||||
* [Files endpoints](/api-files)
|
||||
* [Use the Playground](/concepts-playground)
|
||||
|
|
@ -144,13 +144,30 @@ For information about the underlying Python classes that produce `Embeddings`, s
|
|||
|
||||
## LanguageModel
|
||||
|
||||
`LanguageModel` output is a specific type of output that can be produced by **Language Model** components.
|
||||
When enabled, the component's output port changes from a **Message** port to a **Language Model** port <Icon name="Circle" size="16" aria-label="Fuchsia language model port" style={{ color: '#c026d3', fill: '#c026d3' }} />
|
||||
For more information, see [Use the LanguageModel output](/components-models#use-the-languagemodel-output).
|
||||
The `LanguageModel` type is a specific data type that can be produced by language model components and accepted by components that use an LLM.
|
||||
|
||||
When you change a language model component's output type from **Model Response** to **Language Model**, the component's output port changes from a **Message** port to a **Language Model** port <Icon name="Circle" size="16" aria-label="Fuchsia language model port" style={{ color: '#c026d3', fill: '#c026d3' }} />.
|
||||
|
||||
Then, you connect the outgoing **Language Model** port to a **Language Model** input port on a compatible component, such as a **Smart Function** component.
|
||||
|
||||
For more information about using language model components in flows and toggling `LanguageModel` output, see [**Language Model** components](/components-models#language-model-output-types).
|
||||
|
||||
<details>
|
||||
<summary>LanguageModel is an instance of LangChain ChatModel</summary>
|
||||
|
||||
Because Langflow is built on LangChain, `LanguageModel` is actually an instance of a [LangChain chat model](https://python.langchain.com/docs/concepts/chat_models/) that uses the configuration parameters set in the originating component.
|
||||
|
||||
Often, components produce an instance of an [integrated chat model](https://python.langchain.com/docs/integrations/chat/) that is designed to support the specific model provider, such as [`ChatOpenAI`](https://python.langchain.com/docs/integrations/chat/openai/) or [`ChatAnthropic`](https://python.langchain.com/docs/integrations/chat/anthropic/).
|
||||
|
||||
You can inspect the [component code](/concepts-components#component-code) to see the specific `Chat` instance it produces.
|
||||
|
||||
</details>
|
||||
|
||||
## Memory
|
||||
|
||||
**Memory** ports <Icon name="Circle" size="16" aria-label="Orange memory port" style={{ color: '#f97316', fill: '#f97316' }} /> are available for components that store or retrieve chat memory.
|
||||
**Memory** ports <Icon name="Circle" size="16" aria-label="Orange memory port" style={{ color: '#f97316', fill: '#f97316' }} /> are used to integrate a **Message History** component with external chat memory storage.
|
||||
|
||||
For more information, see the [**Message History** component](/components-helpers#message-history).
|
||||
|
||||
## Message
|
||||
|
||||
|
|
@ -208,11 +225,11 @@ The strictness depends on the component.
|
|||
|
||||
### Message data in Input/Output components
|
||||
|
||||
In flows with [**Chat Input/Output** components](/components-io), `Message` data provides a consistent structure for chat interactions, and it is ideal for chatbots, conversational analysis, and other use cases based on a dialog with an LLM or agent.
|
||||
In flows with [**Chat Input/Output** components](/components-io#chat-io), `Message` data provides a consistent structure for chat interactions, and it is ideal for chatbots, conversational analysis, and other use cases based on a dialog with an LLM or agent.
|
||||
In these flows, the **Playground** chat interface prints only the `Message` attributes that are relevant to the conversation, such as `text`, `files`, and error messages from `content_blocks`.
|
||||
To see all `Message` attributes, inspect the message logs in the **Playground**.
|
||||
|
||||
In flows with [**Text Input/Output** components](/components-io), `Message` data is used to pass simple text strings without the chat-related metadata.
|
||||
In flows with [**Text Input/Output** components](/components-io#text-io), `Message` data is used to pass simple text strings without the chat-related metadata.
|
||||
These components handle `Message` data as independent text strings, not as part of an ongoing conversation.
|
||||
For this reason, a flow with only **Text Input/Output** components isn't compatible with the **Playground**.
|
||||
For more information, see [Input/Output components](/components-io).
|
||||
|
|
|
|||
|
|
@ -1,53 +1,61 @@
|
|||
---
|
||||
title: Develop an application in Langflow
|
||||
title: Containerize a Langflow application
|
||||
slug: /develop-application
|
||||
---
|
||||
|
||||
Follow this guide to learn how to build an application using Langflow.
|
||||
You'll learn how to set up a project directory, manage dependencies, configure environment variables, and package your Langflow application in a Docker image.
|
||||
Designing flows in the visual editor is only the first step in building an application that uses Langflow.
|
||||
|
||||
To deploy your application to Docker or Kubernetes, see [Deployment](/deployment-docker).
|
||||
Once you have a functional flow, you can use that flow in a larger application, such as a website or mobile app.
|
||||
Because Langflow is both an IDE and a runtime, you can use Langflow to build and test your flows locally, and then package and serve your flows in a production environment.
|
||||
|
||||
## Create a project directory
|
||||
This guide introduces application development with Langflow from project setup through packaging and deployment.
|
||||
This documentation doesn't explain how to write a complete application; it only describes how to include Langflow in the context of a larger application.
|
||||
|
||||
Create a project directory similar to this one.
|
||||
## Project structure
|
||||
|
||||
The following example describes the project directory structure for a minimal Langflow application:
|
||||
|
||||
```text
|
||||
LANGFLOW-APPLICATION/
|
||||
├── docker.env
|
||||
├── Dockerfile
|
||||
├── flows/
|
||||
│ ├── flow1.json
|
||||
│ └── flow2.json
|
||||
├── langflow-config-dir/
|
||||
├── docker.env
|
||||
├── Dockerfile
|
||||
├── README.md
|
||||
```
|
||||
|
||||
The `/flows` folder holds the flows you want to host.
|
||||
This project directory contains the following:
|
||||
|
||||
The `langflow-config-dir` is referenced in the Dockerfile as the location for Langflow's configuration files, database, and logs. For more information, see [Environment variables](/environment-variables).
|
||||
* [`docker.env`](#docker-env): This file is copied to the Docker image as a `.env` file in the container root.
|
||||
* [`Dockerfile`](#dockerfile): This file controls how your Langflow image is built.
|
||||
* [`/flows`](#flows): This folder holds the flows you want to host, which are the flows that your application uses.
|
||||
* `/langflow-config-dir`: This folder is referenced in the Dockerfile as the location for your Langflow deployment's configuration files, database, and logs.
|
||||
* `README.md`: This is a typical README file for your application's documentation.
|
||||
|
||||
The `docker.env` file is copied to the Docker image as a `.env` file in the container root. This file controls Langflow's behavior, holds secrets, and configures runtime settings like authentication, database storage, API keys, and server configurations.
|
||||
|
||||
The `Dockerfile` controls how your image is built. This file copies your flows and `docker.env` files to your image.
|
||||
This is a minimal example of a Langflow application project directory.
|
||||
Your application might have additional files and folders, such as a `/components` folder for custom components, or a `pyproject.toml` file for additional dependencies.
|
||||
|
||||
### Package management
|
||||
|
||||
The base Docker image includes the Langflow core dependencies by using `langflowai/langflow:latest` as the parent image.
|
||||
The base Langflow Docker image includes the Langflow core dependencies because it uses `langflowai/langflow:latest` as the parent image.
|
||||
|
||||
If your application requires additional dependencies, create a `pyproject.toml` file and add the dependencies to the file. For more information, see [Install custom dependencies](/install-custom-dependencies).
|
||||
If your application requires additional dependencies, create a [`pyproject.toml`](https://packaging.python.org/en/latest/guides/writing-pyproject-toml) file for the additional dependencies.
|
||||
For more information, see [Install custom dependencies](/install-custom-dependencies).
|
||||
|
||||
To deploy the application with the additional dependencies to Docker, copy the `pyproject.toml` and `uv.lock` files to the Docker image by adding the following to the Dockerfile.
|
||||
To deploy an application with additional dependencies to Docker, you must copy the `pyproject.toml` and `uv.lock` files to the Docker image.
|
||||
To do this, add the following to your Langflow application's Dockerfile:
|
||||
|
||||
```text
|
||||
COPY pyproject.toml uv.lock /app/
|
||||
```
|
||||
|
||||
## Environment variables
|
||||
### Environment variables {#docker-env}
|
||||
|
||||
The `docker.env` file is a `.env` file loaded into your Docker image.
|
||||
|
||||
The following example `docker.env` file defines auto-login behavior and which port to expose. Your environment may vary. For more information, see [Environment variables](/environment-variables).
|
||||
It contains environment variables that control Langflow's behavior, such as authentication, database storage, API keys, and server configurations.
|
||||
For example:
|
||||
|
||||
```text
|
||||
LANGFLOW_AUTO_LOGIN=true
|
||||
|
|
@ -56,110 +64,175 @@ LANGFLOW_BASE_URL=http://0.0.0.0:7860
|
|||
OPENAI_API_KEY=sk-...
|
||||
```
|
||||
|
||||
This example uses Langflow's default [SQLite](https://www.sqlite.org/) database for storage, and configures no authentication.
|
||||
The specific values you include depend on your application's needs and how you want to configure Langflow.
|
||||
For more information, see [Langflow environment variables](/environment-variables) and [Global variables](/configuration-global-variables).
|
||||
|
||||
To modify Langflow's default memory behavior, see [Memory](/memory).
|
||||
You can also set environment variables in the Dockerfile.
|
||||
However, if you set an environment variable in both `docker.env` and the Dockerfile, Langflow uses the value set in `docker.env`.
|
||||
|
||||
To add authentication to your server, see [Authentication](/configuration-authentication).
|
||||
### Secrets
|
||||
|
||||
## Add flows and components
|
||||
For simplicity, the examples in the Langflow documentation might use direct references to API keys and other sensitive values.
|
||||
In your own applications, you should always follow industry best practices for managing secrets, such as using environment variables or secret management tools.
|
||||
|
||||
Add your flow's `.JSON` files to the `/flows` folder.
|
||||
For information about generating authentication keys and managing secrets in Langflow, see [Authentication](/configuration-authentication).
|
||||
|
||||
To export your flows from Langflow, see [Import and export flows](/concepts-flows-import).
|
||||
### Storage
|
||||
|
||||
Optionally, add any custom components to a `/components` folder, and specify the path in your `docker.env`.
|
||||
By default, Langflow uses an [SQLite](https://www.sqlite.org/) database for storage.
|
||||
If you prefer to use PostgreSQL, see [Configure an external PostgreSQL database](/configuration-custom-database).
|
||||
|
||||
## Package your Langflow project in a Docker image
|
||||
For more information about storage, including cache and memory, see [Memory management options](/memory).
|
||||
|
||||
1. Add the following commands to your Dockerfile.
|
||||
### Flows {#flows}
|
||||
|
||||
Your local Langflow instance might have many flows for different applications.
|
||||
When you package Langflow as a dependency of an application, you only want to include the flows your application uses.
|
||||
|
||||
1. [Export flows](/concepts-flows-import) that are relevant to your application.
|
||||
|
||||
If you have chained flows (flows that trigger other flows), make sure you export _all_ necessary flows.
|
||||
|
||||
2. Add the exported Langflow JSON files to the `/flows` folder in your project directory.
|
||||
|
||||
### Components
|
||||
|
||||
The core components and bundles that you see in the Langflow visual editors are automatically included in the base Langflow Docker image.
|
||||
|
||||
If you have any [custom components](/components-custom-components) that you created for your application, you must include these components in your project directory:
|
||||
|
||||
1. Create a `/components` folder in your project directory.
|
||||
2. Add your custom component files to the `/components` folder.
|
||||
3. Specify the path to `/components` in your `docker.env`.
|
||||
|
||||
## Langflow Dockerfile {#dockerfile}
|
||||
|
||||
The Dockerfile determines how your Langflow image is built, including the dependencies, flows, components, and configuration files.
|
||||
|
||||
At minimum, you need to specify the base Langflow image, create the necessary folders in the container, copy folders and files to the container, and provide a startup command.
|
||||
|
||||
```dockerfile
|
||||
# Use the latest version of langflow
|
||||
# Use the latest version of the base Langflow image
|
||||
FROM langflowai/langflow:latest
|
||||
|
||||
# Create accessible folders and set the working directory in the container
|
||||
# Create folders and set the working directory in the container
|
||||
RUN mkdir /app/flows
|
||||
RUN mkdir /app/langflow-config-dir
|
||||
WORKDIR /app
|
||||
|
||||
# Copy the flows, optional components, and langflow-config-dir folders to the container
|
||||
# Copy flows, langflow-config-dir, and docker.env to the container
|
||||
COPY flows /app/flows
|
||||
COPY components /app/components
|
||||
COPY langflow-config-dir /app/langflow-config-dir
|
||||
|
||||
# copy docker.env file
|
||||
COPY docker.env /app/.env
|
||||
|
||||
# Set environment variables
|
||||
# Optional: Copy custom components to the container
|
||||
COPY components /app/components
|
||||
|
||||
# Optional: Use custom dependencies
|
||||
COPY pyproject.toml uv.lock /app/
|
||||
|
||||
# Set environment variables if not set in docker.env
|
||||
ENV PYTHONPATH=/app
|
||||
ENV LANGFLOW_LOAD_FLOWS_PATH=/app/flows
|
||||
ENV LANGFLOW_CONFIG_DIR=/app/langflow-config-dir
|
||||
ENV LANGFLOW_COMPONENTS_PATH=/app/components
|
||||
ENV LANGFLOW_LOG_ENV=container
|
||||
|
||||
# Command to run the server
|
||||
# Command to run the Langflow server on port 7860
|
||||
EXPOSE 7860
|
||||
CMD ["langflow", "run", "--backend-only", "--env-file","/app/.env","--host", "0.0.0.0", "--port", "7860"]
|
||||
```
|
||||
|
||||
The environment variables set in the Dockerfile specify resource paths and allow Langflow to access them. Values from `docker.env` override the values set in the Dockerfile. Additionally, logging behavior is set here with `ENV LANGFLOW_LOG_ENV=container` for serialized JSON to `stdout`, for tracking your application's behavior in a containerized environment. For more information on configuring logs, see [Logging](/logging).
|
||||
The environment variables set directly in this Dockerfile specify resource paths for Langflow.
|
||||
If these variables are also set in `docker.env`, the values in `docker.env` override the values set in the Dockerfile.
|
||||
|
||||
:::note
|
||||
Optionally, remove the `--backend-only` flag from the startup command to start Langflow with the frontend enabled.
|
||||
For more on `--backend-only` mode and the Langflow Docker image, see [Docker](/deployment-docker).
|
||||
:::
|
||||
In this example, `ENV LANGFLOW_LOG_ENV=container` sets the logging behavior for serialized JSON to `stdout` to track the application's behavior in a containerized environment. For more information, see [Logging](/logging).
|
||||
|
||||
2. Save your Dockerfile.
|
||||
3. Build the Docker image:
|
||||
```bash
|
||||
docker build -t langflow-pokedex:1.2.0 .
|
||||
```
|
||||
4. Run the Docker container:
|
||||
```bash
|
||||
docker run -p 7860:7860 langflow-pokedex:1.2.0
|
||||
```
|
||||
### Backend-only mode
|
||||
|
||||
:::note
|
||||
For instructions on building and pushing your image to Docker Hub, see [Docker](/deployment-docker).
|
||||
:::
|
||||
The `--backend-only` flag in `CMD` starts Langflow in backend-only mode, which provides programmatic access only.
|
||||
This is recommended when running Langflow as a dependency of an application where you don't need access to the Langflow UI.
|
||||
|
||||
5. Confirm the server is serving your flows.
|
||||
Open a `.JSON` file in your `/flows` folder and find the file's `id` value. It's the first value in the flow document.
|
||||
If you want to serve the visual editor _and_ the Langflow backend, omit `--backend-only`.
|
||||
|
||||
```json
|
||||
"id": "e4167236-938f-4aca-845b-21de3f399858",
|
||||
```
|
||||
For more information, see [Deploy Langflow on Docker](/deployment-docker).
|
||||
|
||||
6. Add the file's `id` value as the `flow-id` to a POST request to the `/run` endpoint.
|
||||
## Test your Langflow Docker image
|
||||
|
||||
This command also uses a custom `session_id` value of `charizard_test_request`.
|
||||
By default, session IDs use the `flow-id` value.
|
||||
A custom session ID maintains a unique conversation thread, which keeps LLM contexts clean and can make debugging easier.
|
||||
For more information, see [Session ID](/session-id).
|
||||
Build and run your Langflow Docker image to test it.
|
||||
|
||||
```bash
|
||||
curl --request POST \
|
||||
--url 'http://localhost:7860/api/v1/run/e4167236-938f-4aca-845b-21de3f399858?stream=false' \
|
||||
--header 'Content-Type: application/json' \
|
||||
--data '{
|
||||
"input_value": "Tell me about Charizard please",
|
||||
"output_type": "chat",
|
||||
"input_type": "chat",
|
||||
"session_id": "charizard_test_request"
|
||||
}'
|
||||
```
|
||||
This example runs the container locally.
|
||||
For information about publishing your image on Docker Hub and running a Langflow container remotely, see [Deploy to Docker Hub and Kubernetes](#deploy-docker).
|
||||
|
||||
If the flow streams the result back to you, your flow is being served, and can be consumed from a front-end application by submitting POST requests to this endpoint.
|
||||
1. Build the Docker image:
|
||||
|
||||
To trigger your application from an external event, see [Webhook](/webhook).
|
||||
```bash
|
||||
docker build -t langflow-pokedex:1.2.0 .
|
||||
```
|
||||
|
||||
:::note
|
||||
The test application returns a large amount of text, so the example command used `?stream=true`. If you prefer, set `?stream=false` to use batching. For more information, see the [/run endpoint](/api-flows-run#run-flow).
|
||||
:::
|
||||
2. Run the Docker container to start your Langflow server:
|
||||
|
||||
## Deploy to Docker Hub and Kubernetes
|
||||
```bash
|
||||
docker run -p 7860:7860 langflow-pokedex:1.2.0
|
||||
```
|
||||
|
||||
For instructions on building and pushing your image to Docker Hub, see [Docker](/deployment-docker).
|
||||
3. To confirm that the container is serving your flows as expected, use the Langflow API to run a flow:
|
||||
|
||||
To deploy your application to Kubernetes, see [Deploy the Langflow production environment to Kubernetes](/deployment-kubernetes-prod).
|
||||
1. Open one of the JSON files in your application's `/flows` folder, and then find the flow's `id` in the [additional metadata and project information](/concepts-flows-import#additional-metadata-and-project-information).
|
||||
|
||||
There are many `id` values; make sure you get the ID for the entire flow, not the ID for an individual component.
|
||||
If your flow is complex, try searching for the flow's name, which is typically near the flow's `id`.
|
||||
|
||||
```json
|
||||
"name": "Basic Prompting",
|
||||
"description": "Perform basic prompting with an OpenAI model.",
|
||||
"id": "e4167236-938f-4aca-845b-21de3f399858",
|
||||
```
|
||||
|
||||
2. Send a POST request to the [`/v1/run/$FLOW_ID`](/api-flows-run#run-flow) endpoint using the flow ID from the previous step .
|
||||
|
||||
The following example runs a simple LLM chat flow that responds to a chat input string.
|
||||
If necessary, modify the payload for your flow.
|
||||
For example, if your flow doesn't have a **Chat input** component, you must modify the payload to provide the expected input for your flow.
|
||||
|
||||
```bash
|
||||
curl --request POST \
|
||||
--url 'http://localhost:7860/api/v1/run/e4167236-938f-4aca-845b-21de3f399858?stream=true' \
|
||||
--header 'Content-Type: application/json' \
|
||||
--data '{
|
||||
"input_value": "Tell me about Charizard.",
|
||||
"output_type": "chat",
|
||||
"input_type": "chat",
|
||||
"session_id": "charizard_test_request"
|
||||
}'
|
||||
```
|
||||
<details>
|
||||
<summary>About this example</summary>
|
||||
|
||||
This command runs the Pokédex template flow.
|
||||
It provides chat input about a specific Pokémon, uses an optional custom `session_id`, and enables response streaming with `?stream=true`.
|
||||
|
||||
The default [session ID](/session-id) is the flow ID.
|
||||
Custom session IDs can help isolate unique conversation threads to keep the LLM's context clean, and they can help identify specific conversations in flow logs to make debugging easier.
|
||||
|
||||
This command uses response streaming because the Pokédex flow can return a large amount of text.
|
||||
To use batching, set `?stream=false`.
|
||||
|
||||
</details>
|
||||
|
||||
3. Verify that the request succeeds and the response is valid, depending on the specific flow you ran.
|
||||
|
||||
This confirms that your Langflow Docker image is correctly configured and this flow is accessible through the Langflow API server that is hosted on the container.
|
||||
When you build and test your entire application stack, your front-end application can use Langflow API requests to trigger the flows served by your Langflow container in the same way you manually tested the flow in the previous step.
|
||||
|
||||
This example triggered a flow by sending chat input to the `/v1/run/$FLOW_ID` endpoint.
|
||||
For more examples of flow triggers, see [Trigger flows with webhooks](/webhook) and the tutorial to [Create a chatbot that can ingest files](/chat-with-files).
|
||||
|
||||
## Deploy to Docker Hub and Kubernetes {#deploy-docker}
|
||||
|
||||
When you're ready to share your application with the world, you need to serve Langflow in a production environment.
|
||||
For more information about deploying Langflow, see the following:
|
||||
|
||||
* [Learn about Langflow deployments](/deployment-overview)
|
||||
* [Deploy Langflow on Docker](/deployment-docker)
|
||||
* [Deploy your application to Kubernetes](/deployment-kubernetes-prod)
|
||||
|
|
@ -1,19 +0,0 @@
|
|||
---
|
||||
title: About developing and configuring Langflow applications
|
||||
slug: /develop-overview
|
||||
---
|
||||
|
||||
The following pages provide information about how to develop and configure Langflow applications.
|
||||
|
||||
The [Develop an application in Langflow](/develop-application) guide walks you through packaging and serving a flow, from your local development environment to a containerized application.
|
||||
As you build your application, you will configure the following application behaviors. More detailed explanation is provided in the individual pages.
|
||||
|
||||
* [Custom Dependencies](/install-custom-dependencies) - Add and manage additional Python packages and external dependencies in your Langflow applications.
|
||||
|
||||
* [Memory and Storage](/memory) - Configure Langflow's storage and caching behavior.
|
||||
|
||||
* [Session Management](/session-id) - Use session ID to manage communication between components.
|
||||
|
||||
* [Logging](/logging) - Monitor and debug your Langflow applications.
|
||||
|
||||
* [Webhook](/webhook) - Trigger your flows with external requests.
|
||||
|
|
@ -7,30 +7,40 @@ import Icon from "@site/src/components/icon";
|
|||
|
||||
This page provides information about Langflow logs, including logs for individual flows and the Langflow application itself.
|
||||
|
||||
## Log options
|
||||
|
||||
Langflow uses the `loguru` library for logging.
|
||||
|
||||
The default `log_level` is `ERROR`. Other options are `DEBUG`, `INFO`, `WARNING`, and `CRITICAL`.
|
||||
The default logfile is named `langflow.log`.
|
||||
Langflow also produces logfiles for flows.
|
||||
|
||||
The default logfile is called `langflow.log`, and its location depends on your operating system.
|
||||
## Log storage
|
||||
|
||||
The default logfile storage location depends on your operating system:
|
||||
|
||||
- **macOS Desktop**:`/Users/<username>/.langflow/cache`
|
||||
- **Windows Desktop**:`C:\Users\<username>\AppData\Roaming\com.Langflow\cache`
|
||||
- **OSS macOS/Windows/Linux/WSL (uv pip install)**: `<path_to_venv>/lib/python3.12/site-packages/langflow/cache`
|
||||
- **OSS macOS/Windows/Linux/WSL (git clone)**: `<path_to_clone>/src/backend/base/langflow/cache`
|
||||
- **OSS macOS/Windows/Linux/WSL (`uv pip install`)**: `<path_to_venv>/lib/python3.12/site-packages/langflow/cache`
|
||||
- **OSS macOS/Windows/Linux/WSL (`git clone`)**: `<path_to_clone>/src/backend/base/langflow/cache`
|
||||
|
||||
The `LANGFLOW_LOG_ENV` controls log output and formatting. The `container` option outputs serialized JSON to stdout. The `container_csv` option outputs CSV-formatted plain text to stdout. The `default` (or not set) logging option outputs prettified output with [RichHandler](https://rich.readthedocs.io/en/stable/reference/logging.html).
|
||||
To customize log storage, see [Configure log options](#configure-log-options).
|
||||
|
||||
To modify Langflow's logging configuration, add them to your `.env` file and start Langflow.
|
||||
## Configure log options
|
||||
|
||||
```text
|
||||
LANGFLOW_LOG_LEVEL=ERROR
|
||||
LANGFLOW_LOG_FILE=path/to/logfile.log
|
||||
LANGFLOW_LOG_ENV=container
|
||||
```
|
||||
Use [Langflow environment variables](/environment-variables) to configure logging options in your Langflow `.env` file, and then start Langflow with `uv run langflow run --env-file .env`.
|
||||
|
||||
To start Langflow with the values from your .env file, start Langflow with `uv run langflow run --env-file .env`
|
||||
The following environment variables are available to configure logging:
|
||||
|
||||
* `LANGFLOW_LOG_LEVEL`: Sets the log level as one of `DEBUG`, `ERROR` (default), `INFO`, `WARNING`, and `CRITICAL`. For example, `LANGFLOW_LOG_LEVEL=DEBUG`.
|
||||
|
||||
* `LANGFLOW_LOG_FILE`: Sets the log file storage location if you want to use a non-default location.
|
||||
For example, `LANGFLOW_LOG_FILE=path/to/logfile.log`.
|
||||
|
||||
* `LANGFLOW_LOG_ENV`: Controls log output and formatting.
|
||||
|
||||
* `LANGFLOW_LOG_ENV=container`: Outputs serialized JSON to stdout.
|
||||
* `LANGFLOW_LOG_ENV=container_csv`: Outputs CSV-formatted plain text to stdout.
|
||||
* `LANGFLOW_LOG_ENV=default` or unset: Outputs prettified output with [RichHandler](https://rich.readthedocs.io/en/stable/reference/logging.html).
|
||||
|
||||
A complete example `.env` file is available in the [Langflow repository](https://github.com/langflow-ai/langflow/blob/main/.env.example).
|
||||
|
||||
## Flow and component logs
|
||||
|
||||
|
|
@ -64,10 +74,13 @@ For example, the following `Message` data could be the output from a **Chat Inpu
|
|||
In the case of Input/Output components, the original input might not be structured as a `Message` object.
|
||||
For example, a **Language Model** component might pass a raw text response to a **Chat Output** component that is then transformed into a `Message` object.
|
||||
|
||||
You can find `.log` files for flows at your Langflow installation's log storage location.
|
||||
For filepaths, see [Log storage](#log-storage).
|
||||
|
||||
### View chat logs
|
||||
|
||||
In the **Playground**, you can inspect the chat history for each chat session.
|
||||
For more information, see [Use the Playground](/concepts-playground).
|
||||
For more information, see [View chat history](/concepts-playground#view-chat-history).
|
||||
|
||||
### View output from a single component
|
||||
|
||||
|
|
|
|||
|
|
@ -6,53 +6,47 @@ slug: /memory
|
|||
Langflow provides flexible memory management options for storage and retrieval of data relevant to your flows and your Langflow server.
|
||||
This includes essential Langflow database tables, file management, and caching, as well as chat memory.
|
||||
|
||||
## Storage options and paths
|
||||
|
||||
Langflow supports both local memory and external memory options.
|
||||
|
||||
## Local Langflow database tables
|
||||
|
||||
The default storage option in Langflow is a [SQLite](https://www.sqlite.org/) database stored in your system's cache directory:
|
||||
Langflow's default storage option is a [SQLite](https://www.sqlite.org/) database stored in your system's cache directory.
|
||||
The default storage path depends on your operation system and installation method:
|
||||
|
||||
- **macOS Desktop**: `/Users/<username>/.langflow/data/database.db`
|
||||
- **Windows Desktop**: `C:\Users\<name>\AppData\Roaming\com.Langflow\data\langflow.db`
|
||||
- **OSS macOS/Windows/Linux/WSL (uv pip install)**: `<path_to_venv>/lib/python3.12/site-packages/langflow/langflow.db` (Python version may vary)
|
||||
- **OSS macOS/Windows/Linux/WSL (git clone)**: `<path_to_clone>/src/backend/base/langflow/langflow.db`
|
||||
- **OSS macOS/Windows/Linux/WSL (`uv pip install`)**: `<path_to_venv>/lib/python3.12/site-packages/langflow/langflow.db` (Python version may vary)
|
||||
- **OSS macOS/Windows/Linux/WSL (`git clone`)**: `<path_to_clone>/src/backend/base/langflow/langflow.db`
|
||||
|
||||
Alternatively, you can use an external PostgreSQL database for all of your Langflow storage.
|
||||
You can also selectively use external storage for chat memory, separate from other Langflow storage.
|
||||
For more information, see [Configure external memory](#configure-external-memory) and [Store chat memory](#store-chat-memory).
|
||||
|
||||
## Local Langflow database tables
|
||||
|
||||
The following tables are stored in `langflow.db`:
|
||||
|
||||
• **User** - Stores user account information including credentials, permissions, and profiles. For more information, see [Authentication](/configuration-authentication).
|
||||
• **User**: Stores user account information including credentials, permissions, and profiles. For more information, see [Authentication](/configuration-authentication).
|
||||
|
||||
• **Flow** - Contains flow configurations. For more information, see [Build flows](/concepts-flows).
|
||||
• **Flow**: Contains flow configurations. For more information, see [Build flows](/concepts-flows).
|
||||
|
||||
• **Message** - Stores chat messages and interactions that occur between components. For more information, see [Message objects](/data-types#message).
|
||||
• **Message**: Stores chat messages and interactions that occur between components. For more information, see [Message objects](/data-types#message) and [Store chat memory](#store-chat-memory).
|
||||
|
||||
• **Transaction** - Records execution history and results of flow runs. This information is used for [logging](/logging).
|
||||
• **Transaction**: Records execution history and results of flow runs. This information is used for [logging](/logging).
|
||||
|
||||
• **ApiKey** - Manages API authentication keys for users. For more information, see [API keys](/configuration-api-keys).
|
||||
• **ApiKey**: Manages API authentication keys for users. For more information, see [API keys](/configuration-api-keys).
|
||||
|
||||
• **Project** - Provides a structure for flow storage. For more information, see [Projects](/concepts-flows#projects).
|
||||
• **Project**: Provides a structure for flow storage. For more information, see [Projects](/concepts-flows#projects).
|
||||
|
||||
• **Variables** - Stores global encrypted values and credentials. For more information, see [Global variables](/configuration-global-variables).
|
||||
• **Variables**: Stores global encrypted values and credentials. For more information, see [Global variables](/configuration-global-variables).
|
||||
|
||||
• **VertexBuild** - Tracks the build status of individual nodes within flows. For more information, see [Run a flow in the Playground](/concepts-playground).
|
||||
• **VertexBuild**: Tracks the build status of individual nodes within flows. For more information, see [Run a flow in the Playground](/concepts-playground).
|
||||
|
||||
For more information, see the database models in the [source code](https://github.com/langflow-ai/langflow/tree/main/src/backend/base/langflow/services/database/models).
|
||||
|
||||
## Store messages in local memory
|
||||
|
||||
To store and retrieve messages in local Langflow memory, add a [Message history](/components-helpers#message-history) component to your flow.
|
||||
|
||||
To store or retrieve chat messages from external memory, connect the **External memory** port of the **Message history** component to a **Memory** component.
|
||||
An example flow looks like this:
|
||||
|
||||

|
||||
|
||||
If external storage is connected to a memory helper component, no chat messages are stored in local Langflow memory.
|
||||
|
||||
For an example of using local chat memory, see the [Memory chatbot](/memory-chatbot) starter flow.
|
||||
|
||||
## Configure external memory
|
||||
|
||||
To replace the default Langflow SQLite database with another database, modify the `LANGFLOW_DATABASE_URL` and start Langflow with this value.
|
||||
To replace the default Langflow SQLite database with another database, modify the `LANGFLOW_DATABASE_URL` environment variable, and then start Langflow with your `.env` file:
|
||||
|
||||
```
|
||||
LANGFLOW_DATABASE_URL=postgresql://user:password@localhost:5432/langflow
|
||||
|
|
@ -60,7 +54,7 @@ LANGFLOW_DATABASE_URL=postgresql://user:password@localhost:5432/langflow
|
|||
|
||||
For an example, see [Configure an external PostgreSQL database](/configuration-custom-database).
|
||||
|
||||
## Configure the external database connection
|
||||
### Configure the external database connection
|
||||
|
||||
The following settings allow you to fine-tune your database connection pool and timeout settings:
|
||||
|
||||
|
|
@ -88,6 +82,59 @@ LANGFLOW_CACHE_TYPE=Async
|
|||
Alternative caching options can be configured, but options other than the default asynchronous, in-memory cache are not supported.
|
||||
The default behavior is suitable for most use cases.
|
||||
|
||||
## Store chat memory
|
||||
|
||||
Chat-based flows with a **Language Model** or **Agent** component have built-in chat memory that is enabled by default.
|
||||
This memory allows them to retrieve and reference messages from previous conversations associated with the same session ID.
|
||||
|
||||
Built-in chat memory stores memories in the Langflow `messages` table.
|
||||
|
||||
<details>
|
||||
<summary>How does chat memory work?</summary>
|
||||
|
||||
Chat memory is a cache for the LLM or agent to preserve past conversations to retain and reference that context in future interactions.
|
||||
For example, if a user has already told the LLM their name, the LLM can retrieve that information from chat memory rather than asking the user to repeat themselves in future conversations or messages.
|
||||
|
||||
Chat memory is distinct from vector store memory because it is built specifically for storing and retrieving chat messages from databases.
|
||||
|
||||
Components that support chat memory (such as the **Agent**, **Language Model**, **Message History**, or third-party **Chat Memory** components) provide access to their respective databases _as memory_.
|
||||
Retrieval as memory is an important distinction for LLMs and agents because this storage and retrieval mechanism is specifically designed to recall context from past conversations.
|
||||
Unlike vector stores, which are designed for semantic search and retrieval of text chunks, chat memory is designed to store and retrieve chat messages in a way that is optimized for conversation history.
|
||||
|
||||
</details>
|
||||
|
||||
### Session ID and chat memory
|
||||
|
||||
Chat memories are grouped by [session ID (`session_id`)](/session-id).
|
||||
|
||||
The default session ID is the flow ID, which means that all chat messages for a flow are stored under the same session ID as one large chat session.
|
||||
|
||||
For better segregation of chat memory, especially in flows used by multiple users, consider using custom session IDs.
|
||||
For example, if you use user IDs as session IDs, then each user's chat history is stored separately, isolating the context of their chats from other users' chats.
|
||||
|
||||
### Chat memory options
|
||||
|
||||
Where and how chat memory is stored depends on the components used in your flow:
|
||||
|
||||
* **Language Model and Agent components**: All messages are stored in [Langflow storage](#storage-options-and-paths).
|
||||
The **Agent** component provides some memory configuration options, such as **Number of Chat History Messages**.
|
||||
|
||||
The **Language Model** and **Agent** component's built-in chat memory are sufficient for most use cases.
|
||||
|
||||
If you prefer to use dedicated, external chat memory storage, or you need to retrieve memories outside the context of a chat, you can add **Message History** and **Chat Memory** components to your flow.
|
||||
|
||||
* **Message History component**: By default, this component stores and retrieves memories from Langflow storage, unless you attach a **Chat Memory** component. It provides a few more options for sorting and filtering memories, although most of these options are built-in to the **Agent** component as configurable or fixed parameters.
|
||||
|
||||
You can use the **Message History** component with or without a **Language Model** or **Agent** component.
|
||||
For example, if you need to retrieve data from memories outside of chat, you can use the **Message History** component to fetch that data directly from your chat memory database without feeding it into a chat.
|
||||
|
||||
* **Third-party Chat Memory components**: Use one of these components only if you need to specifically store or retrieve chat memories from a dedicated chat memory database.
|
||||
Typically, this is necessary only if you have specific storage needs that aren't met by Langflow storage.
|
||||
For example, if you want to manage chat memory data by directly working with the database, or if you want to use a different database than the default Langflow storage.
|
||||
|
||||
For more information and examples, see [**Message History** component](/components-helpers#message-history) and [Agent memory](/agents#agent-memory).
|
||||
|
||||
## See also
|
||||
|
||||
* [Langflow file management](/concepts-file-management)
|
||||
* [Langflow file management](/concepts-file-management)
|
||||
* [Langflow logs](/logging)
|
||||
|
|
@ -42,10 +42,8 @@ For more extensive projects, you can build Langflow as a dependency or deploy a
|
|||
|
||||
For more information, see the following:
|
||||
|
||||
* [Share and embed flows](/concepts-publish)
|
||||
* [Get started with the Langflow API](/api-reference-api-examples)
|
||||
* [Develop an application with Langflow](/develop-application)
|
||||
* [Langflow deployment overview](/deployment-overview)
|
||||
* [Trigger flows with the Langflow API](/concepts-publish)
|
||||
* [Containerize a Langflow application](/develop-application)
|
||||
|
||||
## Endless modifications and integrations
|
||||
|
||||
|
|
|
|||
|
|
@ -551,8 +551,8 @@ payload = {
|
|||
|
||||
## Next steps
|
||||
|
||||
* [Trigger flows with the Langflow API](/concepts-publish)
|
||||
* [Use Langflow as a Model Context Protocol (MCP) server](/mcp-server)
|
||||
* [Develop an application with Langflow](/develop-application)
|
||||
* [Deploy a Langflow server](/deployment-overview)
|
||||
* [Containerize a Langflow application](/develop-application)
|
||||
* [File management](/concepts-file-management)
|
||||
* [Credential management](/configuration-api-keys)
|
||||
|
|
@ -3,65 +3,44 @@ title: Apify
|
|||
slug: /integrations-apify
|
||||
---
|
||||
|
||||
# Integrate Apify with Langflow
|
||||
import Icon from "@site/src/components/icon";
|
||||
|
||||
[Apify](https://apify.com/) is a web scraping and data extraction platform. It provides an [Actor Store](https://apify.com/store) with more than 3,000 ready-made cloud tools called **Actors**.
|
||||
[Apify](https://apify.com/) is a web scraping and data extraction platform with more than 3,000 ready-made cloud tools called **Actors**.
|
||||
|
||||
Apify components in Langflow run **Actors** to accomplish tasks like data extraction, content analysis, and SQL operations.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
* An [Apify API token](https://docs.apify.com/platform/integrations/api)
|
||||
Your flows can use the **Apify Actors** component to run **Actors** to accomplish tasks like data extraction, content analysis, and SQL operations.
|
||||
|
||||
## Use the Apify Actors component in a flow
|
||||
|
||||
To use an **Apify Actor** in your flow:
|
||||
1. Add an **Apify Actors** component to your flow, and then configure it as follows:
|
||||
|
||||
1. Click and drag the **Apify Actors** component to your **workspace**.
|
||||
2. In the **Apify Actor** component's **Apify Token** field, add your **Apify API token**.
|
||||
3. In the **Apify Actor** component's **Actor** field, add your **Actor ID**.
|
||||
You can find the Actor ID in the [Apify Actor Store](https://apify.com/store).
|
||||
For example, the [Website Content Crawler](https://apify.com/apify/website-content-crawler) has Actor ID `apify/website-content-crawler`.
|
||||
4. The component can now be used as a **Tool** to be connected to an **Agent** component, or configured to run manually.
|
||||
For more information on running the component manually, see the **JSON Example** in the [Apify documentation](https://apify.com/apify/website-content-crawler/input-schema).
|
||||
* **Apify Token**: Enter your [Apify API token](https://docs.apify.com/platform/integrations/api).
|
||||
* **Actor**: Enter the ID of the Actor you want to run from the [Apify Actor Store](https://apify.com/store). For example, the [Website Content Crawler](https://apify.com/apify/website-content-crawler) has the Actor ID `apify/website-content-crawler`.
|
||||
* **Run Input**: Enter the [JSON input for configuring the Actor run](https://docs.apify.com/platform/actors/running-actors#input).
|
||||
* Configure additional parameters and commands depending on the Actor you chose and your use case.
|
||||
|
||||
## Example flows
|
||||
2. Connect the component to other components in your flow.
|
||||
The component can be used to perform tasks as a standalone step in a flow or as a tool for an agent.
|
||||
|
||||
Here are some example flows that use the **Apify Actors** component.
|
||||
To enable tool mode for this component, change the component's output type from **Output** to **Tool**, and then connect it to the **Tools** port on an **Agent** component.
|
||||
|
||||
### Extract website text content in Markdown
|
||||
**Apify Actors** components output the results of the Actor run as a JSON object in Langflow's [`Data` type](/data-types#data).
|
||||
|
||||
Use the [Website Content Crawler Actor](https://apify.com/apify/website-content-crawler) to extract text content in Markdown format from a website and process it in your flow.
|
||||
## Example Apify Actors flows
|
||||
|
||||

|
||||
The following scenarios provide a few examples of how you could use the **Apify Actors** components in Langflow:
|
||||
|
||||
### Process web content with an agent
|
||||
* **Extract website text content in Markdown**: Use the [Website Content Crawler Actor](https://apify.com/apify/website-content-crawler) to extract text content in Markdown format from a website, and then connect the **Output** to a **Parser** component's input for further processing.
|
||||
|
||||
Extract website content using the [Website Content Crawler Actor](https://apify.com/apify/website-content-crawler), and then process it with an agent.
|
||||

|
||||
|
||||
The agent takes the extracted data and transforms it into summaries, insights, or structured responses to make the information more actionable.
|
||||
* **Process web content with an agent**: Attach a [Website Content Crawler Actor](https://apify.com/apify/website-content-crawler) to an **Agent** component as a tool so the agent can decide whether to extract website content based on the chat input. The agent could take the extracted data and transform it into summaries, insights, or structured responses to make the information more actionable.
|
||||
|
||||

|
||||

|
||||
|
||||
### Analyze social media profiles with multiple actors
|
||||
* **Analyze social media profiles with multiple actors**: Perform comprehensive social media research with multiple Apify Actors:
|
||||
|
||||
Perform comprehensive social media research with multiple Apify Actors.
|
||||
* Use the [Google Search Results Scraper Actor](https://apify.com/apify/google-search-scraper) to find relevant social media profiles.
|
||||
* Use the [TikTok Data Extractor Actor](https://apify.com/clockworks/free-tiktok-scraper) to gather data and videos.
|
||||
* Attach both actors as tools for an **Agent** component to collect the links from Google and content from TikTok, and then analyze the data to provide insights about a person, brand, or topic.
|
||||
|
||||
Add the [Google Search Results Scraper Actor](https://apify.com/apify/google-search-scraper) to find relevant social media profiles, and then add the [TikTok Data Extractor Actor](https://apify.com/clockworks/free-tiktok-scraper) to gather data and videos.
|
||||
|
||||
The agent collects the links from Google and content from TikTok and analyzes the data to provide insights about a person, brand, or topic.
|
||||

|
||||
|
||||
## Inputs
|
||||
|
||||
| Name | Display Name | Info |
|
||||
|------|--------------|------|
|
||||
| apify_token | Apify Token | Your Apify API key. |
|
||||
| actor | Actor | The Apify Actor to run, for example `apify/website-content-crawler`. |
|
||||
| run_input | Run Input | The JSON input for configuring the Actor run. For more information, see the [Apify documentation](https://apify.com/apify/website-content-crawler/input-schema). |
|
||||
|
||||
## Outputs
|
||||
|
||||
| Name | Display Name | Info |
|
||||
|------|--------------|------|
|
||||
| output | Actor Run Result | The JSON response containing the output of the Actor run. |
|
||||

|
||||
|
|
@ -1,5 +1,5 @@
|
|||
---
|
||||
title: Integrate Arize with Langflow
|
||||
title: Arize
|
||||
slug: /integrations-arize
|
||||
---
|
||||
|
||||
|
|
@ -8,9 +8,16 @@ import TabItem from '@theme/TabItem';
|
|||
|
||||
Arize is a tool built on [OpenTelemetry](https://opentelemetry.io/) and [OpenInference](https://docs.arize.com/phoenix/reference/open-inference) for monitoring and optimizing LLM applications.
|
||||
|
||||
To add tracing to your Langflow application, add Arize environment variables to your Langflow application.
|
||||
To enable Arize tracing, set the required Arize environment variables in your Langflow deployment.
|
||||
Arize begins monitoring and collecting telemetry data from your LLM applications automatically.
|
||||
|
||||
:::tip
|
||||
Instructions for integrating Langflow and Arize are also available in the Arize documentation:
|
||||
|
||||
* [Langflow tracing with Arize Platform](https://arize.com/docs/ax/integrations/frameworks-and-platforms/langflow/langflow-tracing)
|
||||
* [Langflow tracing with Arize Phoenix](https://arize.com/docs/phoenix/integrations/langflow/langflow-tracing)
|
||||
:::
|
||||
|
||||
## Prerequisites
|
||||
|
||||
* If you are using the [standard Arize platform](https://docs.arize.com/arize), you need an **Arize Space ID** and **Arize API Key**.
|
||||
|
|
@ -21,67 +28,81 @@ Arize begins monitoring and collecting telemetry data from your LLM applications
|
|||
<Tabs>
|
||||
<TabItem value="Arize Platform" label="Arize Platform" default>
|
||||
|
||||
1. To retrieve your **Arize Space ID** and **Arize API Key**, navigate to the [Arize dashboard](https://app.arize.com/).
|
||||
2. Click **Settings**, and then click **Space Settings and Keys**.
|
||||
3. Copy the **SpaceID** and **API Key (Ingestion Service Account Key)** values.
|
||||
4. Create a `.env` file in the root of your Langflow application.
|
||||
5. Add the `ARIZE_SPACE_ID` and `ARIZE_API_KEY` environment variables to your Langflow application.
|
||||
You do not need to specify the **Arize Project** name if you're using the standard Arize platform.
|
||||
Replace the following:
|
||||
1. In your [Arize dashboard](https://app.arize.com/), copy your **Space ID** and [**API Key (Ingestion Service Account Key)**](https://arize.com/docs/ax/security-and-settings/api-keys).
|
||||
|
||||
* YOUR_ARIZE_SPACE_ID: the **SpaceID** value copied from Arize
|
||||
* YOUR_ARIZE_API_KEY: the **API Key** value copied from Arize
|
||||
2. In the root of your Langflow application, edit your existing Langflow `.env` file or create a new one.
|
||||
|
||||
3. Add `ARIZE_SPACE_ID` and `ARIZE_API_KEY` environment variables:
|
||||
|
||||
```bash
|
||||
ARIZE_SPACE_ID=SPACE_ID
|
||||
ARIZE_API_KEY=API_KEY
|
||||
```
|
||||
|
||||
Replace `SPACE_ID` and `API_KEY` with the values you copied from the Arize platform.
|
||||
|
||||
You do not need to specify the Arize project name if you're using the standard Arize platform.
|
||||
|
||||
4. Start your Langflow application with your `.env` file:
|
||||
|
||||
```bash
|
||||
uv run langflow run --env-file .env
|
||||
```
|
||||
|
||||
```bash
|
||||
ARIZE_SPACE_ID=YOUR_ARIZE_SPACE_ID
|
||||
ARIZE_API_KEY=YOUR_ARIZE_API_KEY
|
||||
```
|
||||
6. Save the `.env` file.
|
||||
7. Start your Langflow application with the values from the `.env` file.
|
||||
```bash
|
||||
uv run langflow run --env-file .env
|
||||
```
|
||||
</TabItem>
|
||||
<TabItem value="Arize Phoenix" label="Arize Phoenix">
|
||||
|
||||
1. To retrieve your **Arize Phoenix API key**, navigate to the [Arize dashboard](https://app.phoenix.arize.com/).
|
||||
2. Click **API Key**.
|
||||
3. Copy the **API Key** value.
|
||||
4. Create a `.env` file in the root of your Langflow application.
|
||||
5. Add the `PHOENIX_API_KEY` environment variable to your application instead.
|
||||
Replace `YOUR_PHOENIX_API_KEY` with the Arize Phoenix API key that you copied from the Arize Phoenix platform.
|
||||
1. In your [Arize Phoenix dashboard](https://app.phoenix.arize.com/), copy your **API Key**.
|
||||
|
||||
```bash
|
||||
PHOENIX_API_KEY=YOUR_PHOENIX_API_KEY
|
||||
```
|
||||
2. In the root of your Langflow application, edit your existing Langflow `.env` file or create a new one.
|
||||
|
||||
3. Add a `PHOENIX_API_KEY` environment variable:
|
||||
|
||||
```bash
|
||||
PHOENIX_API_KEY=API_KEY
|
||||
```
|
||||
|
||||
Replace `API_KEY` with the Arize Phoenix API key that you copied from the Arize Phoenix platform.
|
||||
|
||||
4. Start your Langflow application with your `.env` file:
|
||||
|
||||
```bash
|
||||
uv run langflow run --env-file .env
|
||||
```
|
||||
|
||||
6. Save the `.env` file.
|
||||
7. Start your Langflow application with the values from the `.env` file.
|
||||
```bash
|
||||
uv run langflow run --env-file .env
|
||||
```
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
For more information, see the [Arize documentation](https://docs.arize.com/phoenix/tracing/integrations-tracing/langflow#go-to-arize-phoenix).
|
||||
|
||||
## Run a flow and view metrics in Arize
|
||||
|
||||
1. In Langflow, select the [Simple agent](/simple-agent) starter project.
|
||||
2. In the **Agent** component's **OpenAI API Key** field, paste your **OpenAI API key**.
|
||||
3. Click **Playground**.
|
||||
Ask your Agent some questions to generate traffic.
|
||||
4. Navigate to the [Arize dashboard](https://app.arize.com/), and then open your project.
|
||||
You may have to wait a few minutes for Arize to process the data.
|
||||
5. The **LLM Tracing** tab shows metrics for your flow.
|
||||
Each Langflow execution generates two traces in Arize.
|
||||
The `AgentExecutor` trace is the Arize trace of Langchain's `AgentExecutor`. The UUID trace is the trace of the Langflow components.
|
||||
6. To view traces, click the **Traces** tab.
|
||||
A **trace** is the complete journey of a request, made of multiple **spans**.
|
||||
7. To view **Spans**, select the **Spans** tab.
|
||||
A **span** is a single operation within a trace. For example, a **span** could be a single API call to OpenAI or a single function call to a custom tool.
|
||||
For more on traces, spans, and other metrics in Arize, see the [Arize documentation](https://docs.arize.com/arize/llm-tracing/tracing).
|
||||
8. All metrics in the **LLM Tracing** tab can be added to **Datasets**.
|
||||
To add a span to a **Dataset**, click the **Add to Dataset** button.
|
||||
9. To view a **Dataset**, click the **Datasets** tab, and then select your **Dataset**.
|
||||
For more on **Datasets**, see the [Arize documentation](https://docs.arize.com/arize/llm-datasets-and-experiments/datasets-and-experiments).
|
||||
1. In Langflow, run a flow that has an **Agent** or **Language Model** component.
|
||||
You must chat with the flow or trigger the LLM to produce traffic for Arize to trace.
|
||||
|
||||
For example, you can create a flow from the [**Simple Agent** template](/simple-agent), add your OpenAI API key to the **Agent** component, and then click **Playground** to chat with the flow and generate traffic.
|
||||
|
||||
2. In Arize, open your project dashboard, and then wait for Arize to process the data.
|
||||
This can take a few minutes.
|
||||
|
||||
3. To view metrics for your flows, go to the **LLM Tracing** tab.
|
||||
|
||||
Each Langflow execution generates two traces in Arize:
|
||||
|
||||
* The `AgentExecutor` trace is the Arize trace of LangChain's `AgentExecutor`.
|
||||
* The `UUID` trace is the trace of the Langflow components.
|
||||
|
||||
4. To view traces, go to the **Traces** tab.
|
||||
|
||||
A _trace_ is the complete journey of a request, made of multiple _spans_.
|
||||
|
||||
5. To view spans, go to the **Spans** tab.
|
||||
|
||||
A _span_ is a single operation within a trace.
|
||||
For example, a _span_ could be a single API call to OpenAI or a single function call to a custom tool.
|
||||
|
||||
For information about tracing metrics in Arize, see the [Arize LLM tracing documentation](https://docs.arize.com/arize/llm-tracing/tracing).
|
||||
|
||||
6. To add a span to a [dataset](https://docs.arize.com/arize/llm-datasets-and-experiments/datasets-and-experiments), click **Add to Dataset**.
|
||||
|
||||
All metrics on the **LLM Tracing** tab can be added to datasets.
|
||||
|
||||
7. To view a dataset, click the **Datasets** tab, and then select your dataset.
|
||||
|
|
@ -1,118 +1,110 @@
|
|||
---
|
||||
title: Integrate Cleanlab Evaluations with Langflow
|
||||
title: Cleanlab
|
||||
slug: /integrations-cleanlab
|
||||
---
|
||||
|
||||
Unlock trustworthy Agentic, RAG, and LLM pipelines with Cleanlab's evaluation and remediation suite.
|
||||
import Icon from "@site/src/components/icon";
|
||||
|
||||
[Cleanlab](https://www.cleanlab.ai/) adds automation and trust to every data point going in and every prediction coming out of AI and RAG solutions.
|
||||
|
||||
This Langflow integration provides three Langflow components that assess and improve the trustworthiness of any LLM or RAG pipeline output.
|
||||
Use the Cleanlab components to integrate Cleanlab Evaluations with Langflow and unlock trustworthy Agentic, RAG, and LLM pipelines with Cleanlab's evaluation and remediation suite.
|
||||
|
||||
Use the components in this bundle to quantify the trustworthiness of any LLM response with a score between `0` and `1`, and explain why a response may be good or bad. For RAG/Agentic pipelines with context, you can evaluate context sufficiency, groundedness, helpfulness, and query clarity with quantitative scores. Additionally, you can remediate low-trust responses with warnings or fallback answers.
|
||||
You can use these components to quantify the trustworthiness of any LLM response with a score between `0` and `1`, and explain why a response may be good or bad. For RAG/Agentic pipelines with context, you can evaluate context sufficiency, groundedness, helpfulness, and query clarity with quantitative scores. Additionally, you can remediate low-trust responses with warnings or fallback answers.
|
||||
|
||||
## Prerequisites
|
||||
Authentication is required with a Cleanlab API key.
|
||||
|
||||
- [A Cleanlab API key](https://tlm.cleanlab.ai/)
|
||||
## Cleanlab Evaluator
|
||||
|
||||
## CleanlabEvaluator
|
||||
The **Cleanlab Evaluator** component evaluates and explains the trustworthiness of a prompt and response pair using Cleanlab. For more information on how the score works, see the [Cleanlab documentation](https://help.cleanlab.ai/tlm/).
|
||||
|
||||
This component evaluates and explains the trustworthiness of a prompt and response pair using Cleanlab. For more information on how the score works, see the [Cleanlab documentation](https://help.cleanlab.ai/tlm/).
|
||||
### Cleanlab Evaluator parameters
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
Some **Cleanlab Evaluator** component input parameters are hidden by default in the visual editor.
|
||||
You can toggle parameters through the <Icon name="SlidersHorizontal" aria-hidden="true"/> **Controls** in the [component's header menu](/concepts-components#component-menus).
|
||||
|
||||
**Inputs**
|
||||
| Name | Type | Description |
|
||||
|-------------------------|------------|------------------------------------|
|
||||
| system_prompt | Message | Input parameter. The system message prepended to the prompt. Optional. |
|
||||
| prompt | Message | Input parameter. The user-facing input to the LLM. |
|
||||
| response | Message | Input parameter. The model's response to evaluate. |
|
||||
| cleanlab_api_key | Secret | Input parameter. Your Cleanlab API key. |
|
||||
| cleanlab_evaluation_model | Dropdown | Input parameter. Evaluation model used by Cleanlab, such as GPT-4 or Claude. This does not need to be the same model that generated the response. |
|
||||
| quality_preset | Dropdown | Input parameter. Tradeoff between evaluation speed and accuracy. |
|
||||
|
||||
| Name | Type | Description |
|
||||
|-------------------------|------------|-------------------------------------------------------------------------|
|
||||
| system_prompt | Message | The system message prepended to the prompt. Optional. |
|
||||
| prompt | Message | The user-facing input to the LLM. |
|
||||
| response | Message | The model's response to evaluate. |
|
||||
| cleanlab_api_key | Secret | Your Cleanlab API key. |
|
||||
| cleanlab_evaluation_model | Dropdown | Evaluation model used by Cleanlab, such as GPT-4 or Claude. This does not need to be the same model that generated the response. |
|
||||
| quality_preset | Dropdown | Tradeoff between evaluation speed and accuracy. |
|
||||
### Cleanlab Evaluator outputs
|
||||
|
||||
**Outputs**
|
||||
The **Cleanlab Evaluator** component has three possible outputs.
|
||||
|
||||
| Name | Type | Description |
|
||||
|-------------------------|------------|-------------------------------------------------------------------------|
|
||||
| score | number | Displays the trust score between `0–1`. |
|
||||
| explanation | Message | Provides an explanation of the trust score. |
|
||||
| response | Message | Returns the original response for easy chaining to the `CleanlabRemediator` component. |
|
||||
| Name | Type | Description |
|
||||
|-------------------------|------------|-------------------------|
|
||||
| score | number, float | Displays the trust score between 0 and 1. |
|
||||
| explanation | `Message` | Provides an explanation of the trust score. |
|
||||
| response | `Message` | Returns the original response for easy chaining to the **Cleanlab Remediator** component. |
|
||||
|
||||
</details>
|
||||
## Cleanlab Remediator
|
||||
|
||||
## CleanlabRemediator
|
||||
The **Cleanlab Remediator** component uses the trust score from the [**Cleanlab Evaluator** component](#cleanlab-evaluator) to determine whether to show, warn about, or replace an LLM response.
|
||||
|
||||
This component uses the trust score from the [CleanlabEvaluator](#cleanlabevaluator) component to determine whether to show, warn about, or replace an LLM response. This component has configurables for the score threshold, warning text, and fallback message that you can customize as needed.
|
||||
This component has parameters for the score threshold, warning text, and fallback message that you can customize as needed.
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
The output is **Remediated Response** (`remediated_response`), which is a `Message` containing the final message shown to the user after remediation logic is applied.
|
||||
|
||||
**Inputs**
|
||||
### Cleanlab Remediator parameters
|
||||
|
||||
| Name | Type | Description |
|
||||
|-----------------------------|------------|-------------------------------------------------------------------------|
|
||||
| response | Message | The response to potentially remediate. |
|
||||
| score | number | The trust score from `CleanlabEvaluator`. |
|
||||
| explanation | Message | The explanation to append if a warning is shown. Optional. |
|
||||
| threshold | float | The minimum trust score to pass a response unchanged. |
|
||||
| show_untrustworthy_response | bool | Whether to display or hide the original response with a warning if a response is deemed untrustworthy. |
|
||||
| untrustworthy_warning_text | Prompt | The warning text for untrustworthy responses. |
|
||||
| fallback_text | Prompt | The fallback message if the response is hidden. |
|
||||
| Name | Type | Description |
|
||||
|-----------------------------|------------|---------|
|
||||
| response | Message | Input parameter. The response to potentially remediate. |
|
||||
| score | Number | Input parameter. The trust score from `CleanlabEvaluator`. |
|
||||
| explanation | Message | Input parameter. The explanation to append if a warning is shown. Optional.|
|
||||
| threshold | Float | Input parameter. The minimum trust score to pass a response unchanged. |
|
||||
| show_untrustworthy_response | Boolean | Input parameter. Whether to display or hide the original response with a warning if a response is deemed untrustworthy. |
|
||||
| untrustworthy_warning_text | Prompt | Input parameter. The warning text for untrustworthy responses. |
|
||||
| fallback_text | Prompt | Input parameter. The fallback message if the response is hidden. |
|
||||
|
||||
**Outputs**
|
||||
## Cleanlab RAG Evaluator
|
||||
|
||||
| Name | Type | Description |
|
||||
|-------------------------|------------|-------------------------------------------------------------------------|
|
||||
| remediated_response | Message | The final message shown to user after remediation logic. |
|
||||
The **Cleanlab RAG Evaluator** component evaluates RAG and LLM pipeline outputs for trustworthiness, context sufficiency, response groundedness, helpfulness, and query ease using [Cleanlab's evaluation metrics](https://help.cleanlab.ai/tlm/use-cases/tlm_rag/).
|
||||
|
||||
</details>
|
||||
You can pair this component with the [**Cleanlab Remediator** component](#cleanlab-remediator) to remediate low-trust responses coming from the RAG pipeline.
|
||||
|
||||
## CleanlabRAGEvaluator
|
||||
### Cleanlab RAG Evaluator parameters
|
||||
|
||||
This component evaluates RAG and LLM pipeline outputs for trustworthiness, context sufficiency, response groundedness, helpfulness, and query ease. Learn more about Cleanlab's evaluation metrics [here](https://help.cleanlab.ai/tlm/use-cases/tlm_rag/).
|
||||
Some **Cleanlab RAG Evaluator** component input parameters are hidden by default in the visual editor.
|
||||
You can toggle parameters through the <Icon name="SlidersHorizontal" aria-hidden="true"/> **Controls** in the [component's header menu](/concepts-components#component-menus).
|
||||
|
||||
Additionally, use the [CleanlabRemediator](#cleanlabremediator) component with this component to remediate low-trust responses coming from the RAG pipeline.
|
||||
| Name | Type | Description |
|
||||
|-----------------------------|------------|------------|
|
||||
| cleanlab_api_key | Secret | Input parameter. Your Cleanlab API key. |
|
||||
| cleanlab_evaluation_model | Dropdown | Input parameter. The evaluation model used by Cleanlab, such as GPT-4, or Claude. This does not need to be the same model that generated the response. |
|
||||
| quality_preset | Dropdown | Input parameter. The tradeoff between evaluation speed and accuracy. |
|
||||
| context | Message | Input parameter. The retrieved context from your RAG system. |
|
||||
| query | Message | Input parameter. The original user query. |
|
||||
| response | Message | Input parameter. The model's response based on the context and query. |
|
||||
| run_context_sufficiency | Boolean | Input parameter. Evaluate whether context supports answering the query. |
|
||||
| run_response_groundedness | Boolean | Input parameter. Evaluate whether the response is grounded in the context. |
|
||||
| run_response_helpfulness | Boolean | Input parameter. Evaluate how helpful the response is. |
|
||||
| run_query_ease | Boolean | Input parameter. Evaluate if the query is vague, complex, or adversarial. |
|
||||
|
||||
<details>
|
||||
<summary>Parameters</summary>
|
||||
### Cleanlab RAG Evaluator outputs
|
||||
|
||||
**Inputs**
|
||||
The **Cleanlab RAG Evaluator** component has the following output options:
|
||||
|
||||
| Name | Type | Description |
|
||||
|-----------------------------|------------|-------------------------------------------------------------------------|
|
||||
| cleanlab_api_key | Secret | Your Cleanlab API key. |
|
||||
| cleanlab_evaluation_model | Dropdown | Thevaluation model used by Cleanlab, such as GPT-4, or Claude. This does not need to be the same model that generated the response. |
|
||||
| quality_preset | Dropdown | The tradeoff between evaluation speed and accuracy. |
|
||||
| context | Message | The retrieved context from your RAG system. |
|
||||
| query | Message | The original user query. |
|
||||
| response | Message | The model's response based on the context and query. |
|
||||
| run_context_sufficiency | bool | Evaluate whether context supports answering the query. |
|
||||
| run_response_groundedness | bool | Evaluate whether the response is grounded in the context. |
|
||||
| run_response_helpfulness | bool | Evaluate how helpful the response is. |
|
||||
| run_query_ease | bool | Evaluate if the query is vague, complex, or adversarial. |
|
||||
| Name | Type | Description |
|
||||
|--------------------|------------|--------------------------|
|
||||
| trust_score | Number | The overall trust score. |
|
||||
| trust_explanation | Message | The explanation for the trust score. |
|
||||
| other_scores | Dictionary | A dictionary of optional enabled RAG evaluation metrics. |
|
||||
| evaluation_summary | Message | A Markdown summary of query, context, response, and evaluation results. |
|
||||
| response | Message | Returns the original response for easy chaining to the **Cleanlab Remediator** component. |
|
||||
|
||||
**Outputs**
|
||||
|
||||
| Name | Type | Description |
|
||||
|-------------------------|------------|-------------------------------------------------------------------------|
|
||||
| trust_score | number | The overall trust score. |
|
||||
| trust_explanation | Message | The explanation for the trust score. |
|
||||
| other_scores | dict | A dictionary of optional enabled RAG evaluation metrics. |
|
||||
| evaluation_summary | Message | A Markdown summary of query, context, response, and evaluation results. |
|
||||
|
||||
</details>
|
||||
|
||||
## Cleanlab component example flows
|
||||
## Example Cleanlab flows
|
||||
|
||||
The following example flows show how to use the **CleanlabEvaluator** and **CleanlabRemediator** components to evaluate and remediate responses from any LLM, and how to use the `CleanlabRAGEvaluator` component to evaluate RAG pipeline outputs.
|
||||
|
||||
### Evaluate and remediate responses from an LLM
|
||||
|
||||
:::tip
|
||||
Optionally, [Download](./eval_and_remediate_cleanlab.json) the Evaluate and Remediate flow and follow along.
|
||||
You can [download the the Evaluate and Remediate flow](./eval_and_remediate_cleanlab.json), and then import it to your Langflow instance to follow along.
|
||||
:::
|
||||
|
||||
This flow evaluates and remediates the trustworthiness of a response from any LLM using the **CleanlabEvaluator** and **CleanlabRemediator** components.
|
||||
|
|
|
|||
|
|
@ -1,104 +1,112 @@
|
|||
---
|
||||
title: Integrate Composio with Langflow
|
||||
title: Composio
|
||||
slug: /integrations-composio
|
||||
---
|
||||
|
||||
Langflow integrates with [Composio](https://docs.composio.dev/introduction/intro/overview) as a toolset for your **Agent** component.
|
||||
Composio components in Langflow provide [Composio](https://app.composio.dev/) tools to your **Agent** components.
|
||||
|
||||
Instead of juggling multiple integrations and components in your flow, connect the Composio component to an **Agent** component to use all of Composio's supported APIs and actions as **Tools** for your agent.
|
||||
Instead of juggling multiple integrations and components in your flow, connect Composio components to an **Agent** component to use all of Composio's supported APIs and actions as tools for your agent.
|
||||
|
||||
## Prerequisites
|
||||
The following components are available in the **Composio** bundle:
|
||||
|
||||
- [A Composio API key](https://app.composio.dev/)
|
||||
- [An OpenAI API key](https://platform.openai.com/)
|
||||
- [A Gmail account](https://mail.google.com)
|
||||
* **Composio Tools**
|
||||
* **GitHub**
|
||||
* **Gmail**
|
||||
* **Google Calendar**
|
||||
* **Outlook**
|
||||
* **Slack**
|
||||
|
||||
## Connect Langflow to a Composio tool
|
||||
For information about specific Composio functionality, see the [Composio documentation](https://docs.composio.dev/introduction/intro/overview).
|
||||
|
||||
## Authentication for Composio components
|
||||
|
||||
Composio components require authentication to Composio with a Composio API key.
|
||||
|
||||
Depending on the components you use, you may also need additional access, such as an OpenAI API key, Gmail account, or GitHub account.
|
||||
|
||||
## Use Composio components in a flow
|
||||
|
||||
1. In the Langflow **Workspace**, add an **Agent** component.
|
||||
|
||||
2. In the **Workspace**, add the **Composio Tools** component.
|
||||
|
||||
3. Connect the **Agent** component's **Tools** port to the **Composio Tools** component's **Tools** port.
|
||||
4. In the **Composio API Key** field, paste your Composio API key.
|
||||
Alternatively, add the key as a [global variable](/configuration-global-variables).
|
||||
|
||||
4. In the **Composio API Key** field, enter your Composio API key.
|
||||
|
||||
5. In the **Tool Name** field, select the tool you want your agent to have access to.
|
||||
For this example, select the **Gmail** tool, which allows your agent to control an email account with the Composio tool.
|
||||
|
||||
For this example, select the **Gmail** tool to allow your agent to control an email account with the Composio tool.
|
||||
|
||||
6. In the **Actions** field, select the action you want the **Agent** to take with the **Gmail** tool.
|
||||
The **Gmail** tool supports multiple actions, and also supports multiple actions within the same tool.
|
||||
For this example, select **GMAIL_CREATE_EMAIL_DRAFT**.
|
||||
For more information, see the [Composio documentation](https://docs.composio.dev/patterns/tools/use-tools/use-specific-actions).
|
||||
|
||||
## Create a Composio flow
|
||||
The **Gmail** tool supports multiple actions, and it also supports multiple actions within the same tool.
|
||||
For this example, select **GMAIL_CREATE_EMAIL_DRAFT**.
|
||||
For more information, see the [Composio documentation](https://docs.composio.dev/patterns/tools/use-tools/use-specific-actions).
|
||||
|
||||
1. In the **Workspace**, add **Chat Input** and **Chat Output** components to your flow.
|
||||
2. Connect the components so they look like this.
|
||||
7. Add **Chat Input** and **Chat Output** components to your flow, and then connect them to the **Agent** component's **Input** and **Response**, respectively.
|
||||
|
||||

|
||||

|
||||
|
||||
3. In the **OpenAI API Key** field of the **Agent** component, paste your OpenAI API key.
|
||||
Alternatively, add the key as a [global variable](/configuration-global-variables).
|
||||
4. To open the **Playground** pane, click **Playground**.
|
||||
5. Ask your AI:
|
||||
8. In the **Agent** component, enter your OpenAI API key or configure the **Agent** component to use a different LLM.
|
||||
|
||||
```text
|
||||
What tools are available to you?
|
||||
```
|
||||
9. To test the connection to Composio, click **Playground**, and then ask the LLM about the tools available to it.
|
||||
The agent should provide a list of connected tools, including the **Gmail** tool and the built-in tools in the **Agent** component.
|
||||
|
||||
The response should be similar to:
|
||||
```text
|
||||
User:
|
||||
What tools are available to you?
|
||||
|
||||
```text
|
||||
I have access to the following tools:
|
||||
AI:
|
||||
I have access to the following tools:
|
||||
|
||||
1. **GMAIL_CREATE_EMAIL_DRAFT**: This tool allows me to create a draft email using Gmail's API. I can specify the recipient's email address, subject, body content, and whether the body content is HTML.
|
||||
1. **GMAIL_CREATE_EMAIL_DRAFT**: This tool allows me to create a draft email using Gmail's API. I can specify the recipient's email address, subject, body content, and whether the body content is HTML.
|
||||
|
||||
2. **CurrentDate-get_current_date**: This tool retrieves the current date and time in a specified timezone.
|
||||
```
|
||||
2. **CurrentDate-get_current_date**: This tool retrieves the current date and time in a specified timezone.
|
||||
```
|
||||
|
||||
This confirms your **Agent** and **Composio** are communicating.
|
||||
10. To test the specific tool, tell the agent to perform an action like writing a draft email:
|
||||
|
||||
6. Tell your AI to write a draft email.
|
||||
```text
|
||||
Create a draft email with the subject line "Greetings from Composio"
|
||||
recipient: "your.email@address.com"
|
||||
Body content: "Hello from composio!"
|
||||
```
|
||||
|
||||
```text
|
||||
Create a draft email with the subject line "Greetings from Composio"
|
||||
recipient: "your.email@address.com"
|
||||
Body content: "Hello from composio!"
|
||||
```
|
||||
The **Playground** shows the logic the agent choose to use specific tools.
|
||||
This example response is abbreviated.
|
||||
|
||||
Inspect the response to see how the agent used the attached tool to write an email.
|
||||
This example response is abbreviated.
|
||||
```text
|
||||
The draft email with the subject "Greetings from Composio" and body "Hello from composio!" has been successfully created.
|
||||
```
|
||||
|
||||
```text
|
||||
The draft email with the subject "Greetings from Composio" and body "Hello from composio!" has been successfully created.
|
||||
```
|
||||
|
||||
```json
|
||||
{
|
||||
"recipient_email": "your.email@address.com",
|
||||
"subject": "Greetings from Composio",
|
||||
"body": "Hello from composio!",
|
||||
"is_html": false
|
||||
}
|
||||
|
||||
{
|
||||
"data": {
|
||||
"response_data": {
|
||||
"id": "r-237981011463568567",
|
||||
"message": {
|
||||
"id": "195dd80528171132",
|
||||
"threadId": "195dd80528171132",
|
||||
"labelIds": [
|
||||
"DRAFT"
|
||||
]
|
||||
}
|
||||
```json
|
||||
{
|
||||
"recipient_email": "your.email@address.com",
|
||||
"subject": "Greetings from Composio",
|
||||
"body": "Hello from composio!",
|
||||
"is_html": false
|
||||
}
|
||||
},
|
||||
"error": null,
|
||||
"successfull": true,
|
||||
"successful": true
|
||||
}
|
||||
```
|
||||
|
||||
7. To confirm further, navigate to the Gmail account you authenticated with Composio.
|
||||
Your email is visible in **Drafts**.
|
||||
{
|
||||
"data": {
|
||||
"response_data": {
|
||||
"id": "r-237981011463568567",
|
||||
"message": {
|
||||
"id": "195dd80528171132",
|
||||
"threadId": "195dd80528171132",
|
||||
"labelIds": [
|
||||
"DRAFT"
|
||||
]
|
||||
}
|
||||
}
|
||||
},
|
||||
"error": null,
|
||||
"successfull": true,
|
||||
"successful": true
|
||||
}
|
||||
```
|
||||
|
||||
You have successfully integrated your Langflow component with Composio.
|
||||
To add more tools, add another Composio component.
|
||||
11. For further confirmation, you can go to your Gmail account and find the message in your drafts folder.
|
||||
|
||||
12. To add more Composio actions, add more Composio components to your flow, and then connect them to the **Agent** component's **Tools** port.
|
||||
|
|
@ -1,5 +1,5 @@
|
|||
---
|
||||
title: Integrate Docling with Langflow
|
||||
title: Docling
|
||||
slug: /integrations-docling
|
||||
---
|
||||
|
||||
|
|
|
|||
|
|
@ -1,12 +1,12 @@
|
|||
---
|
||||
title: Integrate Google BigQuery with Langflow
|
||||
title: Google BigQuery
|
||||
slug: /integrations-google-big-query
|
||||
---
|
||||
|
||||
import Tabs from '@theme/Tabs';
|
||||
import TabItem from '@theme/TabItem';
|
||||
|
||||
Langflow integrates with [Google BigQuery](https://cloud.google.com/bigquery) through the BigQuery component, allowing you to execute SQL queries and retrieve data from your BigQuery datasets.
|
||||
Langflow integrates with [Google BigQuery](https://cloud.google.com/bigquery) through the **BigQuery** component in the [**Google** bundle](/bundles-google), allowing you to execute SQL queries and retrieve data from your BigQuery datasets.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
|
|
|
|||
|
|
@ -1,37 +0,0 @@
|
|||
---
|
||||
title: Integrate Google Cloud Vertex AI with Langflow
|
||||
slug: /integrations-setup-google-cloud-vertex-ai-langflow
|
||||
---
|
||||
|
||||
Langflow integrates with the [Google Vertex AI API](https://console.cloud.google.com/marketplace/product/google/aiplatform.googleapis.com) for authenticating the [Vertex AI embeddings model](/components-bundle-components#vertexai-embeddings) and [Vertex AI](/components-bundle-components#vertexai) components.
|
||||
|
||||
Learn how to create a service account JSON in Google Cloud to authenticate Langflow’s Vertex AI components.
|
||||
|
||||
## Create a service account with Vertex AI access
|
||||
|
||||
1. Select and enable your Google Cloud project.
|
||||
For more information, see [Create a Google Cloud project](https://developers.google.com/workspace/guides/create-project).
|
||||
2. Create a service account in your Google Cloud project.
|
||||
For more information, see [Create a service account](https://developers.google.com/workspace/guides/create-credentials#service-account).
|
||||
3. Assign the **Vertex AI Service Agent** role to your new account.
|
||||
This role allows Langflow to access Vertex AI resources.
|
||||
For more information, see [Vertex AI access control with IAM](https://cloud.google.com/vertex-ai/docs/general/access-control).
|
||||
4. To generate a new JSON key for the service account, navigate to your service account.
|
||||
5. Click **Add Key**, and then click **Create new key**.
|
||||
6. Under **Key type**, select **JSON**, and then click **Create**.
|
||||
A JSON private key file is downloaded.
|
||||
Now that you have a service account and a JSON private key, you need to configure the credentials in Langflow components.
|
||||
|
||||
## Configure credentials in Langflow components
|
||||
|
||||
With your service account configured and your credentials JSON file created, follow these steps to authenticate the Langflow application.
|
||||
|
||||
1. Create a new project in Langflow.
|
||||
2. From the **Components** menu, drag and drop either the **Vertex AI** or **Vertex AI Embeddings** component to your workspace.
|
||||
3. In the Vertex AI component's **Credentials** field, add the service account JSON file.
|
||||
4. Confirm the component can access the Vertex AI resources.
|
||||
Connect a **Chat input** and **Chat output** component to the Vertex AI component.
|
||||
A successful chat confirms the component has access to the Vertex AI resources.
|
||||
|
||||

|
||||
|
||||
|
|
@ -6,136 +6,152 @@ slug: /integrations-langfuse
|
|||
import Tabs from '@theme/Tabs';
|
||||
import TabItem from '@theme/TabItem';
|
||||
|
||||
# Integrate Langfuse with Langflow
|
||||
[Langfuse](https://langfuse.com) is an open-source platform for LLM observability. It provides tracing and monitoring capabilities for AI applications, helping developers debug, analyze, and optimize their AI systems. Langfuse integrates with various tools and frameworks, including workflow builders and runtimes like Langflow.
|
||||
|
||||
[Langfuse](https://langfuse.com) ([GitHub](https://github.com/langfuse/langfuse)) is an open-source platform for LLM observability. It provides tracing and monitoring capabilities for AI applications, helping developers debug, analyze, and optimize their AI systems. Langfuse integrates with various tools and frameworks such as workflows builders like Langflow.
|
||||
|
||||
This guide walks you through how to configure Langflow to collect [tracing](https://langfuse.com/docs/tracing) data about your flow executions and automatically send the data to Langfuse.
|
||||
This guide explains how to configure Langflow to collect [tracing](https://langfuse.com/docs/tracing) data about your flow executions and automatically send the data to Langfuse.
|
||||
|
||||
<iframe width="760" height="415" src="https://www.youtube.com/embed/SA9gGbzwNGU?si=eDKvdtvhb3fJCSbl" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share" referrerpolicy="strict-origin-when-cross-origin" allowfullscreen></iframe>
|
||||
|
||||
## Prerequisites
|
||||
|
||||
- A project in Langflow with a runnable flow
|
||||
- A [Langfuse Cloud](https://cloud.langfuse.com) or [self-hosted Langfuse](https://langfuse.com/self-hosting) account
|
||||
- An account in a [Langfuse Cloud](https://cloud.langfuse.com) or [Langfuse self-hosted](https://langfuse.com/self-hosting) instance
|
||||
- A [running Langflow server](/get-started-installation) with a [flow](/concepts-flows) that you want to trace
|
||||
|
||||
## Set Langfuse credentials as environment variables
|
||||
:::tip
|
||||
If you need a flow to test the Langfuse integration, see the [Langflow quickstart](/get-started-quickstart).
|
||||
:::
|
||||
|
||||
1. In Langfuse, go to **Project Settings**, and then create a new set of API keys.
|
||||
## Set Langfuse credentials as environment variables {#langfuse-credentials}
|
||||
|
||||
1. Create a set of [Langfuse API keys](https://langfuse.com/faq/all/where-are-langfuse-api-keys).
|
||||
|
||||
2. Copy the following API key information:
|
||||
|
||||
- Secret Key
|
||||
- Public Key
|
||||
- Host URL
|
||||
- Secret Key
|
||||
- Public Key
|
||||
- Host URL
|
||||
|
||||
3. Set your Langfuse project credentials as environment variables in the same environment where you run Langflow.
|
||||
|
||||
The following examples set environment variables in a Linux or macOS terminal session or in a Windows command prompt session:
|
||||
Replace `SECRET_KEY`, `PUBLIC_KEY`, and `HOST_URL` with the API key information you copied from Langfuse.
|
||||
<Tabs>
|
||||
In the following examples, replace `SECRET_KEY`, `PUBLIC_KEY`, and `HOST_URL` with your API key details from Langfuse.
|
||||
|
||||
<TabItem value="linux-macos" label="Linux or macOS" default>
|
||||
```
|
||||
export LANGFUSE_SECRET_KEY=SECRET_KEY
|
||||
export LANGFUSE_PUBLIC_KEY=PUBLIC_KEY
|
||||
export LANGFUSE_HOST=HOST_URL
|
||||
```
|
||||
</TabItem>
|
||||
<Tabs>
|
||||
<TabItem value="linux-macos" label="Linux or macOS" default>
|
||||
|
||||
<TabItem value="windows" label="Windows" default>
|
||||
```
|
||||
set LANGFUSE_SECRET_KEY=SECRET_KEY
|
||||
set LANGFUSE_PUBLIC_KEY=PUBLIC_KEY
|
||||
set LANGFUSE_HOST=HOST_URL
|
||||
```
|
||||
</TabItem>
|
||||
These commands set the environment variables in a Linux or macOS terminal session:
|
||||
|
||||
</Tabs>
|
||||
```
|
||||
export LANGFUSE_SECRET_KEY=SECRET_KEY
|
||||
export LANGFUSE_PUBLIC_KEY=PUBLIC_KEY
|
||||
export LANGFUSE_HOST=HOST_URL
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="windows" label="Windows">
|
||||
|
||||
These commands set the environment variables in a Windows command prompt session:
|
||||
|
||||
```
|
||||
set LANGFUSE_SECRET_KEY=SECRET_KEY
|
||||
set LANGFUSE_PUBLIC_KEY=PUBLIC_KEY
|
||||
set LANGFUSE_HOST=HOST_URL
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
## Start Langflow and view traces in Langfuse
|
||||
|
||||
1. Start Langflow in the same terminal or environment where you set the environment variables:
|
||||
1. Start Langflow in the same environment where you set the Langfuse environment variables:
|
||||
|
||||
```bash
|
||||
uv run langflow run
|
||||
```
|
||||
```bash
|
||||
uv run langflow run
|
||||
```
|
||||
|
||||
2. In Langflow, open an existing project, and then run a flow.
|
||||
2. Run a flow.
|
||||
|
||||
Langflow automatically collects and sends tracing data about the flow execution to Langfuse.
|
||||
|
||||
3. View the collected data in your Langfuse project dashboard.
|
||||
3. View the collected data in your [Langfuse dashboard](https://langfuse.com/docs/analytics/overview).
|
||||
|
||||
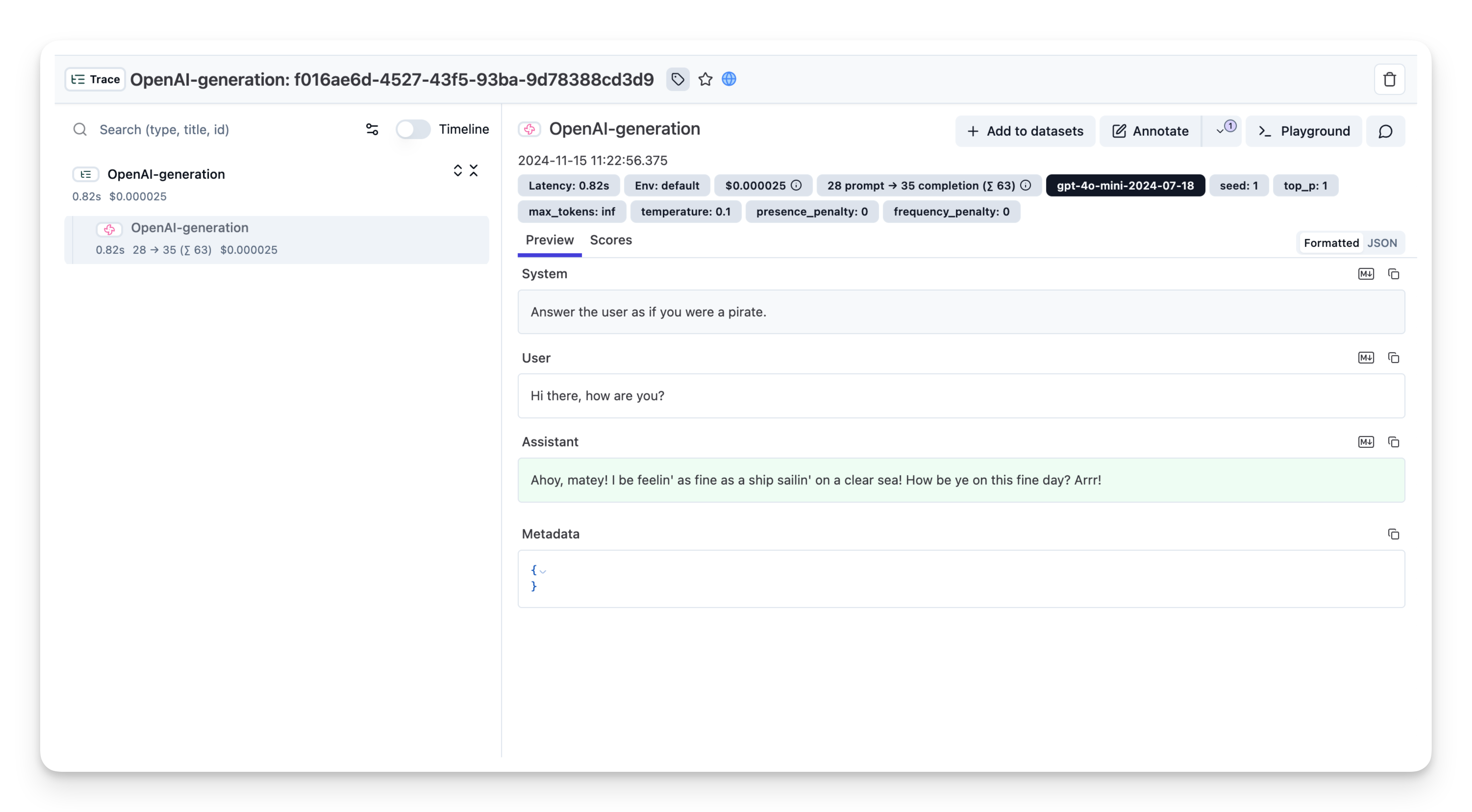
|
||||
Langfuse also provides a [public live trace example dashboard](https://cloud.langfuse.com/project/cm0nywmaa005c3ol2msoisiho/traces/f016ae6d-4527-43f5-93ba-9d78388cd3d9).
|
||||
|
||||
For a live public example trace in a Langfuse dashboard, see [Public example trace in Langfuse](https://cloud.langfuse.com/project/cm0nywmaa005c3ol2msoisiho/traces/f016ae6d-4527-43f5-93ba-9d78388cd3d9?timestamp=2024-11-15T10%3A22%3A56.378Z&observation=c3680212-31f0-46e2-9310-add4352e4cc7).
|
||||
## Disable Langfuse tracing
|
||||
|
||||
## Disable Langfuse Tracing
|
||||
|
||||
To disable the Langfuse integration, remove the environment variables you set in the previous steps and restart Langflow.
|
||||
To disable the Langfuse integration, remove the [Langfuse environment variables](#langfuse-credentials), and then restart Langflow.
|
||||
|
||||
## Run Langfuse and Langflow with Docker Compose
|
||||
|
||||
If you prefer to self-host Langfuse, you can run both services with Docker Compose.
|
||||
As an alternative to the previous setup, particularly for self-hosted Langfuse, you can run both services with Docker Compose.
|
||||
|
||||
1. In Langfuse, go to **Project Settings**, and then create a new set of API keys.
|
||||
1. Create a set of [Langfuse API keys](https://langfuse.com/faq/all/where-are-langfuse-api-keys).
|
||||
|
||||
2. Copy the following API key information:
|
||||
|
||||
- Secret Key
|
||||
- Public Key
|
||||
- Host URL
|
||||
- Secret Key
|
||||
- Public Key
|
||||
- Host URL
|
||||
|
||||
3. Add your Langflow credentials to your Langflow `docker-compose.yml` file in the `environment` section.
|
||||
|
||||
The following example is based on the [example `docker-compose.yml`](https://github.com/langflow-ai/langflow/blob/main/docker_example/docker-compose.yml).
|
||||
|
||||
```yml
|
||||
services:
|
||||
langflow:
|
||||
image: langflowai/langflow:latest # or another version tag on https://hub.docker.com/r/langflowai/langflow
|
||||
pull_policy: always # set to 'always' when using 'latest' image
|
||||
ports:
|
||||
- "7860:7860"
|
||||
depends_on:
|
||||
- postgres
|
||||
environment:
|
||||
- LANGFLOW_DATABASE_URL=postgresql://langflow:langflow@postgres:5432/langflow
|
||||
# This variable defines where the logs, file storage, monitor data and secret keys are stored.
|
||||
- LANGFLOW_CONFIG_DIR=app/langflow
|
||||
- LANGFUSE_SECRET_KEY=sk-...
|
||||
- LANGFUSE_PUBLIC_KEY=pk-...
|
||||
- LANGFUSE_HOST=https://us.cloud.langfuse.com
|
||||
volumes:
|
||||
- langflow-data:/app/langflow
|
||||
|
||||
postgres:
|
||||
image: postgres:16
|
||||
environment:
|
||||
POSTGRES_USER: langflow
|
||||
POSTGRES_PASSWORD: langflow
|
||||
POSTGRES_DB: langflow
|
||||
ports:
|
||||
- "5432:5432"
|
||||
volumes:
|
||||
- langflow-postgres:/var/lib/postgresql/data
|
||||
|
||||
3. Add your Langflow API keys to your `docker-compose.yml` file.
|
||||
An example [docker-compose.yml](https://github.com/langflow-ai/langflow/blob/main/docker_example/docker-compose.yml) file is available in the Langflow GitHub repo.
|
||||
```yml
|
||||
services:
|
||||
langflow:
|
||||
image: langflowai/langflow:latest # or another version tag on https://hub.docker.com/r/langflowai/langflow
|
||||
pull_policy: always # set to 'always' when using 'latest' image
|
||||
ports:
|
||||
- "7860:7860"
|
||||
depends_on:
|
||||
- postgres
|
||||
environment:
|
||||
- LANGFLOW_DATABASE_URL=postgresql://langflow:langflow@postgres:5432/langflow
|
||||
# This variable defines where the logs, file storage, monitor data and secret keys are stored.
|
||||
- LANGFLOW_CONFIG_DIR=app/langflow
|
||||
- LANGFUSE_SECRET_KEY=sk-...
|
||||
- LANGFUSE_PUBLIC_KEY=pk-...
|
||||
- LANGFUSE_HOST=https://us.cloud.langfuse.com
|
||||
volumes:
|
||||
- langflow-data:/app/langflow
|
||||
langflow-postgres:
|
||||
langflow-data:
|
||||
```
|
||||
|
||||
postgres:
|
||||
image: postgres:16
|
||||
environment:
|
||||
POSTGRES_USER: langflow
|
||||
POSTGRES_PASSWORD: langflow
|
||||
POSTGRES_DB: langflow
|
||||
ports:
|
||||
- "5432:5432"
|
||||
volumes:
|
||||
- langflow-postgres:/var/lib/postgresql/data
|
||||
4. Start the Docker container:
|
||||
|
||||
volumes:
|
||||
langflow-postgres:
|
||||
langflow-data:
|
||||
```
|
||||
```text
|
||||
docker-compose up
|
||||
```
|
||||
|
||||
4. Start the Docker container.
|
||||
```text
|
||||
docker-compose up
|
||||
```
|
||||
5. To confirm Langfuse is connected to your Langflow container, run this command.
|
||||
Ensure you've exported `LANGFLOW_HOST` as a variable in your terminal.
|
||||
```sh
|
||||
docker compose exec langflow python -c "import requests, os; addr = os.environ.get('LANGFUSE_HOST'); print(addr); res = requests.get(addr, timeout=5); print(res.status_code)"
|
||||
```
|
||||
5. To confirm Langfuse is connected to your Langflow container, run the following command:
|
||||
|
||||
An output similar to this indicates success:
|
||||
```text
|
||||
https://us.cloud.langfuse.com
|
||||
200
|
||||
```
|
||||
```sh
|
||||
docker compose exec langflow python -c "import requests, os; addr = os.environ.get('LANGFUSE_HOST'); print(addr); res = requests.get(addr, timeout=5); print(res.status_code)"
|
||||
```
|
||||
|
||||
If there is an error, make sure you have set the `LANGFUSE_HOST` environment variable in your terminal session.
|
||||
|
||||
Output similar to the following indicates success:
|
||||
|
||||
```text
|
||||
https://us.cloud.langfuse.com
|
||||
200
|
||||
```
|
||||
|
||||
## See also
|
||||
|
||||
* [Langfuse GitHub repository](https://github.com/langfuse/langfuse)
|
||||
|
|
@ -6,47 +6,49 @@ slug: /integrations-opik
|
|||
import Tabs from '@theme/Tabs';
|
||||
import TabItem from '@theme/TabItem';
|
||||
|
||||
# Integrate Opik with Langflow
|
||||
|
||||
[Opik](https://www.comet.com/site/products/opik/) is an open-source platform designed for evaluating, testing, and monitoring large language model (LLM) applications. Developed by Comet, it aims to facilitate more intuitive collaboration, testing, and monitoring of LLM-based applications.
|
||||
|
||||
This guide walks you through how to configure Langflow to collect [tracing](https://www.comet.com/docs/opik/tracing/log_traces) data about your flow executions and automatically send the data to Opik.
|
||||
You can configure Langflow to collect [tracing](https://www.comet.com/docs/opik/tracing/log_traces) data about your flow executions and automatically send the data to Opik.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
- A project in Langflow with a runnable flow
|
||||
- An Open-Source Opik server or an Opik Cloud account - You can learn more about the differences [here](https://www.comet.com/docs/opik/faq#what-is-the-difference-between-opik-cloud-and-the-open-source-opik-platform-)
|
||||
- If you are using Opik Cloud, you will also need your [Opik API key](https://www.comet.com/docs/opik/faq#where-can-i-find-my-opik-api-key-)
|
||||
- An [Open-Source Opik server or an Opik Cloud account](https://www.comet.com/docs/opik/faq#what-is-the-difference-between-opik-cloud-and-the-open-source-opik-platform-)
|
||||
- A [running Langflow server](/get-started-installation) with a [flow](/concepts-flows) that you want to trace
|
||||
|
||||
## Set your Opik configuration as environment variables
|
||||
:::tip
|
||||
If you need a flow to test the Opik integration, see the [Langflow quickstart](/get-started-quickstart).
|
||||
:::
|
||||
|
||||
Call the CLI `opik configure` to save your Opik configuration in the same environment where you run Langflow.
|
||||
## Integrate Opik with Langflow
|
||||
|
||||
```bash
|
||||
opik configure
|
||||
```
|
||||
1. If you use Opik Cloud, get an [Opik API key](https://www.comet.com/docs/opik/faq#where-can-i-find-my-opik-api-key-).
|
||||
|
||||
For self-hosted Opik, you can also configure it using the Opik CLI by running the following command:
|
||||
An API key isn't required with an Open-Source Opik server.
|
||||
|
||||
```bash
|
||||
opik configure --use_local
|
||||
```
|
||||
2. Call the `opik configure` CLI to save your Opik configuration in the same environment where you run Langflow:
|
||||
|
||||
See the [Opik documentation](https://www.comet.com/docs/opik/tracing/sdk_configuration) for more ways to configure Opik SDKs.
|
||||
```bash
|
||||
opik configure
|
||||
```
|
||||
|
||||
## Start Langflow and run a flow
|
||||
For self-hosted Opik, you can also use the following Opik CLI command:
|
||||
|
||||
1. Start Langflow in the same terminal or environment where you set the environment variables:
|
||||
```bash
|
||||
opik configure --use_local
|
||||
```
|
||||
|
||||
```bash
|
||||
uv run langflow run
|
||||
```
|
||||
For more information, see the [Opik SDK configuration documentation](https://www.comet.com/docs/opik/tracing/sdk_configuration).
|
||||
|
||||
2. In Langflow, open an existing project, and then run a flow.
|
||||
3. Start Langflow in the same terminal or environment where you set the environment variables:
|
||||
|
||||
```bash
|
||||
uv run langflow run
|
||||
```
|
||||
|
||||
3. Navigate to your Opik project dashboard and view the collected tracing data.
|
||||
4. In Langflow, run a flow to produce activity for Opik to trace.
|
||||
|
||||
5. Navigate to your Opik project dashboard and view the collected tracing data.
|
||||
|
||||
## Disable the Opik integration
|
||||
|
||||
To disable the Opik integration, remove the environment variables you set in the previous steps and restart Langflow.
|
||||
To disable the Opik integration, remove the environment variables you set with `opik configure`, and then restart Langflow.
|
||||
|
|
@ -23,11 +23,11 @@ If you still cannot locate the component, see [Langflow GitHub Issues and Discus
|
|||
|
||||
## No input in the Playground
|
||||
|
||||
If there is no message input field in the **Playground**, make sure your flow has a [**Chat Input** component](/components-io) that is connected, directly or indirectly, to the **Input** port of a **Language Model** or **Agent** component.
|
||||
If there is no message input field in the **Playground**, make sure your flow has a [**Chat Input** component](/components-io#chat-io) that is connected, directly or indirectly, to the **Input** port of a **Language Model** or **Agent** component.
|
||||
|
||||
Because the **Playground** is designed for flows that use an LLM in a query-and-response format, such as chatbots and agents, a flow must have **Chat Input**, **Language Model**/**Agent**, and **Chat Output** components to be fully supported by the **Playground**'s chat interface.
|
||||
|
||||
For more information, see [Use the **Playground**](/concepts-playground).
|
||||
For more information, see [Test flows in the **Playground**](/concepts-playground).
|
||||
|
||||
## Missing key, no key found, or invalid API key
|
||||
|
||||
|
|
|
|||
|
|
@ -319,9 +319,17 @@ const config = {
|
|||
from: "/embedded-chat-widget",
|
||||
},
|
||||
{
|
||||
to: "/components-data",
|
||||
to: "/bundles-google",
|
||||
from: "/integrations-setup-google-oauth-langflow",
|
||||
},
|
||||
{
|
||||
to: "/bundles-vertexai",
|
||||
from: "/integrations-setup-google-cloud-vertex-ai-langflow",
|
||||
},
|
||||
{
|
||||
to: "/develop-application",
|
||||
from: "/develop-overview",
|
||||
},
|
||||
{
|
||||
to: "/data-types",
|
||||
from: "/concepts-objects",
|
||||
|
|
|
|||
490
docs/sidebars.js
490
docs/sidebars.js
|
|
@ -32,21 +32,6 @@ module.exports = {
|
|||
},
|
||||
],
|
||||
},
|
||||
{
|
||||
type: "category",
|
||||
label: "Templates",
|
||||
items: [
|
||||
'Templates/basic-prompting',
|
||||
'Templates/simple-agent',
|
||||
'Templates/blog-writer',
|
||||
'Templates/document-qa',
|
||||
'Templates/memory-chatbot',
|
||||
'Templates/vector-store-rag',
|
||||
'Templates/financial-report-parser',
|
||||
'Templates/sequential-agent',
|
||||
'Templates/travel-planning-agent',
|
||||
],
|
||||
},
|
||||
{
|
||||
type: "category",
|
||||
label: "Flows",
|
||||
|
|
@ -61,62 +46,52 @@ module.exports = {
|
|||
id: "Concepts/concepts-flows",
|
||||
label: "Build flows"
|
||||
},
|
||||
{
|
||||
type: "category",
|
||||
label: "Flow templates",
|
||||
items: [
|
||||
'Templates/basic-prompting',
|
||||
'Templates/simple-agent',
|
||||
'Templates/blog-writer',
|
||||
'Templates/document-qa',
|
||||
'Templates/memory-chatbot',
|
||||
'Templates/vector-store-rag',
|
||||
'Templates/financial-report-parser',
|
||||
'Templates/sequential-agent',
|
||||
'Templates/travel-planning-agent',
|
||||
],
|
||||
},
|
||||
{
|
||||
type: "category",
|
||||
label: "Run flows",
|
||||
items: [
|
||||
{
|
||||
type: "doc",
|
||||
id: "Concepts/concepts-publish",
|
||||
label: "Trigger flows with the Langflow API"
|
||||
},
|
||||
{
|
||||
type: "doc",
|
||||
id: "Develop/webhook",
|
||||
label: "Trigger flows with webhooks"
|
||||
},
|
||||
],
|
||||
},
|
||||
{
|
||||
type: "doc",
|
||||
id: "Concepts/concepts-publish",
|
||||
label: "Run flows"
|
||||
id: "Concepts/concepts-playground",
|
||||
label: "Test flows"
|
||||
},
|
||||
{
|
||||
type: "doc",
|
||||
id: "Concepts/concepts-flows-import",
|
||||
label: "Import and export flows"
|
||||
},
|
||||
{
|
||||
type: "doc",
|
||||
id: "Concepts/concepts-playground",
|
||||
label: "Use the Playground"
|
||||
},
|
||||
{
|
||||
type: "doc",
|
||||
id: "Concepts/concepts-voice-mode",
|
||||
label: "Use voice mode"
|
||||
},
|
||||
{
|
||||
type: "doc",
|
||||
id: "Concepts/data-types",
|
||||
label: "Langflow data types"
|
||||
},
|
||||
{
|
||||
type: "doc",
|
||||
id: "Concepts/concepts-file-management",
|
||||
label: "Manage files"
|
||||
},
|
||||
],
|
||||
},
|
||||
{
|
||||
type: "category",
|
||||
label: "Components",
|
||||
items: [
|
||||
"Concepts/concepts-components",
|
||||
"Components/components-agents",
|
||||
"Components/components-bundles",
|
||||
"Components/components-custom-components",
|
||||
"Components/components-data",
|
||||
"Components/components-embedding-models",
|
||||
"Components/components-helpers",
|
||||
"Components/components-io",
|
||||
"Components/components-logic",
|
||||
"Components/components-memories",
|
||||
"Components/components-models",
|
||||
"Components/components-processing",
|
||||
"Components/components-prompts",
|
||||
"Components/components-tools",
|
||||
"Components/components-vector-stores",
|
||||
],
|
||||
},
|
||||
{
|
||||
type: "category",
|
||||
label: "Agents",
|
||||
label: "Agents and MCP",
|
||||
items: [
|
||||
"Agents/agents",
|
||||
"Agents/agents-tools",
|
||||
|
|
@ -126,88 +101,84 @@ module.exports = {
|
|||
type: "category",
|
||||
label: "Model Context Protocol (MCP)",
|
||||
items: [
|
||||
"Concepts/mcp-server",
|
||||
"Components/mcp-client",
|
||||
],
|
||||
},
|
||||
{
|
||||
type: "category",
|
||||
label: "Configuration",
|
||||
items: [
|
||||
"Configuration/configuration-api-keys",
|
||||
"Configuration/configuration-authentication",
|
||||
"Configuration/configuration-cli",
|
||||
"Configuration/configuration-custom-database",
|
||||
"Configuration/configuration-global-variables",
|
||||
"Configuration/environment-variables",
|
||||
"Contributing/contributing-telemetry",
|
||||
"Concepts/mcp-server",
|
||||
"Integrations/mcp-component-astra",
|
||||
],
|
||||
},
|
||||
{
|
||||
type: "category",
|
||||
label: "Develop",
|
||||
items: [
|
||||
{
|
||||
type: "doc",
|
||||
id: "Develop/develop-overview",
|
||||
label: "Overview"
|
||||
},
|
||||
{
|
||||
type: "doc",
|
||||
id: "Develop/develop-application",
|
||||
label: "Develop an application in Langflow"
|
||||
},
|
||||
{
|
||||
type: "doc",
|
||||
id: "Develop/install-custom-dependencies",
|
||||
label: "Install custom dependencies"
|
||||
},
|
||||
{
|
||||
type: "doc",
|
||||
id: "Develop/memory",
|
||||
label: "Memory management"
|
||||
},
|
||||
{
|
||||
type: "doc",
|
||||
id: "Develop/session-id",
|
||||
label: "Session ID"
|
||||
},
|
||||
{
|
||||
type: "doc",
|
||||
id: "Develop/logging",
|
||||
label: "Logging"
|
||||
},
|
||||
{
|
||||
type: "doc",
|
||||
id: "Develop/webhook",
|
||||
label: "Webhook"
|
||||
},
|
||||
"Configuration/configuration-api-keys",
|
||||
"Configuration/configuration-authentication",
|
||||
"Configuration/configuration-global-variables",
|
||||
"Configuration/environment-variables",
|
||||
{
|
||||
type: "category",
|
||||
label: "Clients",
|
||||
label: "Storage and memory",
|
||||
items: [
|
||||
{
|
||||
type: "doc",
|
||||
id: "Develop/Clients/typescript-client",
|
||||
label: "TypeScript Client"
|
||||
}
|
||||
]
|
||||
id: "Concepts/concepts-file-management",
|
||||
label: "Manage files"
|
||||
},
|
||||
{
|
||||
type: "doc",
|
||||
id: "Develop/memory",
|
||||
label: "Manage memory"
|
||||
},
|
||||
{
|
||||
type: "doc",
|
||||
id: "Develop/session-id",
|
||||
label: "Use Session IDs"
|
||||
},
|
||||
"Configuration/configuration-custom-database",
|
||||
],
|
||||
},
|
||||
{
|
||||
type: "category",
|
||||
label: "Observability",
|
||||
items: [
|
||||
"Develop/logging",
|
||||
"Integrations/Arize/integrations-arize",
|
||||
"Integrations/integrations-langfuse",
|
||||
"Integrations/integrations-langsmith",
|
||||
"Integrations/integrations-langwatch",
|
||||
"Integrations/integrations-opik",
|
||||
"Contributing/contributing-telemetry",
|
||||
],
|
||||
},
|
||||
{
|
||||
type: "doc",
|
||||
id: "Concepts/data-types",
|
||||
label: "Use Langflow data types"
|
||||
},
|
||||
{
|
||||
type: "doc",
|
||||
id: "Concepts/concepts-voice-mode",
|
||||
label: "Use voice mode"
|
||||
},
|
||||
{
|
||||
type: "doc",
|
||||
id: "Configuration/configuration-cli",
|
||||
label: "Use the Langflow CLI"
|
||||
},
|
||||
],
|
||||
},
|
||||
{
|
||||
type: "category",
|
||||
label: "Deployment",
|
||||
label: "Deploy",
|
||||
items: [
|
||||
{
|
||||
type:"doc",
|
||||
id: "Deployment/deployment-overview",
|
||||
label: "Deployment overview"
|
||||
},
|
||||
{
|
||||
type: "doc",
|
||||
id: "Deployment/deployment-docker",
|
||||
label: "Docker"
|
||||
label: "Langflow deployment overview"
|
||||
},
|
||||
{
|
||||
type: "doc",
|
||||
|
|
@ -215,51 +186,186 @@ module.exports = {
|
|||
label: "Deploy a public Langflow server"
|
||||
},
|
||||
{
|
||||
type: "doc",
|
||||
id: "Deployment/deployment-caddyfile",
|
||||
label: "Deploy Langflow on a remote server"
|
||||
type: "category",
|
||||
label: "Containerized deployments",
|
||||
items: [
|
||||
"Develop/develop-application",
|
||||
{
|
||||
type: "doc",
|
||||
id: "Deployment/deployment-docker",
|
||||
label: "Langflow Docker images"
|
||||
},
|
||||
{
|
||||
type: "doc",
|
||||
id: "Deployment/deployment-caddyfile",
|
||||
label: "Deploy Langflow on a remote server"
|
||||
},
|
||||
{
|
||||
type: "category",
|
||||
label: "Kubernetes",
|
||||
items: [
|
||||
{
|
||||
type: "doc",
|
||||
id: "Deployment/deployment-prod-best-practices",
|
||||
label: "Langflow architecture and best practices"
|
||||
},
|
||||
{
|
||||
type: "doc",
|
||||
id: "Deployment/deployment-kubernetes-dev",
|
||||
label: "Deploy in development"
|
||||
},
|
||||
{
|
||||
type: "doc",
|
||||
id: "Deployment/deployment-kubernetes-prod",
|
||||
label: "Deploy in production"
|
||||
}
|
||||
]
|
||||
},
|
||||
{
|
||||
type: "doc",
|
||||
id: "Deployment/deployment-gcp",
|
||||
label: "Google Cloud Platform"
|
||||
},
|
||||
{
|
||||
type: "doc",
|
||||
id: "Deployment/deployment-hugging-face-spaces",
|
||||
label: "Hugging Face Spaces"
|
||||
},
|
||||
{
|
||||
type: "doc",
|
||||
id: "Deployment/deployment-railway",
|
||||
label: "Railway"
|
||||
},
|
||||
{
|
||||
type: "doc",
|
||||
id: "Deployment/deployment-render",
|
||||
label: "Render"
|
||||
},
|
||||
],
|
||||
},
|
||||
],
|
||||
},
|
||||
{
|
||||
type: "category",
|
||||
label: "Components reference",
|
||||
items: [
|
||||
"Concepts/concepts-components",
|
||||
{
|
||||
type: "category",
|
||||
label: "Core components",
|
||||
items: [
|
||||
"Components/components-io",
|
||||
"Components/components-agents",
|
||||
{
|
||||
type: "category",
|
||||
label: "Models",
|
||||
items: [
|
||||
"Components/components-models",
|
||||
"Components/components-embedding-models",
|
||||
]
|
||||
},
|
||||
"Components/components-data",
|
||||
"Components/components-vector-stores",
|
||||
{
|
||||
type: "category",
|
||||
label: "Processing",
|
||||
items: [
|
||||
"Components/components-processing",
|
||||
"Components/components-prompts",
|
||||
]
|
||||
},
|
||||
"Components/components-logic",
|
||||
"Components/components-helpers",
|
||||
"Components/components-tools",
|
||||
"Components/components-memories",
|
||||
],
|
||||
},
|
||||
{
|
||||
type: "category",
|
||||
label: "Kubernetes",
|
||||
label: "Bundles",
|
||||
items: [
|
||||
"Components/components-bundles",
|
||||
"Components/bundles-aiml",
|
||||
"Components/bundles-amazon",
|
||||
"Components/bundles-anthropic",
|
||||
"Integrations/Apify/integrations-apify",
|
||||
"Components/bundles-arxiv",
|
||||
"Integrations/integrations-assemblyai",
|
||||
"Components/bundles-azure",
|
||||
"Components/bundles-baidu",
|
||||
"Components/bundles-bing",
|
||||
"Integrations/Cleanlab/integrations-cleanlab",
|
||||
"Components/bundles-cloudflare",
|
||||
"Components/bundles-cohere",
|
||||
"Integrations/Composio/integrations-composio",
|
||||
"Components/bundles-datastax",
|
||||
"Components/bundles-deepseek",
|
||||
"Integrations/Docling/integrations-docling",
|
||||
"Components/bundles-duckduckgo",
|
||||
"Components/bundles-exa",
|
||||
"Components/bundles-glean",
|
||||
{
|
||||
type: "doc",
|
||||
id: "Deployment/deployment-prod-best-practices",
|
||||
label: "Langflow architecture and best practices"
|
||||
type: 'category',
|
||||
label: 'Google',
|
||||
items: [
|
||||
"Components/bundles-google",
|
||||
"Integrations/Google/integrations-google-big-query",
|
||||
],
|
||||
},
|
||||
"Components/bundles-groq",
|
||||
"Components/bundles-huggingface",
|
||||
"Components/bundles-ibm",
|
||||
"Components/bundles-icosacomputing",
|
||||
"Components/bundles-langchain",
|
||||
"Components/bundles-lmstudio",
|
||||
"Components/bundles-maritalk",
|
||||
"Components/bundles-mem0",
|
||||
"Components/bundles-mistralai",
|
||||
{
|
||||
type: "doc",
|
||||
id: "Deployment/deployment-kubernetes-dev",
|
||||
label: "Deploy in development"
|
||||
type: "category",
|
||||
label: "Notion",
|
||||
items: [
|
||||
"Integrations/Notion/integrations-notion",
|
||||
"Integrations/Notion/notion-agent-conversational",
|
||||
"Integrations/Notion/notion-agent-meeting-notes",
|
||||
],
|
||||
},
|
||||
"Components/bundles-novita",
|
||||
{
|
||||
type: "doc",
|
||||
id: "Deployment/deployment-kubernetes-prod",
|
||||
label: "Deploy in production"
|
||||
}
|
||||
]
|
||||
},
|
||||
{
|
||||
type: "doc",
|
||||
id: "Deployment/deployment-gcp",
|
||||
label: "Google Cloud Platform"
|
||||
},
|
||||
{
|
||||
type: "doc",
|
||||
id: "Deployment/deployment-hugging-face-spaces",
|
||||
label: "Hugging Face Spaces"
|
||||
},
|
||||
{
|
||||
type: "doc",
|
||||
id: "Deployment/deployment-railway",
|
||||
label: "Railway"
|
||||
},
|
||||
{
|
||||
type: "doc",
|
||||
id: "Deployment/deployment-render",
|
||||
label: "Render"
|
||||
type: "category",
|
||||
label: "NVIDIA",
|
||||
items: [
|
||||
"Components/bundles-nvidia",
|
||||
{
|
||||
type: "doc",
|
||||
id: "Integrations/Nvidia/integrations-nvidia-ingest",
|
||||
label: "NVIDIA Ingest"
|
||||
},
|
||||
{
|
||||
type: "doc",
|
||||
id: "Integrations/Nvidia/integrations-nvidia-nim-wsl2",
|
||||
label: "NVIDIA NIM on WSL2"
|
||||
},
|
||||
{
|
||||
type: "doc",
|
||||
id: "Integrations/Nvidia/integrations-nvidia-g-assist",
|
||||
label: "NVIDIA G-Assist"
|
||||
},
|
||||
],
|
||||
},
|
||||
"Components/bundles-ollama",
|
||||
"Components/bundles-openai",
|
||||
"Components/bundles-openrouter",
|
||||
"Components/bundles-perplexity",
|
||||
"Components/bundles-redis",
|
||||
"Components/bundles-sambanova",
|
||||
"Components/bundles-searchapi",
|
||||
"Components/bundles-vertexai",
|
||||
"Components/bundles-wikipedia",
|
||||
"Components/bundles-xai",
|
||||
],
|
||||
},
|
||||
"Components/components-custom-components",
|
||||
],
|
||||
},
|
||||
{
|
||||
|
|
@ -271,6 +377,11 @@ module.exports = {
|
|||
id: "API-Reference/api-reference-api-examples",
|
||||
label: "Get started with the Langflow API",
|
||||
},
|
||||
{
|
||||
type: "doc",
|
||||
id: "Develop/Clients/typescript-client",
|
||||
label: "Use the TypeScript client"
|
||||
},
|
||||
{
|
||||
type: "doc",
|
||||
id: "API-Reference/api-flows-run",
|
||||
|
|
@ -318,85 +429,6 @@ module.exports = {
|
|||
},
|
||||
],
|
||||
},
|
||||
{
|
||||
type: "category",
|
||||
label: "Integrations",
|
||||
items: [
|
||||
"Integrations/Apify/integrations-apify",
|
||||
{
|
||||
type: "doc",
|
||||
id: "Integrations/Arize/integrations-arize",
|
||||
label: "Arize",
|
||||
},
|
||||
{
|
||||
type: "doc",
|
||||
id: "Integrations/integrations-assemblyai",
|
||||
label: "AssemblyAI",
|
||||
},
|
||||
{
|
||||
type: "doc",
|
||||
id: "Integrations/mcp-component-astra",
|
||||
label: "Astra DB MCP server",
|
||||
},
|
||||
{
|
||||
type: "doc",
|
||||
id: "Integrations/Cleanlab/integrations-cleanlab",
|
||||
label: "Cleanlab",
|
||||
},
|
||||
{
|
||||
type: "doc",
|
||||
id: "Integrations/Composio/integrations-composio",
|
||||
label: "Composio",
|
||||
},
|
||||
{
|
||||
type: "doc",
|
||||
id: "Integrations/Docling/integrations-docling",
|
||||
label: "Docling",
|
||||
},
|
||||
{
|
||||
type: 'category',
|
||||
label: 'Google',
|
||||
items: [
|
||||
'Integrations/Google/integrations-setup-google-cloud-vertex-ai-langflow',
|
||||
'Integrations/Google/integrations-google-big-query',
|
||||
],
|
||||
},
|
||||
"Integrations/integrations-langfuse",
|
||||
"Integrations/integrations-langsmith",
|
||||
"Integrations/integrations-langwatch",
|
||||
"Integrations/integrations-opik",
|
||||
{
|
||||
type: "category",
|
||||
label: "Notion",
|
||||
items: [
|
||||
"Integrations/Notion/integrations-notion",
|
||||
"Integrations/Notion/notion-agent-conversational",
|
||||
"Integrations/Notion/notion-agent-meeting-notes",
|
||||
],
|
||||
},
|
||||
{
|
||||
type: "category",
|
||||
label: "NVIDIA",
|
||||
items: [
|
||||
{
|
||||
type: "doc",
|
||||
id: "Integrations/Nvidia/integrations-nvidia-ingest",
|
||||
label: "NVIDIA Ingest"
|
||||
},
|
||||
{
|
||||
type: "doc",
|
||||
id: "Integrations/Nvidia/integrations-nvidia-nim-wsl2",
|
||||
label: "NVIDIA NIM on WSL2"
|
||||
},
|
||||
{
|
||||
type: "doc",
|
||||
id: "Integrations/Nvidia/integrations-nvidia-g-assist",
|
||||
label: "NVIDIA G-Assist"
|
||||
},
|
||||
],
|
||||
},
|
||||
],
|
||||
},
|
||||
{
|
||||
type: "category",
|
||||
label: "Contribute",
|
||||
|
|
|
|||
Loading…
Add table
Add a link
Reference in a new issue